标签:组合 har 特定 出现 pre class ali 提交 维护
答:
(1)选择正确的存储引擎
以 MySQL为例,包括有两个存储引擎 MyISAM 和 InnoDB,每个引擎都有利有弊。
MyISAM
适合于一些需要大量查询的应用,但其对于有大量写操作并不是很好。甚至你只是需要update一个字段,整个表都会被锁起来,而别的进程,就算是读进程都无法操作直到读操作完成。另外,MyISAM
对于 SELECT COUNT(*) 这类的计算是超快无比的。
InnoDB 的趋势会是一个非常复杂的存储引擎,对于一些小的应用,它会比 MyISAM 还慢。但是它支持“行锁” ,于是在写操作比较多的时候,会更优秀。并且,他还支持更多的高级应用,比如:事务。
(2)优化字段的数据类型
记住一个原则,越小的列会越快。如果一个表只会有几列罢了(比如说字典表,配置表),那么,我们就没有理由使用 INT 来做主键,使用 MEDIUMINT, SMALLINT 或是更小的 TINYINT 会更经济一些。如果你不需要记录时间,使用 DATE 要比 DATETIME 好得多。当然,你也需要留够足够的扩展空间。
(3)为搜索字段添加索引
索引并不一定就是给主键或是唯一的字段。如果在你的表中,有某个字段你总要会经常用来做搜索,那么最好是为其建立索引,除非你要搜索的字段是大的文本字段,那应该建立全文索引。
(4)避免使用Select *从数据库里读出越多的数据,那么查询就会变得越慢。并且,如果你的数据库服务器和WEB服务器是两台独立的服务器的话,这还会增加网络传输的负载。即使你要查询数据表的所有字段,也尽量不要用*通配符,善用内置提供的字段排除定义也许能给带来更多的便利。
(5)使用 ENUM 而不是 VARCHAR
ENUM 类型是非常快和紧凑的。在实际上,其保存的是 TINYINT,但其外表上显示为字符串。这样一来,用这个字段来做一些选项列表变得相当的完美。例如,性别、民族、部门和状态之类的这些字段的取值是有限而且固定的,那么,你应该使用 ENUM 而不是 VARCHAR。
(6)尽可能的使用 NOT NULL
除非你有一个很特别的原因去使用 NULL 值,你应该总是让你的字段保持 NOT NULL。 NULL其实需要额外的空间,并且,在你进行比较的时候,你的程序会更复杂。 当然,这里并不是说你就不能使用NULL了,现实情况是很复杂的,依然会有些情况下,你需要使用NULL值。
(7)固定长度的表会更快
如果表中的所有字段都是“固定长度”的,整个表会被认为是 “static” 或 “fixed-length”。 例如,表中没有如下类型的字段: VARCHAR,TEXT,BLOB。只要你包括了其中一个这些字段,那么这个表就不是“固定长度静态表”了,这样,MySQL 引擎会用另一种方法来处理。
固定长度的表会提高性能,因为MySQL搜寻得会更快一些,因为这些固定的长度是很容易计算下一个数据的偏移量的,所以读取的自然也会很快。而如果字段不是定长的,那么,每一次要找下一条的话,需要程序找到主键。
并且,固定长度的表也更容易被缓存和重建。不过,唯一的副作用是,固定长度的字段会浪费一些空间,因为定长的字段无论你用不用,他都是要分配那么多的空间。
我当时是按以下四条依次回答的,他们四条从效果上第一条影响最大,后面越来越小。
① SQL语句及索引的优化
② 数据库表结构的优化
③ 系统配置的优化
④ 硬件的优化
SQL注入产生的原因:程序开发过程中不注意规范书写sql语句和对特殊字符进行过滤,导致客户端可以通过全局变量POST和GET提交一些sql语句正常执行。
a)、索引的目的是什么?
快速访问数据表中的特定信息,提高检索速度
创建唯一性索引,保证数据库表中每一行数据的唯一性。
加速表和表之间的连接
使用分组和排序子句进行数据检索时,可以显著减少查询中分组和排序的时间
b)、索引对数据库系统的负面影响是什么?
负面影响:
创建索引和维护索引需要耗费时间,这个时间随着数据量的增加而增加;索引需要占用物理空间,不光是表需要占用数据空间,每个索引也需要占用物理空间;当对表进行增、删、改、的时候索引也要动态维护,这样就降低了数据的维护速度。
c)、为数据表建立索引的原则有哪些?
