标签:bottom 例子 tin hold eve join lang 第一步 log
上篇(使用c++开发跨平台程序)说到,我不怕造东西,我怕的是造出来的东西,如果出了问题,我却不知道原因.所以调试分析是一个重要的手段.
C++调试是一个复杂的活.虽然大部分调试可以通过IDE在开发期间就解决了.但是必然的,还有很多东西需要在生产环境中还原它.分析它,然后解决它.gdb是一个成熟的工具.围绕着它有很多的工具可以选择.不过这么多工具的根本还是命令行模式下的gdb.
废话不多说,现在我就用gdb来分析调试一下吧.
在shell中输入命令:
ulimit -c unlimited;
然后运行自己的程序,如果程序此时崩溃,就会在目录生成一个名为core的文件.(这个也看系统配置.)
使用命令 gdb Test1 core加载文件.或者它的详细命令 gdb -c core -e Test1 --symbols Test1 --readnow
下面是一个命令行输出的截图:

上图中可以解释的不多.因为我们现在刚要入门.所以只能注意上图中的三个红框.
红框1:命令行其中app7是可执行文件,而core是dump文件.
红框2:标明gdb在app7中找到了它对应的symbol.
红框3:标明core文件是经由app7产生的.这里是为了防止载入了错误的可执行文件.
注意一下几点:
如果使用sanitize,请取消.不然不会在崩溃时产生dump文件.反而是一个错误报告.
在生成可执行文件的时候,应该用debug模式,也可以用RelWithDebInfo模式.主要目的是能够获得程序的调试符号.
如果没有symbol信息,也可以调试,但是过程将会难上很多倍,毕竟我们是调试,不是破解.不过,还别说,gdb调试跟破解其实还是有点相通的.
由于gdb调试有非常多指令.从时效性上来说,不需要记住全部指令.只需要知道常用的指令就好.就算有人费事费力记住了所有指令,时间一长,如果不用的话也是会忘记的.所以能看到英文文档,我觉得比记住指令更有用.
大部分错误在IDE开发期间就已经被解决了.需要调试core dump文件的情况一般都是运行的时候出现的错误,我这里简单介绍以下几类
指针为NULL.栈溢出,除数为0,死锁.
下面给定一个程序,程序的内容如下:
#include <stdlib.h>
void bar(int* p)
{
int aa=*p;
}
void foo()
{
int* p=NULL;
bar(p);
}
int main(int argc, const char * argv[])
{
foo();
return 0;
}
编译后假设输出是app0,运行app0后会有core文件.现在我来加载这个core文件.截图如下:
![]()

加载完毕以后,可以看到gdb已经指出来了app0.cpp地15行有问题.
然后我们回到源码,查看第15行,的确是有问题.所有null问题已经解决.是不是简单无比?呵呵.但是我们要更进一.看看到底为什么.
1. 我使用p p,(第一个p是print,是gdb指令,第二个p是参数p);
![]()
这说明p是一个0.所以这里会出错.
2. 按理说,以上的分析可以得出结论了.不过这里我想再进一步.
首先我列出 所有线程
info thread
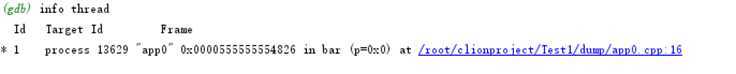
就只有一个线程,很好.
其次,我看看堆栈
bt

