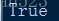标签:对象 两种 pytho box details alt blog nbsp 字符串
假设读者已经了解了什么叫字符集,什么叫编码,什么叫解码。
首先要明确,虽然有三种前缀(无前缀,前缀u,前缀b),但是字符串的类型只有两种(str,bytes),实验如下:

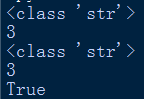

根据程序以及以上运行结果,发现无前缀,和前缀u,构造出来的字符串常量,是一样的。
类型一样是str,长度一样是3,==判断也是返回true。is判断也是返回true。
其实,这里是因为,python3中,字符串的存储方式都是以Unicode字符来存储的,所以前缀带不带u,其实都一样。
结论:字符串常量,前缀带不带u,都是一样的。
不管是utf-8,还是gbk,都可以理解为一种对应关系(若干个十六进制数<——>某个字符):
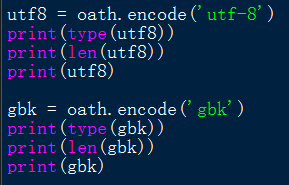
所以可以发现任何str类型的字符串,在经过encode(‘utf-8‘)后,就是通过utf-8这种编码解码方式(两种方向),将Unicode字符转换为对应的以字节方式存储的若干十六进制数。
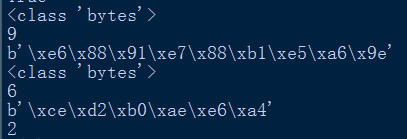
根据如上程序以及结果,可以发现,utf-8用三个十六进制来表示一个中文字符,而gbk用二个十六进制来表示一个中文字符。
结论:encode()函数根据括号内的编码方式,把str类型的字符串转换为bytes字符串,字符对应的若干十六进制数,根据编码方式决定。
既然知道了,str实际存储的是Unicode字符,那么也可以Unicode编码来存储str,形如\u1234:
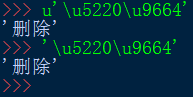
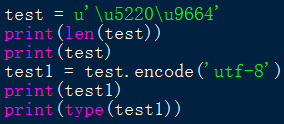
结论:str类型的字符串,每个字符用字符本身或者\u1234,来表示都可以,后者则是直接是Unicode编码。但打印时都是打印字符本身。
bytes字符串的组成形式,必须是十六进制数,或者ASCII字符:
提示错误:bytes只能包含ASCII字符。
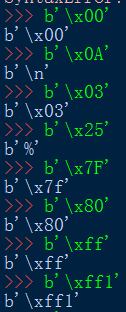
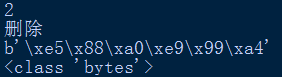
还可以对bytes取索引,所以这里bytes也可以用for循环来迭代了,因为也是可迭代对象。
取索引,将所在元素的数,转换为十进制数。
代码:
oath = ‘我爱妞‘ print(type(oath)) print(len(oath)) oath1 = u‘我爱妞‘ print(type(oath1)) print(len(oath1)) print(oath==oath1) utf8 = oath.encode(‘utf-8‘) print(type(utf8)) print(len(utf8)) print(utf8) gbk = oath.encode(‘gbk‘) print(type(gbk)) print(len(gbk)) print(gbk) out = open(‘test.txt‘,‘w‘,encoding = ‘utf-8‘) test = u‘\u5220\u9664‘ print(len(test)) print(test) test1 = test.encode(‘utf-8‘) print(test1) print(type(test1)) out.write(test) out.close()
版权声明:本文为CSDN博主「anlian523」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/anlian523/article/details/80504699

标签:对象 两种 pytho box details alt blog nbsp 字符串
原文地址:https://www.cnblogs.com/liangxiyang/p/11566039.html