在最频繁使用的、用以缩小查询范围的字段上建立索引。
在频繁使用的、需要排序的字段上建立索引
d)、 什么情况下不宜建立索引?
对于查询中很少涉及的列或者重复值比较多的列,不宜建立索引。
对于一些特殊的数据类型,不宜建立索引,比如文本字段(text)等
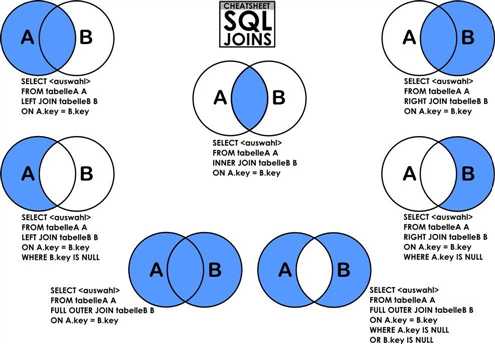
先说什么是交叉连接: 交叉连接又叫笛卡尔积,它是指不使用任何条件,直接将一个表的所有记录和另一个表中的所有记录一一匹配。
内连接 则是只有条件的交叉连接,根据某个条件筛选出符合条件的记录,不符合条件的记录不会出现在结果集中,即内连接只连接匹配的行。
外连接 其结果集中不仅包含符合连接条件的行,而且还会包括左表、右表或两个表中
的所有数据行,这三种情况依次称之为左外连接,右外连接,和全外连接。
左外连接,也称左连接,左表为主表,左表中的所有记录都会出现在结果集中,对于那些在右表中并没有匹配的记录,仍然要显示,右边对应的那些字段值以NULL来填充。右外连接,也称右连接,右表为主表,右表中的所有记录都会出现在结果集中。左连接和右连接可以互换,MySQL目前还不支持全外连接。
答:是一种固定长度的类型,varchar则是一种可变长度的类型,它们的区别是:
char(M)类型的数据列里,每个值都占用M个字节,如果某个长度小于M,MySQL就会在它的右边用空格字符补足.(在检索操作中那些填补出来的空格字符将被去掉)在varchar(M)类型的数据列里,每个值只占用刚好够用的字节再加上一个用来记录其长度的字节(即总长度为L+1字节).
varchar得适用场景:
字符串列得最大长度比平均长度大很多 2.字符串很少被更新,容易产生存储碎片 3.使用多字节字符集存储字符串
Char得场景:
存储具有近似得长度(md5值,身份证,手机号),长度比较短小得字符串(因为varchar需要额外空间记录字符串长度),更适合经常更新得字符串,更新时不会出现页分裂得情况,避免出现存储碎片,获得更好的io性能
(1)Where子句中:where表之间的连接必须写在其他Where条件之前,那些可以过滤掉最大数量记录的条件必须写在Where子句的末尾.HAVING最后。
(2)用EXISTS替代IN、用NOT EXISTS替代NOT IN。
(3) 避免在索引列上使用计算
(4)避免在索引列上使用IS NULL和IS NOT NULL
(5)对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
(6)应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描
(7)应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描
1、索引
索引是表的目录,在查找内容之前可以先在目录中查找索引位置,以此快速定位查询数据。对于索引,会保存在额外的文件中。
2、索引,是数据库中专门用于帮助用户快速查询数据的一种数据结构。类似于字典中的目录,查找字典内容时可以根据目录查找到数据的存放位置,然后直接获取即可。
1.1、索引选取类型
1、越小的数据类型通常更好:越小的数据类型通常在磁盘、内存和CPU缓存中都需要更少的空间,处理起来更快。
2、简单的数据类型更好:整型数据比起字符,处理开销更小,因为字符串的比较更复杂。
3、尽量避免NULL:应该指定列为NOT nuLL,在MySQL中, 含有空值的列很难进行查询优化,因为它们使得索引、索引的统计信息以及比较运算更加复杂
1.2、什么场景不适合创建索引
第一,对于那些在查询中很少使用或者参考的列不应该创建索引。这是因 为,既然这些列很少使用到,因此有索引或者无索引,并不能提高查询速度。相反,由于增加了索引,反而降低了系统的维护速度和增大了空间需求。
第二,对于那 些只有很少数据值的列也不应该增加索引。因为本来结果集合就是相当于全表查询了,所以没有必要。这是因为,由于这些列的取值很少,例如人事表的性别列,在查询的结果中,结果集的数据行占了表中数据行的很大比 例,即需要在表中搜索的数据行的比例很大。增加索引,并不能明显加快检索速度。
第三,对于那些定义为text, image和bit数据类型的列不应该增加索引。这是因为,这些列的数据量要么相当大,要么取值很少。
第四,当修改性能远远大于检索性能时,不应该创建索 引。这是因为,修改性能和检索性能是互相矛盾的。当增加索引时,会提高检索性能,但是会降低修改性能。当减少索引时,会提高修改性能,降低检索性能。因 此,当修改性能远远大于检索性能时,不应该创建索引。
第五,不会出现在where条件中的字段不该建立索引。
首先按 company_id,moneys 的顺序创建一个复合索引,具体如下:
mysql> create index ind_sales2_companyid_moneys on sales2(company_id,moneys); Query OK, 1000 rows affected (0.03 sec) Records: 1000 Duplicates: 0 Warnings: 0
然后按 company_id 进行表查询,具体如下:
mysql> explain select * from sales2 where company_id = 2006\G; *************************** 1. row *************************** id: 1 select_type: SIMPLE table: sales2 type: ref possible_keys: ind_sales2_companyid_moneys 208key: ind_sales2_companyid_moneys key_len: 5 ref: const rows: 1 Extra: Using where 1 row in set (0.00 sec)
