大数据部落 -中国专业的第三方数据服务提供商,提供定制化的一站式数据挖掘和统计分析咨询服务
统计分析和数据挖掘咨询服务:y0.cn/teradat(咨询服务请联系官网客服)
![]() ?
?QQ:3025393450
![]() ?QQ交流群:186388004
?QQ交流群:186388004 
【服务场景】
科研项目; 公司项目外包;线上线下一对一培训;数据爬虫采集;学术研究;报告撰写;市场调查。
【大数据部落】提供定制化的一站式数据挖掘和统计分析咨询

欢迎选修我们的R语言数据分析挖掘必知必会课程!

标签:特定 ast shadow splay 10个 bootstra inf geo god
确定数据集中最佳的簇数是分区聚类(例如k均值聚类)中的一个基本问题,它要求用户指定要生成的簇数k。
一个简单且流行的解决方案包括检查使用分层聚类生成的树状图,以查看其是否暗示特定数量的聚类。不幸的是,这种方法也是主观的。
我们将介绍用于确定k均值,k medoids(PAM)和层次聚类的最佳聚类数的不同方法。
这些方法包括直接方法和统计测试方法:
除了肘部,轮廓和间隙统计方法外,还有三十多种其他指标和方法已经发布,用于识别最佳簇数。我们将提供用于计算所有这30个索引的R代码,以便使用“多数规则”确定最佳聚类数。
对于以下每种方法:
回想一下,诸如k-均值聚类之类的分区方法背后的基本思想是定义聚类,以使总集群内变化[或总集群内平方和(WSS)]最小化。总的WSS衡量了群集的紧凑性,我们希望它尽可能小。
Elbow方法将总WSS视为群集数量的函数:应该选择多个群集,以便添加另一个群集不会改善总WSS。
最佳群集数可以定义如下:
平均轮廓法计算不同k值的观测值的平均轮廓。聚类的最佳数目k是在k的可能值范围内最大化平均轮廓的数目(Kaufman和Rousseeuw 1990)。
该方法可以应用于任何聚类方法。
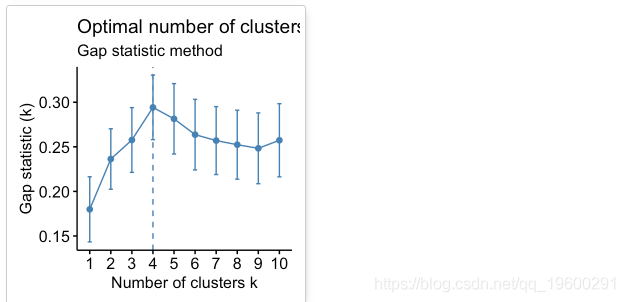
间隙统计量将k的不同值在集群内部变化中的总和与数据空引用分布下的期望值进行比较。最佳聚类的估计将是使差距统计最大化的值(即,产生最大差距统计的值)。
我们将使用USArrests数据作为演示数据集。我们首先将数据标准化以使变量具有可比性。
head(df)
## Murder Assault UrbanPop Rape
## Alabama 1.2426 0.783 -0.521 -0.00342
## Alaska 0.5079 1.107 -1.212 2.48420
## Arizona 0.0716 1.479 0.999 1.04288
## Arkansas 0.2323 0.231 -1.074 -0.18492
## California 0.2783 1.263 1.759 2.06782
## Colorado 0.0257 0.399 0.861 1.86497 简化格式如下:
下面的R代码确定k均值聚类的最佳聚类数:
# Elbow method
fviz_nbclust(df, kmeans, method = "wss") +
geom_vline(xintercept = 4, linetype = 2)+
labs(subtitle = "Elbow method")
# Silhouette method
# Gap statistic
## Clustering k = 1,2,..., K.max (= 10): .. done
## Bootstrapping, b = 1,2,..., B (= 50) [one "." per sample]:
## .................................................. 50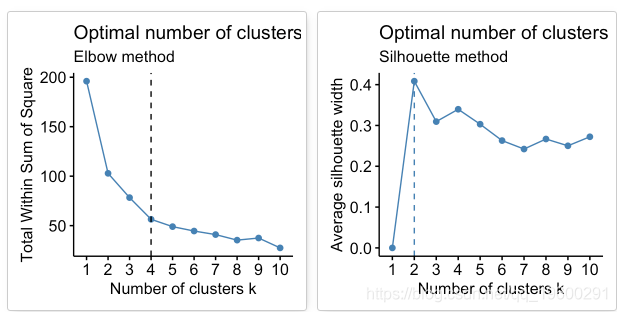
![]() ?
? 
![]() ?
?
根据这些观察,有可能将k = 4定义为数据中的最佳簇数。
30个索引,用于选择最佳数目的群集
数据:矩阵
下面的R代码为k均值计算:
## Among all indices:
## ===================
## * 2 proposed 0 as the best number of clusters
## * 10 proposed 2 as the best number of clusters
## * 2 proposed 3 as the best number of clusters
## * 8 proposed 4 as the best number of clusters
## * 1 proposed 5 as the best number of clusters
## * 1 proposed 8 as the best number of clusters
## * 2 proposed 10 as the best number of clusters
##
## Conclusion
## =========================
## * According to the majority rule, the best number of clusters is 2 .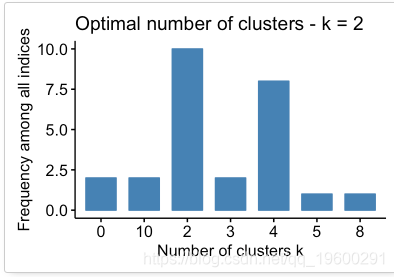
![]() ?
?
根据多数规则,最佳群集数为2。
大数据部落 -中国专业的第三方数据服务提供商,提供定制化的一站式数据挖掘和统计分析咨询服务
统计分析和数据挖掘咨询服务:y0.cn/teradat(咨询服务请联系官网客服)
![]() ?
?QQ:3025393450
![]() ?QQ交流群:186388004
?QQ交流群:186388004
【服务场景】
科研项目; 公司项目外包;线上线下一对一培训;数据爬虫采集;学术研究;报告撰写;市场调查。
【大数据部落】提供定制化的一站式数据挖掘和统计分析咨询
欢迎选修我们的R语言数据分析挖掘必知必会课程!
标签:特定 ast shadow splay 10个 bootstra inf geo god
原文地址:https://www.cnblogs.com/tecdat/p/11601633.html