标签:style blog http io os ar for sp strong
一.堆排序的优缺点(pros and cons)
(还是简单的说说这个,毕竟没有必要浪费时间去理解一个糟糕的的算法)
优点:
缺点:(从上面看,堆排序几乎是完美的,那么为什么最常用的内部排序算法是快排而不是堆排序呢?)
二.内部原理
首先要知道堆排序的步骤:
按小根堆排序结果是降序(或者说是非升序,不要在意这种细节..),按大根堆排序的结果是升序
上面这句话乍看好像不对(小根堆中最小元素在堆顶,数组组堆顶元素就是a[0],怎么会是降序?),不过不用质疑这句话的正确性,看了下面这几幅图就明白了:
假设待排序序列是a[] = {7, 1, 6, 5, 3, 2, 4},并且按大根堆方式完成排序
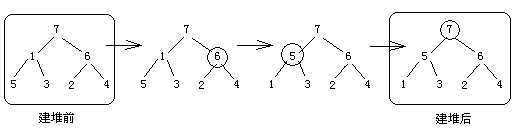
{7, 5, 6, 1, 3, 2, 4}已经满足了大根堆,第一步完成

无图,眼睛画瞎了,mspaint实在不好用。。到第二步应该差不多了吧,剩下的用笔也就画出来了。。
其实核心就是“断尾”,但可悲的是所有的资料上都没有明确说出来,可是,还有比“断尾”更贴切的描述吗?
三.实现细节
原理介绍中给出的图基本上也说清楚了实现细节,所以这里只关注代码实现
#include<stdio.h>
//构造大根堆(让a[m]到a[n]满足大根堆)
void HeapAdjust(int a[], int m, int n){
int temp;
int max;
int lc;//左孩子
int rc;//右孩子
while(1){
//获取a[m]的左右孩子
lc = 2 * m + 1;
rc = 2 * m + 2;
//比较a[m]的左右孩子,max记录较大者的下标
if(lc >= n){
break;//不存在左孩子则跳出
}
if(rc >= n){
max = lc;//不存在右孩子则最大孩子为左孩子
}
else{
max = a[lc] > a[rc] ? lc : rc;//左右孩子都存在则找出最大孩子的下标
}
//判断并调整(交换)
if(a[m] >= a[max]){//父亲比左右孩子都大,不需要调整,直接跳出
break;
}
else{//否则把小父亲往下换
temp = a[m];
a[m] = a[max];
a[max] = temp;
//准备下一次循环,注意力移动到孩子身上,因为交换之后以孩子为根的子树可能不满足大根堆
m = max;
}
}
}
void HeapSort(int a[], int n){
int i,j;
int temp;
//自下而上构造小根堆(初始堆)
for(i = n / 2 - 1;i >= 0;i--){//a[n/2 - 1]恰好是最后一个非叶子节点(叶子节点已经满足小根堆,只需要调整所有的非叶子节点),一点小小的优化
HeapAdjust(a, i, n);
}
printf("初始堆: ");
for(i = 0;i < n;i++){
printf("%d ", a[i]);
}
printf("\n");
for(i = n - 1;i > 0;i--){
//首尾交换,断掉尾巴
temp = a[i];
a[i] = a[0];
a[0] = temp;
//断尾后的部分重新调整
HeapAdjust(a, 0, i);
/*
printf("第%d次(i - 1 = %d): ", n - i, i - 1);
for(j = 0;j < n;j++){
printf("%d ", a[j]);
}
printf("\n");
*/
}
}
main(){
//int a[] = {5, 6, 3, 4, 1, 2, 7};
//int a[] = {1, 2, 3, 4, 5, 6, 7};
//int a[] = {7, 6, 5, 4, 3, 2, 1};
int a[] = {7, 1, 6, 5, 3, 2, 4};
int m, n;
int i;
m = 0;
n = sizeof(a) / sizeof(int);
//HeapAdjust(a, m, n);
HeapSort(a, n);
printf("结果: ");
for(i = 0;i < n;i++){
printf("%d ", a[i]);
}
printf("\n");
}
P.S.代码中注释极其详尽,因为是完全一步一步自己想着写出来的,应该不难理解。看代码说话,在此多说无益。
#include<stdio.h>
void HeapAdjust(int a[], int m, int n){
int i;
int t = a[m];
for(i = 2 * m + 1;i <= n;i = 2 * i + 1){
if(i < n && a[i + 1] > a[i])++i;
