标签:多维数组 pre 连接 数据结构 editor cee pytho 因此 str
在Python简单网络爬虫实战—下载论文名称,作者信息(上)中,学会了get到网页内容以及在谷歌浏览器找到了需要提取的内容的数据结构,接下来记录我是如何找到所有author和title的
1.从soup中get到data类
soup中提供了select方法来筛选所需的类。该方法使用方法如下:
articlename = soup.select(‘title‘)
该语句即将soup中所有的title元素放到articlename中。select也有其他用法
articlename = soup.select(‘.data‘) #类前面要加"." articlename = soup.select(‘#username‘)#ID这种唯一的元素,前加"#" articlename = soup.select(‘.publ-list .entry.editor .data‘)#可以组合查找,publ-list类下面的entry.editor类下面的data类,按次序用空格隔开 articlename = soup.select(‘.publ-list .entry.editor .data .title‘)[0].contents[0]#title类中第一个元素的第一个文本内容
我们用如下语句get到该网页中所有的data类,这样就包含了所有的author和title,去除了网页中其他无关的元素,离目标更近了一步
soup.select(‘.publ-list .entry.inproceedings .data‘)
2.data类中筛选所有author与title
这是一个data类的所有内容。
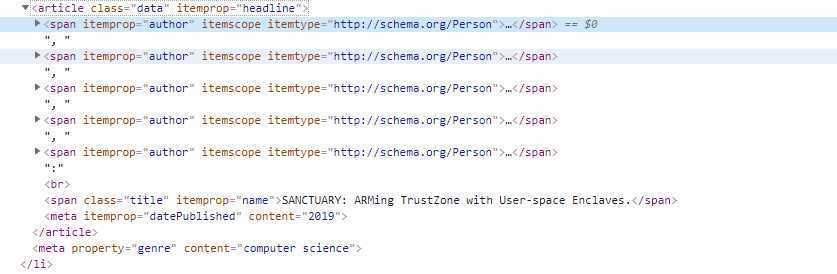
其中author元素还有更下一级的结构

可以看到,一个data类中author和title元素并不是紧密连接的,在每个authro行之间,有“,”和“:”行隔开,在title行下方,还有dataPublished、genre等元素,但下方的元素都是固定的,行数也固定。因此我把一个.data描述为如下的多维数组:
[ [author1,url,name ] ["," ] [author2,url,name ] [":" ] [<br> ] [title,name ] ["datePublished",content] [</article> ] ]
由于作者数量不固定,因此还要计算作者数量。因为每个author元素后面都会跟一个标点符号,因此似乎只要计算data类的长度减去4,再除以2就可以得到作者数量,然而在实际操作中发现,应该减去5。直到现在我也没有明白原因,可能这里需要补充HTML网站相关的知识。
authornum = int((len(articles)-5)/2)
得到了作者数量,就很容易定位到作者所在的行(下标)和title所在的行(下标)
观察元素内容可以看到,authorname和titlename都是唯一的文本,用以下命令获取即可
for i in range(0,authornum): authorlist.append(str(articles.contents[i*2].get_text())) articlename = str(articles.contents[(authornum+1)*2].get_text())
至此,该脚本的所有难点都搞定啦,接下来就水到渠成,理一下逻辑就ok啦
标签:多维数组 pre 连接 数据结构 editor cee pytho 因此 str
原文地址:https://www.cnblogs.com/masonmei/p/11537895.html