标签:ike 了解 findall 转化 之间 local import $$ 比较
包,这里的包就相当于模块,当一个模块的功能特别强大时需要写在多个文件里,这就用到了包,包不改变模块的导入方式,在包里可以写多个文件,还可以包里再建包。
包是含有__init__.py的文件夹,导入包就是导入__init__
包的导入:
如图所示‘包的介绍.py’是和‘aaaa’文件夹同一级的执行文件,现在我们要做的是将"aaaa"这个包里面的文件导入到执行文件中供执行文件使用。
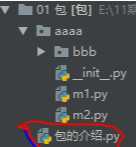
第一步:配置“aaaa”的__init__
#比较牛的方法:相对导入 .文件名,用于同目录下文件的导入
# .表示当前文件夹下的文件
# ..表示父文件夹下的文件
# ...表示爷爷文件夹下的文件
#只需在init文件夹里如下配置
from .m1 import *
from .m1 import *
#麻烦一点的方法:绝对导入
from aaaa.m1 import *
from aaaa.m2 import *#因为执行文件和包在同一个文件夹,所以执行文件的搜寻范围只有和自己同一个文件夹内的文件,所以只能找到‘aaaa’我们只有aaaa.m1执行文件才能找到m1
第二步:配置“bbb”的__init__
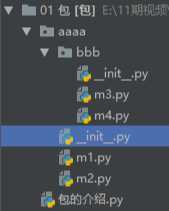
#这里也有绝对导入和相对导入之分,相对导入和上面的方法一模一样,绝对导入略有差别
from aaaa.bbb.m3 import f5# 绝对导入:必须按照执行文件的搜索路径为基准
from .m3 import f5包,这里的包就相当于模块,当一个模块的功能特别强大时需要写在多个文件里,这就用到了包,
包不改变模块的导入方式,在包里可以写多个文件,还可以包里再建包
time模块提供了三种类型的时间(时间戳、格式化时间、结构化时间)
import time
print(time.time())#打印1970到当前时间的秒数
time.sleep(10)# 程序暂停十秒
print(time.time())
# 1569652202.5354526
# 1569652212.5853515
#以下内容仅作了解
#格式化时间
print(time.strftime('%Y-%m-%d %X'))
#2019-09-28 14:38:54
#结构化时间
print(time.localtime())
#time.struct_time(tm_year=2019, tm_mon=9, tm_mday=28, tm_hour=14, tm_min=38, tm_sec=54, tm_wday=5, tm_yday=271, tm_isdst=0)
#格式化时间、结构化时间、时间戳是可以相互转化的,具体和转化方式如下,应用场景很少仅作了解
# 结构化时间 --》 格式化时间
struct_time = time.localtime(3600*24*365)
print(time.strftime('%Y-%m-%d %X',struct_time))
# 格式化时间 --》 结构化时间
format_time = time.strftime('%Y-%m-%d %X')
print(time.strptime(format_time,'%Y-%m-%d %X'))
# 结构化时间 --》 时间戳
struct_time = time.localtime(3600*24*365)
print(time.mktime(struct_time))
# 时间戳 --》 结构化时间
time_stamp = time.time()
print(time.localtime(time_stamp))
# 1971-01-01 08:00:00
# time.struct_time(tm_year=2019, tm_mon=9, tm_mday=28, tm_hour=14, tm_min=38, tm_sec=54, tm_wday=5, tm_yday=271, tm_isdst=-1)
# 31536000.0
# time.struct_time(tm_year=2019, tm_mon=9, tm_mday=28, tm_hour=14, tm_min=38, tm_sec=54, tm_wday=5, tm_yday=271, tm_isdst=0)功能:时间的加减
import datetime
now = datetime.datetime.now()#获取当前的时间
print(now)
#2019-09-28 16:59:07.890314
#时间的加减
#默认以天为单位进行加减
print(now + datetime.timedelta(2))
#2019-09-30 16:59:07.890314
#如果想以其他时间单位进行加减,需要把单位带上(时间单位=数字)
print(now + datetime.timedelta(weeks=2))
print(now + datetime.timedelta(hours=3))
2019-10-12 17:00:45.945068
2019-09-28 20:00:45.945068
#替换时间
print(now.replace(year=1949,month=10,day=1,hour=10,minute=1))
1949-10-01 10:01:45.945068hashlib对字符加密,没有密钥功能,hmac对字符加密,并加密钥
hashlib是比较简单的加密算法,可利用撞库进行反解,hmac稍微的高级一些,不过像现在的大厂一般都有自己的加密算法。
import hashlib
m = hashlib.md5()
m.update(b'say')
m.update(b'hello')
print(m.hexdigest())#981fe96ed23ad8b9554cfeea38cd334a
m2 = hashlib.md5()
m2.update(b'sayhello')
print(m2.hexdigest())#981fe96ed23ad8b9554cfeea38cd334a上面演示的是hashlib的叠加性,就是一串字符分开加密和放在一起进行加密得到的结果都是一样的,(空格也是字符)
以下是撞库算法反解哈希加密算演示,思路很简单就是将一个个明码转成哈希密码然后和已经获取的哈希密码进行对比
