标签:sum 使用 excel 之间 数据 and 加载 shape class
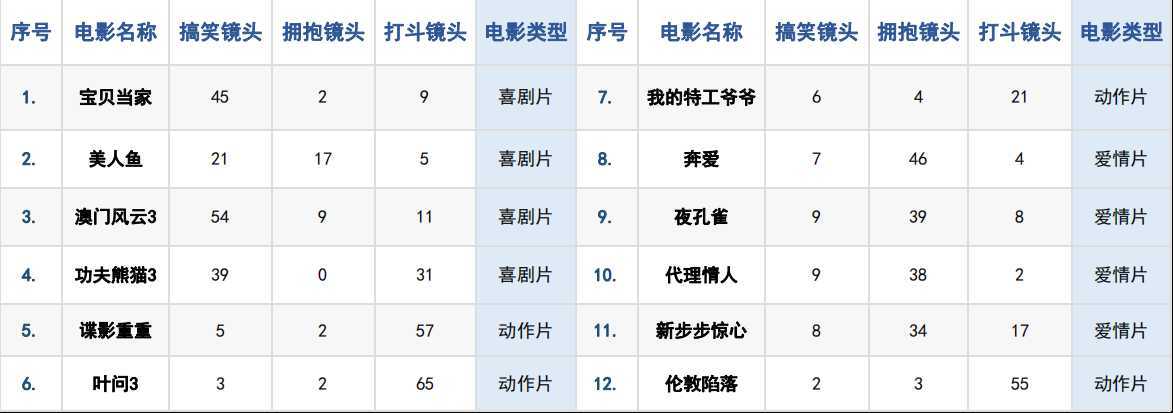
import pandas as pd import numpy as np def distance(v1, v2): """ 距离计算 :param v1:点1 :param v2: 点2 :return: 距离 """ dist = np.sqrt(np.sum(np.power((v1 - v2), 2))) return dist # 加载数据 data = pd.read_excel("./电影分类数据.xlsx") print("data:\n", data) print("*" * 80) # 获取训练集 train = data.iloc[:, :6] print("train:\n", train) # 获取训练集的特征值 与目标值 train_x = train.iloc[:, :-1] train_y = train.iloc[:, -1] # 获取测试集 print("*" * 80) test = data.columns[-4:] print("test:\n", test) # 进行计算距离 # 循环计算训练集每一个样本与测试集的距离 for i in range(train.shape[0]): # 计算距离 dist = distance(train_x.iloc[i,2:5],test[1:]) train.loc[i,‘dist‘] = dist print(train) # 对距离按照升序进行排序 train.sort_values(by=‘dist‘,inplace=True) print("*" * 80) print("排序后的train:\n",train) # 确定K 值 k值不同结果不同 k =5 res = train.loc[:,‘电影类型‘][:k].mode()[0] print("*" * 80) print(res)
标签:sum 使用 excel 之间 数据 and 加载 shape class
原文地址:https://www.cnblogs.com/wutanghua/p/11546214.html