标签:_id cursor type 类型 iuc close wmi select CMF
# -*-coding:utf-8-*-
import arcpy
import pyodbc
import os
# 指定工作空间
arcpy.env.workspace = r"E:\shp"
# 2000坐标系
fc_2000 = "YDBP_2000.shp"
cursor_2000 = arcpy.da.InsertCursor(fc_2000, ["FLOWSN", "XMMC", "KCID", "DKID", "COOR_TYPE", "SHAPE@"])
# 80坐标系
fc_80 = "YDBP_80.shp"
cursor_80 = arcpy.da.InsertCursor(fc_80, ["FLOWSN", "XMMC", "KCID", "DKID", "COOR_TYPE", "SHAPE@"])
# 未知坐标系
fc_unknown = "YDBP_unknown.shp"
cursor_unknown = arcpy.da.InsertCursor(fc_unknown, ["FLOWSN", "XMMC", "KCID", "DKID", "COOR_TYPE", "SHAPE@"])
# 根据需要设置变量:流程号、项目名称、勘测定界ID、地块ID、坐标系类型
FLOWSN = ""
XMMC = ""
KCID = ""
DKID = ""
COOR_TYPE = ""
count = 0
# 遍历每个mdb文件
path = r"E:\LYMDB"
mdblist = os.listdir(path)
try:
for mdbfile in mdblist:
# 获取项目名称
XMMC = mdbfile[:-4]
print XMMC.decode("gb2312") + " is beginning..."
# 获取mdb文件的完整路径
mdbfullpath = os.path.join(path, mdbfile)