可以看到调用堆栈,是从foo函数调用的bar函数.所以参数p是从foo里产生的.
可以看出,空引用虽然解决了,回头考虑一下的话,这里有点事后诸葛的意思.有人会问”你是已经事先知道空引用了.然后去分析的,这谁不会…”,真正的现实当中的空引用的确分析起来比这个困难一点.不过这个系列是让人们基本会用gdb.知道每种类型大体长什么样子.在现实问题中,分析的时候好有个方向.具体工作当中的问题.只能到时再分析.
栈溢出一般递归函数退出条件没有达成,导致的循环调用.栈溢出调试比较简单,特征也很明显.
下面我借用一个例子来说明一下.这个例子的作者是一个外国人,具体是谁.我忘记了.
#include <stdio.h>
#include <pthread.h>
#include <unistd.h>
#include <string.h>
#include <stdlib.h>
void procF(int i)
{
int buffer[128] = {-1, 0, i+1, 0, -1};
procF(buffer[2]);
}
void procE()
{
procF(1);
}
#define THREAD_DECLARE(num,func) void bar_##num(){sleep(3);func;}void foo_##num(){bar_##num();}void * thread_##num (void *arg){foo_##num();return 0;}
THREAD_DECLARE(one,procE())
THREAD_DECLARE(two,sleep(-1))
THREAD_DECLARE(three,sleep(-1))
THREAD_DECLARE(four,sleep(-1))
THREAD_DECLARE(five,sleep(-1))
#define THREAD_CREATE(num) {pthread_t threadID_##num; pthread_create (&threadID_##num, NULL,thread_##num, NULL);}
int main(int argc, const char * argv[])
{
THREAD_CREATE(one)
THREAD_CREATE(two)
THREAD_CREATE(three)
THREAD_CREATE(four)
THREAD_CREATE(five)
sleep(-1);
return 0;
}
以上文件很简单,定义了一个宏,然后使用这个宏,复制生成了5个线程.其中thread_one这个线程,会陷入死循环.它会在procF中循环调用,导致一个堆栈溢出.
我们来看看它长什么样子.具体怎么加载core我这里就略过了.直接看gdb内容吧.

上面说cannot access memory at address xxx,然后列出最近执行具体位置是一个大括号,没有什么参考意义
1. 我先看看所有线程

6个线程,除去第一个是不能能读取内存的错误以为,其余的都在sleep.这里按照gdb的提示(它说procF有问题),我先看看thread 1,因为只有它停留在了procF;
2. 指令thread 1 表示切换到线程1.然后查看它的堆栈,看看是如何到达这个procF的.

到这里发现procF自己调用自己,按照经验,这里应该是栈溢出了.但是为了确认一下,我决定看看它调用了多少层.
3. 指令 bt是打印调用堆栈了.bt -20是打印最底层的20个调用

发现它调用了15000次..这里还有一个好处就是,可以看到来源.是从procE来的.
下一步就可以去查看proceE的内容了.在gdb中也是可以做到的,如下图

好了,到此调用栈溢出就解决了.
但是,还是可以在这里展开一下.我们知道函数的调用是放置在线程的占空间的.我们从占空间中看看,有没有什么规律.
为了显示栈空间,需要用到gdb的一个指令x(查看)
详细观察 bt -20返回的结果,可以看到类似如下
#14971 0x00005636f87b2c91 in procF (i=1) at /root/clionproject/Test1/dump/app6.cpp:16
#14972 0x00005636f87b2cb6 in procE () at /root/clionproject/Test1/dump/app6.cpp:20
其中#14971是frame的编号.
后边的0x00005636f87b2c91,是代码在内存中的位置.即app6.cpp:16这行所对应的二进制代码就在内存的此位置
gdb搞起

p $rsp 和 info r $rsp 代表打印寄存器rsp里面的值. $rsp是指向栈顶端的寄存器.所以它的值就一定是栈顶端.
我来检查一下这个栈.

这里主要是引出x指令.x是查看指定地址的指令.
除数为0是一个简单的问题.代码我就不上了.
载入core文件就会显示
![]()
说这是一个算术问题.发生在procD函数中
现在我检查一下procD是什么东西

Disass是disassembly 的意思,指令是打印对应地址的反汇编代码.
上图中红框处,就是现在指令所运行的位置.系统认为在这个位置出错了.看idivl 它显然是一个除法.到这里十有八九是除数为零了.
看到汇编指令idivl -0x8(%rbp),其中的-x8(%rbp),代表一个值,这个值就是除数.所以我要把它代表的值找到.
首先查看一下 rbp是什么东东,rbp是一个寄存器,它指向了一个base point,你可以简单的认为所有函数内部申请的栈变量(比如 int a=0等等),都是通过rbp换算的.
![]()
其次查看一下这个地址-8是啥.
![]()
既然$rbp-0x8是一个变量的地址,那么我们就看看这个地址写的什么值.