if(t >= a[i])break;
//把空缺位置往下放
a[m] = a[i];
m = i;
}
a[m] = t;//只做一次交换,步骤上的优化
}
void HeapSort(int a[], int n){
int i;
int t;
//自下而上构造大根堆
for(i = n / 2 - 1;i >= 0;--i){
HeapAdjust(a, i, n - 1);
}
printf("初始堆: ");
for(i = 0;i < n;i++){
printf("%d ", a[i]);
}
printf("\n");
for(i = n - 1;i > 0;i--){
//首尾交换,断掉尾巴
t = a[i];
a[i] = a[0];
a[0] = t;
//对断尾后的部分重新建堆
HeapAdjust(a, 0, i - 1);
}
}
main(){
//int a[] = {5, 6, 3, 4, 1, 2, 7};
//int a[] = {1, 2, 3, 4, 5, 6, 7};
//int a[] = {7, 6, 5, 4, 3, 2, 1};
int a[] = {7, 1, 6, 5, 3, 2, 4};
int m, n;
int i;
m = 0;
n = sizeof(a) / sizeof(int);
//HeapAdjust(a, m, n);
HeapSort(a, n);
printf("结果: ");
for(i = 0;i < n;i++){
printf("%d ", a[i]);
}
printf("\n");
}
P.S.书本上的代码短了不少,不仅仅是篇幅上的优化,也有实实在在的步骤上的优化,细微差别也在注释中说明了。但这种程度的优化却使得代码的可读性大大降低,所以一次次拿起算法书,又一次次放下。。(实际应用中我们可以对书本上的代码做形式上的优化,在保持其高效性的同时尽可能的提升其可读性。。)
#include<stdio.h>
//构造小根堆(让a[m]到a[n]满足小根堆)
void HeapAdjust(int a[], int m, int n){
int i;
int t = a[m];
int temp;
for(i = 2 * m + 1;i <= n;i = 2 * i + 1){
//a[m]的左右孩子比较,i记录较小者的下标
if(i < n && a[i + 1] < a[i]){
i = i + 1;
}
if(t <= a[i]){
break;
}
else{//把空缺位置往下换
//把较小者换上去
temp = a[m];
a[m] = a[i];
a[i] = temp;
//准备下一次循环
m = i;
}
}
}
void HeapSort(int a[], int n){
int i, j;
int temp;
//自下而上构造小根堆(初始堆)
for(i = n / 2 - 1;i >= 0;i--){//a[n/2 - 1]恰好是最后一个非叶子节点(叶子节点已经满足小根堆,只需要调整所有的非叶子节点),一点小小的优化
HeapAdjust(a, i, n);
}
printf("初始堆: ");
for(i = 0;i < n;i++){
printf("%d ", a[i]);
}
printf("\n");
//把每个元素都调整到应该去的位置
for(i = n - 1; i > 0;i--){
//首尾交换
temp = a[i];
a[i] = a[0];
a[0] = temp;
//断尾后剩余部分重新调整
HeapAdjust(a, 0, i - 1);
}
}
main(){
//int a[] = {7, 6, 5, 4, 3, 2, 1};
//int a[] = {1, 5, 6, 4, 3, 2, 7};
int a[] = {1, 2, 3, 4, 5, 6, 7};
int m, n;
int i;
m = 0;
n = sizeof(a) / sizeof(int);
//HeapAdjust(a, m, n);
HeapSort(a, n);
printf("结果: ");
for(i = 0;i < n;i++){
printf("%d ", a[i]);
}
printf("\n");
}
P.S.注释依然详尽,看代码,不废话
四.总结
堆排序的步骤就几个字而已:建堆 -> 首尾交换,断尾重构 -> 重复第二步,直到断掉所有尾巴
还有比这更清晰更明了的描述吗?
到现在我们已经掌握了几个有用的排序算法了:
那么实际应用中要如何选择呢?有这些选择标准:
说明:在理解“断尾”的过程中参考了前辈的博文,特此感谢
标签:style blog http io os ar for sp strong
原文地址:http://www.cnblogs.com/ayqy/p/4052646.html