# 根据本机的驱动程序编写连接字符串
# mdbsource = r‘DRIVER={Microsoft Access Driver (*.mdb,*.accdb)};DBQ=‘ + mdbfullpath + ‘;‘
mdbsource = r‘DRIVER={Microsoft Access Driver (*.mdb)};DBQ=‘ + mdbfullpath.decode("gb2312") + ‘;‘
with pyodbc.connect(mdbsource) as dbconn:
cur = dbconn.cursor()
# 根据勘测定界技术说明,获得勘测ID与坐标系的对应关系
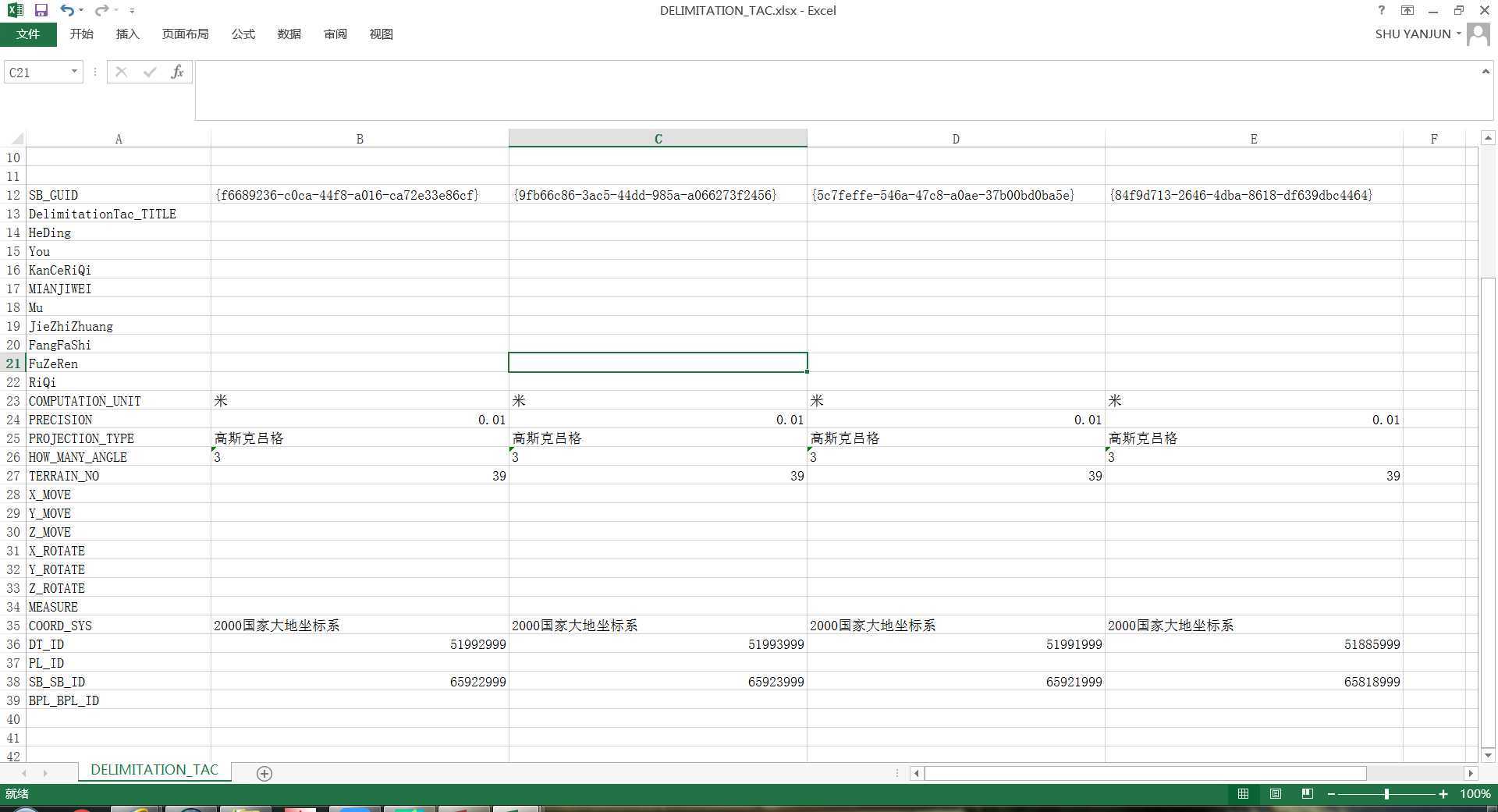
xysql = "select * from DELIMITATION_TAC order by SB_SB_ID;"
cur.execute(xysql)
xyalldata = cur.fetchall()
xynum = len(xyalldata)
xydict = {}
if xynum > 0:
for xyid in range(xynum):
xydict[xyalldata[xyid][26]] = xyalldata[0][23]
# 根据勘测定界表,获取FLOWSN,勘测ID与地块ID的对应关系
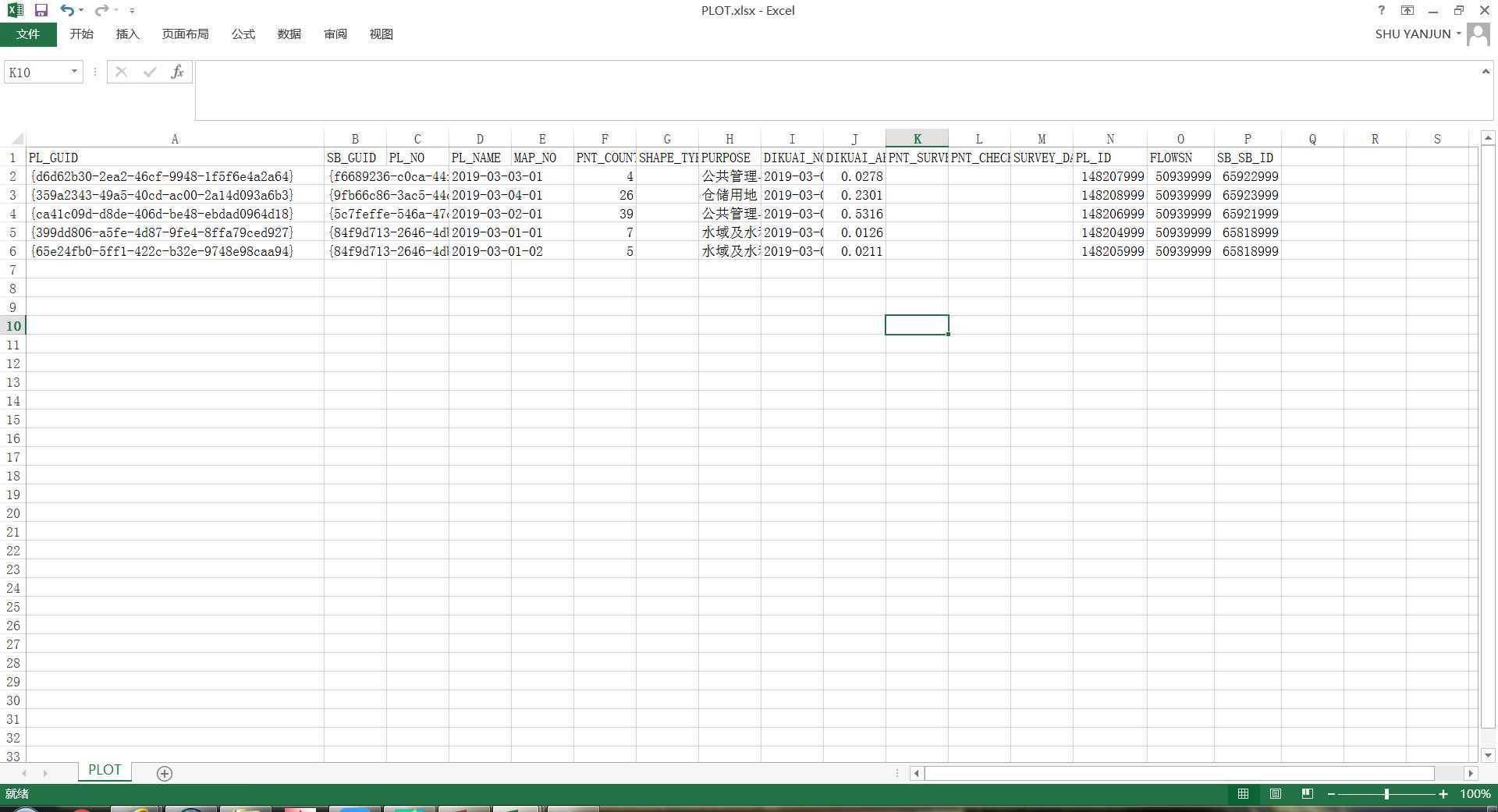
kcidsql = "select * from PLOT order by PL_ID;"
cur.execute(kcidsql)
kcidalldata = cur.fetchall()
kcidnum = len(kcidalldata)
kcdict = {}
if kcidnum > 0:
FLOWSN = kcidalldata[0][14]
for id in range(kcidnum):
kcdict[kcidalldata[id][13]] = kcidalldata[id][15]
# 根据坐标点顺序升序排序,并获取界址点成果表
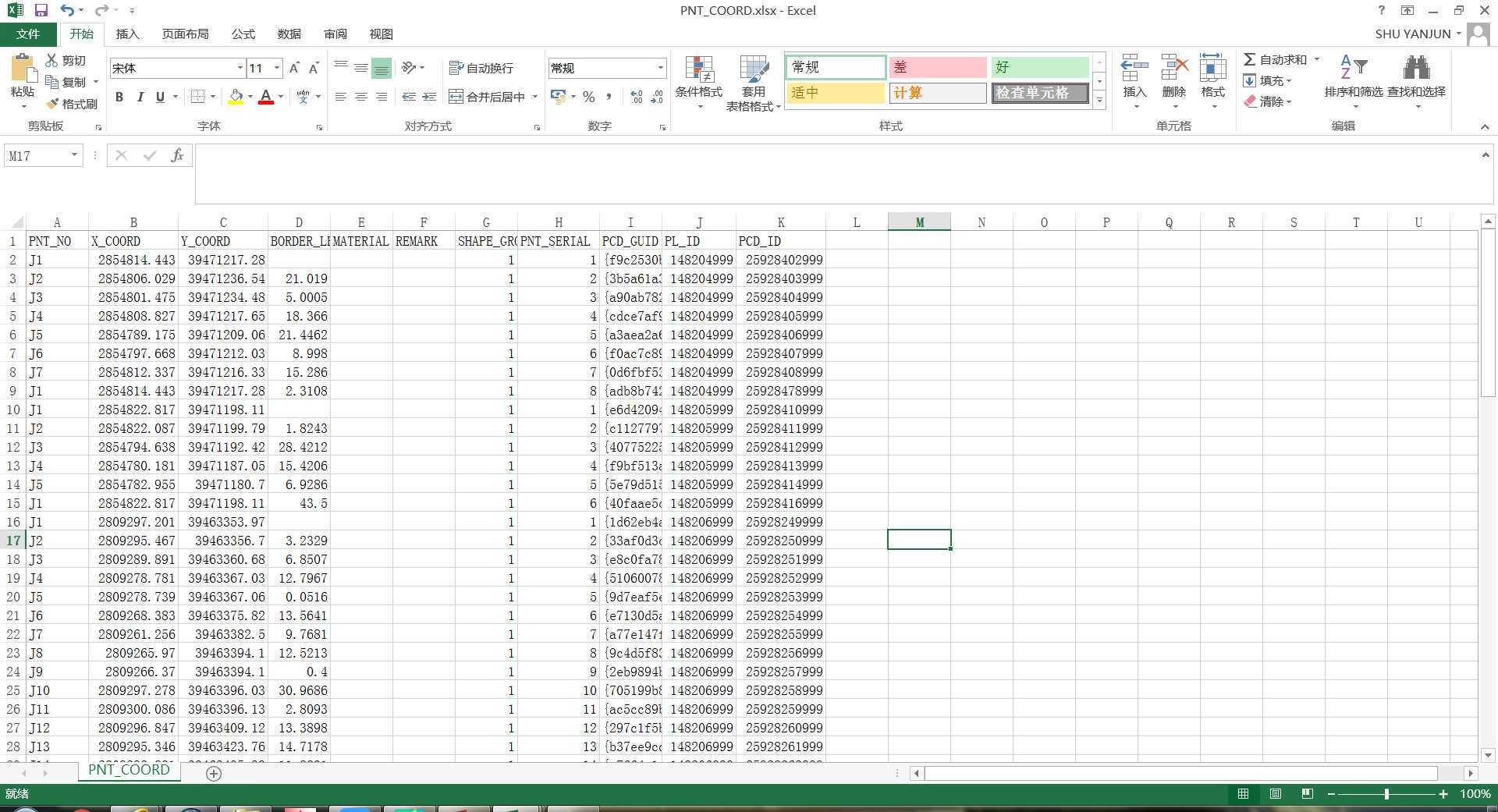
sql = "select * from PNT_COORD order by PL_ID,PNT_SERIAL;"