可以看到它的确是写的0.
除数为0,就结束了.
死锁也是一个常见的问题,不过死锁有个特点,并不是每一个死锁都会被dump下来.所以在遇到死锁的时候,有时候需要使用在线调试的办法,不过这个办法.
现在我使用以下代码
#include <stdio.h>
#include <pthread.h>
#include <stdlib.h>
#include <unistd.h>
#include <mutex>
static int sequence1 = 0;
static int sequence2 = 0;
std::mutex lock1;
std::mutex lock2;
int func1()
{
lock1.lock();
sleep(1);
sequence1++;
lock2.lock();
sequence2++;
lock1.unlock();
lock2.unlock();
return sequence1;
}
int func2()
{
lock2.lock();
sleep(1);
sequence2++;
lock1.lock();
sequence1++;
lock2.unlock();
lock1.unlock();
return sequence1;
}
void* thread1(void *arg)
{
int rev = 0;
while(1)
{
rev = func1();
if (rev == 100000)
{
pthread_exit(NULL);
}
}
}
void* thread2(void *arg)
{
int rev = 0;
while(1)
{
rev = func2();
if (rev == 100000)
{
pthread_exit(NULL);
}
}
}
void* thread3(void *arg)
{
int count = 0;
while(1)
{
sleep(1);
if ( count++ > 10000)
{
pthread_exit(NULL);
}
}
}
void* thread4(void *arg)
{
int count = 0;
while(1)
{
sleep(1);
if ( count++ > 10000)
{
pthread_exit(NULL);
}
}
}
int main()
{
pthread_t tid[4];
if(pthread_create(&tid[0], NULL, & thread1, NULL) != 0)
{
_exit(1);
}
if(pthread_create(&tid[1], NULL, & thread2, NULL) != 0)
{
_exit(1);
}
if(pthread_create(&tid[2], NULL, & thread3, NULL) != 0)
{
_exit(1);
}
if(pthread_create(&tid[3], NULL, & thread4, NULL) != 0)
{
_exit(1);
}
sleep(5);
pthread_join(tid[0], NULL);
pthread_join(tid[1], NULL);
pthread_join(tid[2], NULL);
pthread_join(tid[3], NULL);
return 0;
}
以上代码主要集中在func1和func2中,他们相互等待就有可能会死锁.现在我编译它运行以下.
![]()
由于它只是死锁,所有在我机器上并没有dump下来,我要用gdb,在线调试它.截图如下

我先用ps找到了进程id是14661,用gdb 附着了它,现在开始调试了.
先看thread

这两个线程有可能死锁.先看看 thread 2 是如何调用的.调用堆栈搞起.

它是调用了func1,我看看func1的内容

它提示有两个变量分别是lock1和lock2.所以我想看看这两个变量

提示,这两个锁,被不同的线程持有.
再回头看看thread 2 的调用堆栈

可以看到,它提示线程14662 停在了lock2.lock()方法那里了这个线程想要获得锁的所有权. 而lock2,按照上一个截图,已经被14663持有了.
用相同的办法也可以得到lock1的细节.我这里就不复述了.
所以这个死锁就被我找到了原因.
真正现实当中遇到的问题,不会像这样就很快的被找到.因为这里是创造问题然后去解决,有点事后诸葛的意思.比如现实当中的死锁,找到对应的锁变量这一步就不会那么容易,需要耐心和运气,不过使用gdb的第一步就是首先熟悉出问题的时候大体的调用堆栈模式,然后再去尝试可能的出错方向,进而解决它.如果只是记得冷冰冰gdb指令,在我眼里就如同多记住了几个英文单词而已,我认为意义不大.
标签:bottom 例子 tin hold eve join lang 第一步 log
原文地址:https://www.cnblogs.com/gaopang/p/11588683.html