可以发现即便 where 条件中不是用的 company_id 与 moneys 的组合条件,索引仍然能用到,这就是索引的前缀特性。
4、但是如果只按 moneys 条件查询表,那么索引就不会被用到,具体如下:
mysql> explain select * from sales2 where moneys = 1\G; *************************** 1. row *************************** id: 1 select_type: SIMPLE table: sales2 type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 1000 Extra: Using where 1 row in set (0.00 sec)
1、 可以发现第一个例子没有使用索引,而第二例子就能够使用索引,
2、 区别就在于“%”的位置不同,前者把“%”放到第一位就不能用到索引,而后者没有放到第一位就使用了索引。
mysql> explain select * from company2 where name like ‘%3‘\G; *************************** 1. row *************************** id: 1 select_type: SIMPLE table: company2 type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 1000 Extra: Using where 1 row in set (0.00 sec)
mysql> explain select * from company2 where name like ‘3%‘\G; *************************** 1. row *************************** id: 1 select_type: SIMPLE table: company2 type: range 209possible_keys: ind_company2_name key: ind_company2_name key_len: 11 ref: NULL rows: 103 Extra: Using where 1 row in set (0.00 sec)
mysql> explain select * from company2 where name is null\G; *************************** 1. row *************************** id: 1 select_type: SIMPLE table: company2 type: ref possible_keys: ind_company2_name key: ind_company2_name key_len: 11 ref: const rows: 1 Extra: Using where 1 row in set (0.00 sec)
SELECT * FROM table_name where key_part1 > 1 and key_part1 < 90;
mysql> show index from sales\G; *************************** 1. row *************************** Table: sales Non_unique: 1 Key_name: ind_sales_year Seq_in_index: 1 Column_name: year 210Collation: A Cardinality: NULL Sub_part: NULL Packed: NULL Null: Index_type: BTREE Comment: 1 row in set (0.00 sec)
mysql> explain select * from company2 where name = 294\G; *************************** 1. row *************************** id: 1 select_type: SIMPLE table: company2 type: ALL possible_keys: ind_company2_name key: NULL key_len: NULL ref: NULL rows: 1000 Extra: Using where 1 row in set (0.00 sec) mysql> explain select * from company2 where name = ‘294‘\G; *************************** 1. row *************************** id: 1 select_type: SIMPLE table: company2 type: ref possible_keys: ind_company2_name key: ind_company2_name key_len: 23 ref: const rows: 1 Extra: Using where 1 row in set (0.00 sec)
4.1.1.6、创建全文索引
全文索引可以用于全文搜索,但只有MyISAM存储引擎支持FULLTEXT索引,并且只为CHAR、VARCHAR和TEXT列服务。索引总是对整个列进行,不支持前缀索引,
JOIN用法
标签:组合 har 特定 出现 pre class ali 提交 维护
原文地址:https://www.cnblogs.com/wujifu/p/11576631.html