cur.execute(sql)
alldata = cur.fetchall()
# 计算成所有坐标行数,包括表头
rownum = len(alldata)
# 存放坐标点的列表
polygonarray = arcpy.Array()
# 根据需要,设置字段
PNT_SERIAL = ""
PL_ID = ""
# 遍历读取坐标表中的坐标
for i in range(1, rownum, 1):
row = alldata[i]
X_COORD = row[1]
Y_COORD = row[2]
PNT_SERIAL = row[7]
PL_ID = row[9]
# 对DKID第一次赋值
if DKID == "":
DKID = row[9]
# 生成坐标点
pnt = arcpy.Point()
pnt.ID = int(PNT_SERIAL)
pnt.X = float(Y_COORD)
pnt.Y = float(X_COORD)
# 如果地块ID发生变化,说明包含多个地块
if DKID == PL_ID:
polygonarray.add(pnt)
else:
# 生成面要素
poly = arcpy.Polygon(polygonarray)
# 根据地块ID找到对应的勘测ID
KCID = kcdict[DKID]
# 根据勘测ID获取坐标系类型
COOR_TYPE = xydict[KCID]
# 追加到要素类中
if COOR_TYPE == u"80国家大地坐标系":
cursor_80.insertRow([FLOWSN, XMMC, KCID, DKID, COOR_TYPE, poly])
elif COOR_TYPE == u"2000国家大地坐标系":
cursor_2000.insertRow([FLOWSN, XMMC, KCID, DKID, COOR_TYPE, poly])
else:
cursor_unknown.insertRow([FLOWSN, XMMC, KCID, DKID, COOR_TYPE, poly])
# 将新的地块ID赋值给fid
DKID = row[9]