hash_pwd = '0562b36c3c5a3925dbe3c4d32a4f2ba2'
pwd_list = [
'hash3714',
'hash1313',
'hash94139413',
'hash123456',
'123456hash',
'h123ash',
]
for pwd in pwd_list:
m = hashlib.md5()
m.update(pwd.encode('utf8'))
res = m.hexdigest()
if res == hash_pwd:
print(f'获取密码成功:{pwd}')这里Nike推荐了三本和变成没啥关系的书:《动物庄园》《1984》《美丽新世界》
import hmac
m = hmac.new(b'maerzi')#密钥
m.update(b'hash123456')#设置好的密码
print(m.hexdigest())#得到的是密钥和密码放在一起加密的密码
f82317e44545b0ab087109454814b5c4这种加密算法安全度更高一些但也不是绝对的安全,加密方式类似于英格玛(个人认为)
typing模块与函数连用,控制函数参数的数据类型,提供了基础数据类型之外的数据类型
这个模块主要用在定义函数时规定传参的数据类型
from typing import Iterable,Iterator
def func(x: int,lt: Iterable)-> list:#list规定的是返回参数的数据类型
return [1,2,3]request主要应用于爬取数据,模拟浏览器对URL发送请求,拿到数据
URL:统一资源定位系统(uniform resource locator;URL)是因特网的万维网服务程序上用于指定信息位置的表示方法。它最初是由蒂姆·伯纳斯·李发明用来作为万维网的地址。现在它已经被万维网联盟编制为互联网标准RFC1738。
这里课堂上举了一个例子爬取段子网的段子,里面用到了正则对爬取的数据进行筛选和拼接,得到可用的数据
import re
import requests
response = requests.get('https://ishuo.cn')
data = response.text
res = re.findall('<div class="content">(.*?)</div>|</span><a href="/subject/.*?">(.*?)</a>',data)
利用正则对得到的数据进行切分得到需要的数据
with open('duanzi_new.txt','w',encoding='utf-8') as fw:
for i in res:#遍历得到的元组
print(i)
if i[1]:#将元组0和1位置中存入相应的数据,这里用解压缩会更好
fw.write(i[1]+':'+'\n\n')
if i[0]:
if i[0].startswith('<ul>'):
continue
fw.write(i[0]+'\n')相当牛逼的一个文件数据处理的模块,就是每个字符代表的功能不太好记,容易弄懵逼。
import re
#s = '取字符串找符合某种特点的字符串'
#res = re.findall('字符',s)
#元字符
s = 'abcdabc'
#^表示以……开头
res = re.findall('^ab',s)
print(res)#找到一个就不找了
#['ab']
# $以……结尾
res = re.findall('bc$',s)
print(res)#找到一个就不找了
#['bc']
#.任意字符
res = re.findall('abc.',s)
print(res)
#['abcd']
#\d数字
s = '678s123fhfsi456hfifkl'
res = re.findall('\d',s)
print(res)
#['6', '7', '8', '1', '2', '3', '4', '5', '6']
# \D非数字
res = re.findall('\D',s)
print(res)
#['s', 'f', 'h', 'f', 's', 'i', 'h', 'f', 'i', 'f', 'k', 'l']
#\w非空,数字字母下划线
res = re.findall('\w',s)
print(res)
#['6', '7', '8', 's', '1', '2', '3', 'f', 'h', 'f', 's', 'i', '4', '5', '6', 'h', 'f', 'i', 'f', 'k', 'l']
#\W空
res = re.findall('\W',s)
print(res)
#[]
#\s空,空指的是' '\n,\t
res = re.findall('\s',s)
print(res)
#[]
#\S非空
res = re.findall('\S',s)
print(res)
#['6', '7', '8', 's', '1', '2', '3', 'f', 'h', 'f', 's', 'i', '4', '5', '6', 'h', 'f', 'i', 'f', 'k', 'l']
#+加号前面的那个字符至少一个
res = re.findall('hf+',s)
print(res)
#['hf', 'hf']
s = 'asdddddf'
res = re.findall('asd+',s)
print(res)
#['asddddd']
# ?前面的字符0-1个
s = 'abcddddd abcd abc'
res = re.findall('abcd?',s)
print(res)
#['abcd', 'abcd', 'abc']
# *前面的一个字符至少0个
res = re.findall('abcd*',s)
print(res)
#['abcddddd', 'abcd', 'abc']
# []中括号内的字符都可以,括号内的字每个和外面的字组成的几个字
s = 'abc bbc cbc dbc'
print(re.findall('[abc]bc', s))
#['abc', 'bbc', 'cbc']
# [^]中括号内的都不可以
s = 'abc bbc cbc dbc'
print(re.findall('[^abc]bc', s))
#['dbc']
# |或
s = 'abc bbc dbc'
print(re.findall('abc|bbc', s))
#['abc', 'bbc']
