标签:排查 tin mda 大数 lis http exe dash 逻辑
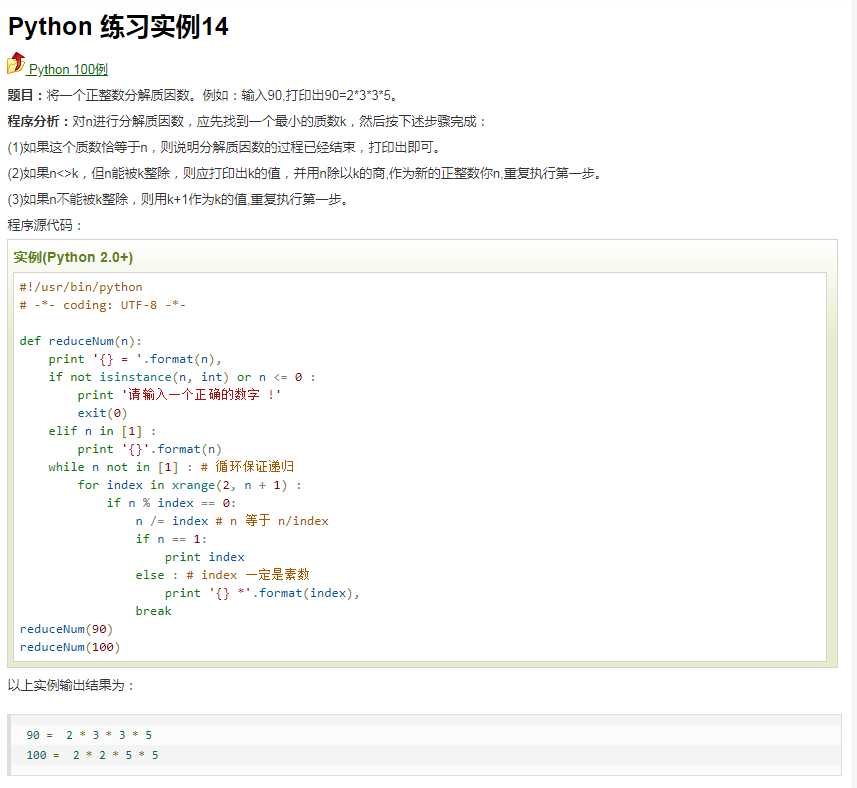
题目:将一个正整数分解质因数。例如:输入90,打印出90=2*3*3*5。
我的源代码:
#!/usr/bin/python # encoding=utf-8 # -*- coding: UTF-8 -*- # 将一个正整数分解质因数。例如:输入90,打印出90=2*3*3*5。 a = int(input("please input the number:\n")) b = a # a 的因数集合 la = [] l = [] c = int(a*0.5)+2 print("c: ==> ",c) for i in range(2,c): if i !=2 and i%2==0: continue elif i !=3 and i%3==0: continue elif i !=5 and i%5==0: continue elif i !=7 and i%7==0: continue elif i !=11 and i%11==0: continue elif i !=13 and i%13==0: continue elif i !=17 and i%17==0: continue elif i !=19 and i%19==0: continue elif i !=23 and i%23==0: continue elif i !=29 and i%29==0: continue #print(i,"###") if a%i==0: la.append(i) a = a/i while(1): if a%i==0: la.append(i) a =a/i else: break if len(la) == 0: la.append(1) la.append(b) print(b," = ",end=" ") for i in range(len(la)): print(la[i],end=" ") if i==len(la)-1: print("\n") else : print(" * ",end=" ")
此代码的弊端,就是对于一个稍微大一点的数,但是其质因子都是比较小的数,处理起来太浪费时间:
所以想过,对于大一些的数的处理逻辑:
1、先建立一个数字y以内的质数表
2、优先查看这个大数所包含的质数表内的所有质因子;
3、对于质因子不在列表范围内的,再执行搜索程序;(这个比较耗时间)
优化后的代码(对于较大的数字,都能以稍快一些的时间处理完):
#!/usr/bin/python # encoding=utf-8 # -*- coding: UTF-8 -*- # 将一个正整数分解质因数。例如:输入90,打印出90=2*3*3*5。 a = int(input("please input the number:\n")) b = a # a 的因数集合 la = [] x = 0 #y = 1000000 #用于判断计算质数列表的最大临界 y = 300000 #用于判断计算质数列表的最大临界 if 1: # 先构建一个质数列表: l = [] for i in range(2,y): k = 1 if i == 2: l.append(i) continue else : m = int(i ** 0.5) #square root for j in range(2,m): if i%j == 0: k = 0; #print(i,"is not a prime.") break if k == 1: l.append(i) #print("list: ",l) #排查这个数对应的列表内的质因子: for n in range(len(l)): #print(n,"###") if a%l[n]==0: la.append(l[n]) a = a/l[n] while(1): if a%l[n]==0: la.append(l[n]) a =a/l[n] else: break c = 1 #c用于标记la列表的个数之积是否等于a for o in range(len(la)): c = c * la[o] if c == b: x = 1 #x用于标记a这个数的质因子是否全部找到了,如果为1,表示全部找到了;x默认为0; # 第一步处理完毕; d = int(a) f = int(a) """ print(b," = ",end=" ") for i in range(len(la)): print(la[i],end=" ") if i==len(la)-1: print("* the new number!\n") else : print(" * ",end=" ") """ # print("==> d = ",d) # 下一步的数据循环点; # 只用于计算较大的质因子。 if x == 0: e = int(d*0.5)+2 # print("==> e = ",e) if y<e: #对于特别大的数字a; for i in range(y,e): #我得去判断y比e大还是小啊; print(i,"###") if d%i==0: la.append(i) x = 2 #标记la列表有增加; d = d/i while(1): if d%i==0: la.append(i) d =d/i else: break else : for i in range(2,e): #我得去判断y比e大还是小啊; print(i,"###") if d%i==0: la.append(i) x = 2 #标记la列表有增加; d = d/i while(1): if d%i==0: la.append(i) d =d/i else: break if x == 0: #表明d本身为质数,为a的质因数; #print("2:",la,"f:",f)# la.append(f) #print("1:",la)# # 对于输入的数字为质数的情况; if len(la) == 0: la.append(1) la.append(b) # 这里面实际将1当做质数了,如果默认1不为质数,那么可以输出:a是质数;无质因子; print(b," = ",end=" ") for i in range(len(la)): print(la[i],end=" ") if i==len(la)-1: print("\n") else : print(" * ",end=" ")
处理结果:

原题给出的解答:
————————(我是分割线)————————
参考:
1. RUNOOB.COM:https://www.runoob.com/python/python-exercise-example14.html
备注:
初次编辑时间:2019年9月29日19:14:24
环境:Windows 7 / Python 3.7.2
【Python】【demo实验17】【练习实例】【将一个正整数分解质因数】
标签:排查 tin mda 大数 lis http exe dash 逻辑
原文地址:https://www.cnblogs.com/kaixin2018/p/11609558.html