标签:png alice leave contain mamicode 函数 color rgs ons
2019.9.25:
toolz 是十分便利的工具
学习内容:itertoolz
反复将二进制函数应用于序列,累积结果,返回迭代器
如果有initial,新序列第一个值就是initial,不然就是seq的第一个值
>>> from operator import add, mul >>> list(accumulate(add, [1, 2, 3, 4, 5])) [1, 3, 6, 10, 15] >>> list(accumulate(mul, [1, 2, 3, 4, 5])) [1, 2, 6, 24, 120]
插一句:operator有以下方法提供:
__all__ = [‘abs‘, ‘add‘, ‘and_‘, ‘attrgetter‘, ‘concat‘, ‘contains‘, ‘countOf‘, ‘delitem‘, ‘eq‘, ‘floordiv‘, ‘ge‘, ‘getitem‘, ‘gt‘, ‘iadd‘, ‘iand‘, ‘iconcat‘, ‘ifloordiv‘, ‘ilshift‘, ‘imatmul‘, ‘imod‘, ‘imul‘, ‘index‘, ‘indexOf‘, ‘inv‘, ‘invert‘, ‘ior‘, ‘ipow‘, ‘irshift‘, ‘is_‘, ‘is_not‘, ‘isub‘, ‘itemgetter‘, ‘itruediv‘, ‘ixor‘, ‘le‘, ‘length_hint‘, ‘lshift‘, ‘lt‘, ‘matmul‘, ‘methodcaller‘, ‘mod‘, ‘mul‘, ‘ne‘, ‘neg‘, ‘not_‘, ‘or_‘, ‘pos‘, ‘pow‘, ‘rshift‘, ‘setitem‘, ‘sub‘, ‘truediv‘, ‘truth‘, ‘xor‘]
序列:
>>> names = [‘Alice‘, ‘Bob‘, ‘Charlie‘, ‘Dan‘, ‘Edith‘, ‘Frank‘] >>> groupby(len, names) # doctest: +SKIP {3: [‘Bob‘, ‘Dan‘], 5: [‘Alice‘, ‘Edith‘, ‘Frank‘], 7: [‘Charlie‘]}
序列嵌套字典:通过key对 List[dict] 分组,注意结果??
>>> groupby(‘gender‘, [{‘name‘: ‘Alice‘, ‘gender‘: ‘F‘}, ... {‘name‘: ‘Bob‘, ‘gender‘: ‘M‘}, ... {‘name‘: ‘Charlie‘, ‘gender‘: ‘M‘}]) # doctest:+SKIP {‘F‘: [{‘gender‘: ‘F‘, ‘name‘: ‘Alice‘}], ‘M‘: [{‘gender‘: ‘M‘, ‘name‘: ‘Bob‘}, {‘gender‘: ‘M‘, ‘name‘: ‘Charlie‘}]}
合并序列,并排序。返回惰性迭代器。
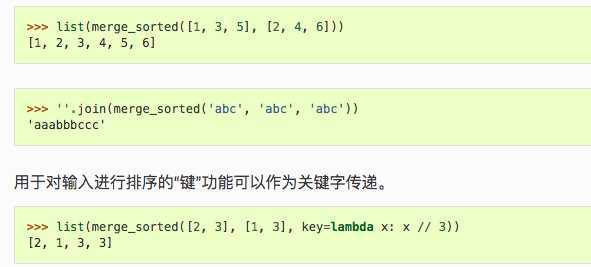
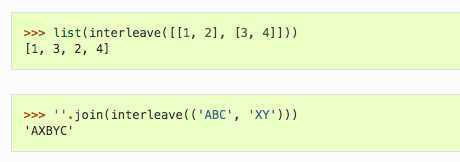
交替合并序列,返回惰性迭代器(不解包不执行)
类似集合的特性,保持元素唯一性,同时很灵活的可以通过key做唯一性的约定