# 清除掉之前的坐标点,并将当前坐标点添加到polygonarray中
polygonarray.removeAll()
polygonarray.add(pnt)
if polygonarray.count > 0:
# 生成面要素
poly = arcpy.Polygon(polygonarray)
# 根据地块ID找到对应的勘测ID
KCID = kcdict[DKID]
# 根据勘测ID获取坐标系类型
COOR_TYPE = xydict[KCID]
# 根据不同的坐标系,追加到不同的图层中
if COOR_TYPE == u"80国家大地坐标系":
cursor_80.insertRow([FLOWSN, XMMC, KCID, DKID, COOR_TYPE, poly])
elif COOR_TYPE == u"2000国家大地坐标系":
cursor_2000.insertRow([FLOWSN, XMMC, KCID, DKID, COOR_TYPE, poly])
else:
cursor_unknown.insertRow([FLOWSN, XMMC, KCID, DKID, COOR_TYPE, poly])
# 计数,便于统计
count = count + 1
print mdbfile.decode("gb2312")
# 关闭mdb连接
dbconn.close()
# 将变量初始化
FLOWSN = ""
XMMC = ""
KCID = ""
DKID = ""
COOR_TYPE = ""
print "一共上图{0}个...".format(count)
except Exception as e:
print e.args
# 删除图层游标,释放资源
if cursor_2000:
del cursor_2000
if cursor_80:
del cursor_80
if cursor_unknown:
del cursor_unknown
从坐标文件mdb中生成图形_批量
标签:_id cursor type 类型 iuc close wmi select CMF
原文地址:https://www.cnblogs.com/apromise/p/11595860.html