标签:方式 key 升级 思考 提高 相关 博客 设定 新版
? 上一篇内容说到了MySQL存储引擎的相关内容,及数据类型的选择优化。下面再来说说索引的内容,包括对B-Tree和B+Tree两者的区别。
? 索引是存储引擎用于快速找到记录的一种数据结构, 对性能的提升有很大的帮助,尤其当表中数量较大的情况下,索引正确的使用可以对性能提升几个数量级。
但是索引经常被忽略,不恰当的索引对性能可能还会带来负面效果。
主键自动建立主键索引(唯一索引)
where字句中的列,频繁作为查询字段的列
表连接关联的列
排序用到的列
索引的基数越大(选择性大),索引的效率就越高
什么叫基数越大,比如手机号,每个列都具有不同的值,非常好区别,这个就适合建立索引,而性别这样的字段,因为只有两个值,以不适合建立索引,就是区分度高低的问题。
? 单值索引:即一个索引只包含单个列,一个表可以有多个单列索引。
? 唯一索引:索引列的值必须唯一,但是允许有空值。
? 复合索引:即一个索引包含多个列。
? 全文索引:使用fulltext创建全文索引。
在旧版MySQL中全文索引只能用在MyISAM表格的char、varchar和text的字段上。新版的MySQL5.6.24上InnoDB引擎也加入了全文索引。
? 使用方式:
具体使用方式这里就不详细说明,接下来就说说关于索引的实现原理,Tree,B-Tree,B+Tree。
? 在总结B-Tree和B+Tree之前,先看看最基本的二叉树结构吧,因为前两种树结构够可以算是二叉树的变种。
? 二叉树是n(n>=0)个结点的有限集合,该集合或者为空集(称为空二叉树),或者由一个根结点和两棵互不相交的、分别称为根结点的左子树和右子树组成。
? 二叉树的特点:
? 因此对于较平衡的二叉树的查找性能,是几乎接近于二分查找的,但是如果存入的数据都比根节点小,或者都比根节点大,则会出现以下情况。
? 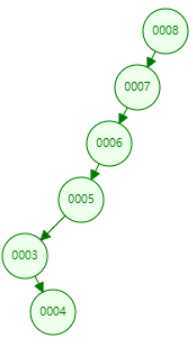
? 这两种情况分别是左斜树和右斜树,上述情况毫无疑问在二叉树搜索时,效率是非常低的。因为它已经失去了树的结构,不管是查询节点,还是添加删除等,都是对每个节点依次遍历,直到查出目标节点为止。
? 另外还有一点也是很重要,如果二叉树的字节点或多,一百万,一千万,甚至上亿数据。对于较大数据量的二叉树,会将其保存在磁盘中,那么问题来了。如果要查询的数据在树的底层,那么就势必会造成多次的磁盘IO,而磁盘IO的读取比内存读取的速度要低100倍左右。这种情况下,不管是从性能来说,还是效率这都不是一个好的结果。
? 接着再说B-Tree结构,是二叉树的一种升级版。
? B树又被成为平衡多路查找树。
? 在B-Tree或者B+Tree中,都会存在一个关于度的概念,也就是上面提到的m值。什么是度,可以说是我们自定义的一个阈值,当节点数量达到这个阈值时,树的结构便会发生变化,此时便转变成B-Tree结构。
? 现在,设定度(m)为3,首先我们先插入两个节点:
? 
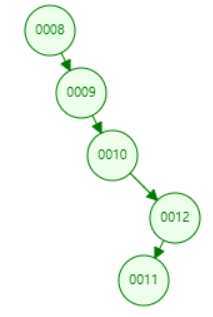
? 发现在B树结构中,当插入9节点时,并没有成为8节点的右子树,这是为什么。首先在于这就是B树的结构特点,没有成为8节点的右子树是不是就减少了树的层级深度。其次就是我们设定B树的度为3,接着将再添加10节点,看有什么变化。
? 