# {n}:和花括号挨着的字符要有n个
s = 'abccabc abccc'
print(re.findall('abc{2}', s))
#['abcc', 'abcc']
# {n1,n2}:和花括号挨着的字符要有n1个或者n2个且n2>n1,都要
s = 'abccabc abccc'
print(re.findall('abc{2,3}', s))
#['abcc', 'abccc']
# 贪婪模式
# .(任意字符)*(0-无穷个)'x1.*x2'以第一个x1开始,以最后一个x2结束
s = 'abcdefgbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbg'
print(re.findall('a.*f', s))
#['abcdef']
print(re.findall('a.*g', s))
#['abcdefgbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbg']
## 非贪婪模式(*******)
#
## .(任意字符)*(0-无穷个)?(让他进入非贪婪模式)
#'x1.*x2'以第一个x1开始,以第一个x2结束
s = 'abcdefgbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbg'
print(re.findall('a.*?g', s))
#['abcdefg']
s = 'abcdaefgbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbg'
print(re.findall('a.*?g', s))
#['abcdaefg']
#了解:特殊构造
# a(?=\d) :a后面是数字,但是不要数字,不消耗字符串内容
s = 'a123 aaaa a234 abc'
# a1 aa
# aa
# aa a2 ab
print(re.findall('a(?=\d)',s))
print(re.findall('a(?=\w)',s))
#['a', 'a']
#['a', 'a', 'a', 'a', 'a', 'a']
# 匹配邮箱:
s = '#@#@#@nickchen121@163.com$$$$////nick@qq.com$$#$#$[]]2287273393@162.com@$2423423lksdlfj#'
res = re.findall('\w+@\w+.com', s)
print(res)
#['nickchen121@163.com', 'nick@qq.com', '2287273393@162.com']
# 补充(非常有用)
## 修饰符 --> re.S会让.匹配换行符(*****)
s = '''abc
abcabc*abc
'''
# .不匹配换行
print(re.findall('abc.abc', s))
# ['abc*abc']
#re.S匹配换行符
print(re.findall('abc.abc', s, re.S))
# ['abc\nabc', 'abc*abc']
## 分组 --> 只要括号里的(*****)
s = 'abc abcd abcdd'
print(re.findall('a(.)c(d)', s))
#[('b', 'd'), ('b', 'd')]
# 有名分组(了解)
s = 'abc abcd abcdd'
print(re.search('a(?P<name>.)c(?P<name2>d)', s).groupdict())
#{'name': 'b', 'name2': 'd'}
# 超高级用法
s = 'abc123abc123' # c123a
print(re.sub('c(\d+)a', ' ', s))
print(re.sub('c(?P<name1>\d+)a', '\g<name1>', s)) # \g<name1>这个东西不能替换掉
# ab bc123这里空格替代掉了c-a之间的数字
# ab123bc123这里给数字都加了名字,带名字的都不会被替换掉,c、a被删除.*?
贪婪和非贪婪
findall
re.S
match和sarch的区别
分组
有名分组:给分组加名字
杂七杂八的元字符
特殊构造元字符
特殊修饰符
下面的仅作了解
# compile
s = '2242209519@qq.com155179378317795522446615'
# res = re.compile('abcd*')
email_pattern = re.compile('\w+@\w+.com')#找邮箱
phone_patter = re.compile('\d{13}')#找13位的数字
print(re.findall(email_pattern, s))
print(re.findall('abcd*', s))
## match: 从开头找一个,找得到就不找了 ;找不到报错 --》
# s = 'ab abcddd abc'
# res = re.match('abcd*', s)
# print(res.group())
## search: 从字符串找一个,就不找了
s = 'ab abcddd abc'
res = re.search('abcd*', s)
print(res.group())
#abcddd
## split
s = 'ab23423abcddd234234abcasdfjlasjdk234l23lk4j2kl34kl25k3j2kl3j5lkj'
print(re.split('\d+', s))
## sub == replace
s = 'ab23423abcddd234234abcasdfjlasjdk234l23lk4j2kl34kl25k3j2kl3j5lkj'
print(re.sub('\d+', ' ', s))
## subn --> 替换了多少次
s = 'ab23423abcddd234234abcasdfjlasjdk234l23lk4j2kl34kl25k3j2kl3j5lkj'
print(re.subn('\d+', ' ', s))包、time、datetime、hashlib和hmac、request、re
标签:ike 了解 findall 转化 之间 local import $$ 比较
原文地址:https://www.cnblogs.com/ghylpb/p/11605263.html