返回布尔值,x是否可迭代的。
返回布尔值,seq中元素是否不重复。
返回序列的前n个元素。
返回序列的除前n个元素的其他元素,返回迭代器。
隔n-1个元素取出一个,并加入到迭代器.
from toolz import take_nth seq = [1,2,3,4,5,6,7,8,9,0] take_nth(seq, 3) list(take_nth(3, seq)) >>>[1, 4, 7, 0]
返回seq的第一或二或n或最后一个元素。
返回迭代器。
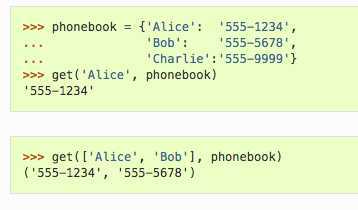
序列:等同 seq[x] for x in ind

字典:获取指定key的value
列表嵌套列表:拆开子列表,不做去重和排序,返回迭代器。可被set()强转达到去重的目的
>>> list(concat([[], [1], [2, 3]]))
[1, 2, 3]
将el插到seq序列的开头。
seq每个元素中间都插一个el。
>>> list(interpose("a", [1, 2, 3])) [1, ‘a‘, 2, ‘a‘, 3]

后续补充
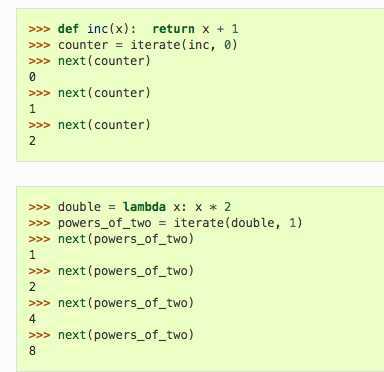
反复将函数func应用于原始输入。
例如:产生x,然后是func(x),然后是func(func(x)),然后是func(func(func(x))),依此类推。
通过next()产生下一个结果
产生重叠为n位的子序列:
>>> list(sliding_window(2, [1, 2, 3, 4])) [(1, 2), (2, 3), (3, 4)]
按照n,将序列拆分成元组,不重叠。如果的长度seq不能被整除n,则最后的元组将被丢弃(如果pad未指定),或通过填充填充至长度n。pad是填充值。
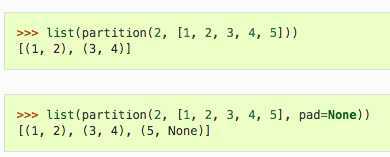
和partition区别是,突出的元素不会被丢弃或填充,只是独立成一个元组

将序列之间不同的元素,最多两个,组成一个元组。如果有奇数个元素不同,最后那个元素可能丢弃(除非default存在填充)。key将一个函数应用于每个项目。

找出序列的k个最大元素。key设定挑选规则
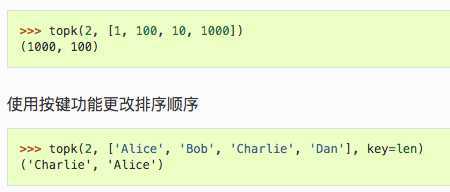
返回两个值,一个是seq的第一个元素,另一个是该原始seq。
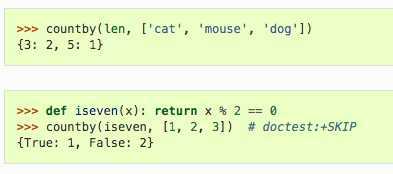
针对key制定的规则对seq进行计数:
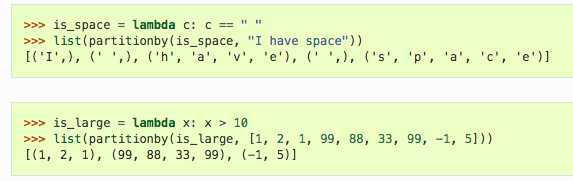
根据func对seq进行分区。每次func的输出更改时 ,都会启动一个新列表,并将后续项目收集到该列表中。
标签:png alice leave contain mamicode 函数 color rgs ons
原文地址:https://www.cnblogs.com/marvintang1001/p/11586506.html