? 这个时候已经达到最大值3,那么根据二叉树的结构特点,将9提升为根节点,8和10分别为9的左右子节点。
? 继续添加6
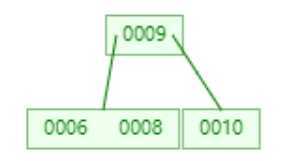
? 添加11
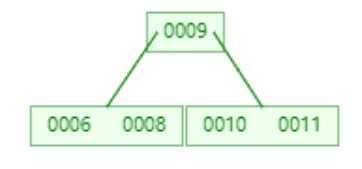
? 添加15
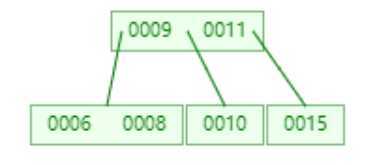
? 分析:
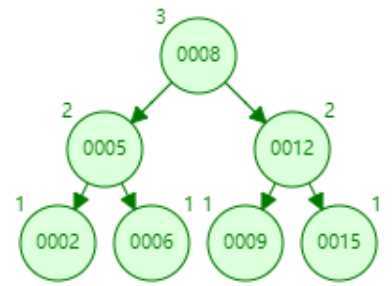
? 1,当添加11完成时,叶子节点全部都达到了度为2,而添加15时,由于比根节点9大,所以添加到右子树中。则右子树变成0010,0011,0015。显然达到我们设定的阈值,根据以上规则,将0011提升为根节点。
? 2,从图中可以看出,9的左边都是比根节点小,9到11之间都是大于9小于11的,最后11的右边都是大于11的。
? 3,最后我们再添加5,我们先来分析下结构会如何变化,5小于9,所以会在左边,变成005,006,008,这个时候节点数量变成3,根据规则006应该提升为根节点。但是根节点又会变成006,009,0011,同样达到阈值,那么将009再提升为根节点。最终结果如图:
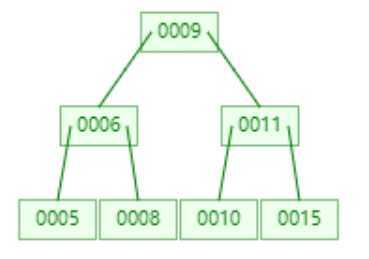
? 以上就是B-Tree的原理总结,那么这与二叉树有什么区别呢。最直观的就是树的层级变少了,同样也不会出现左右斜树的情况。
在InnoDB存储引擎中有页(Page)的概念,页就是磁盘管理的最小单位。InnoDB存储引擎中默认每个页的大小为16KB。并且可通过参数innodb_page_size将页的大小设置为4K、8K、16K。
? 
? 在B-Tree中,每个节点都会携带一个key信息,用于保存该数据在表中的位置,同时也会将数据保存到节点中。当节点不是叶子节点时,父节点会携带对象的指针指向其子节点在磁盘中的位置。根据磁盘存储的页大小,如果每个叶子节点都携带较多的信息,那么在磁盘中占用的空间资源也会越多。显然这不是一个好的现象,因此就出现B-Tree的优化版,B+Tree。
? InnoDB存储引擎就是用B+Tree实现其索引结构。
? 在B+Tree结构中,每一层非叶子节点只存储key值信息,而叶子节点只存放数据信息。这种结构不仅节省磁盘的空间,对节点的查询效率也大大提高了很多。
? 除此之外,非叶子节点的key最终会全部出现在叶子节点上, 这么说很抽象,请看演示效果。
? 首先添加7,8两个节点。
? 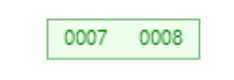
? 接着添加9节点。
? 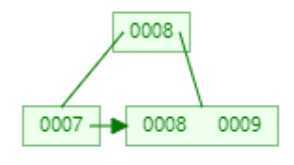
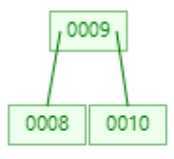
? 同样度达到了3,将8提升为根节点。但是与B-Tree不同的是,在叶子节点中也存在8节点,这就是B+Tree结构的特点,然后再添加10节点。
? 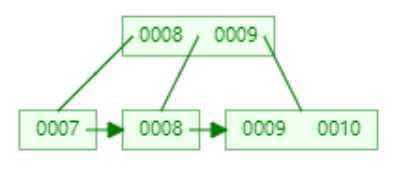
? 以此类推,在最后的叶子节点中,整个树中的key都在存在,那么这与B-Tree有什么区别呢。每个节点中没有数据存储,只有key值信息,在磁盘中会存储更多的数据。
? 思考一个问题:
? 对于查询效率最快的数据结构,哈希表的效率要比树状结构快的多,那么MySQL存储引擎为什么不采用哈希表结构存储数据,原因就是哈希表是不能进行范围查找。
? 本篇博客并没有讲述对索引使用的优化,只系统阐述了MySQL索引的底层机制,那么使用索引优化,查询优化,库表结构优化会在最后一篇博客中全部分享完。
? 以上内容均是自主学习总结,如有错误欢迎留言指正。
感谢阅读!
标签:方式 key 升级 思考 提高 相关 博客 设定 新版
原文地址:https://www.cnblogs.com/fenjyang/p/11559622.html