标签:全面 也会 分类 cal 比特率 一点 ram 准确率 文献
前景提要:
这篇论文是Multi-frame quality enhancement for compressed video(CVPR 2018)的期刊版本,2019年9月26日被TPAMI(2018年IF=17.730)接收。博主和关振宇导师是共同一作,徐迈老师是通讯作者、第三作者。
本文提出了一种针对压缩视频的质量增强方法。创新点:
我们看图说话:
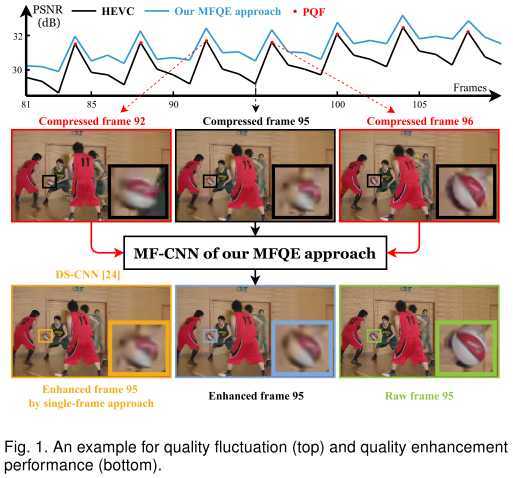
首先,我们以压缩视频库中的6个视频为例,看一看质量波动性:
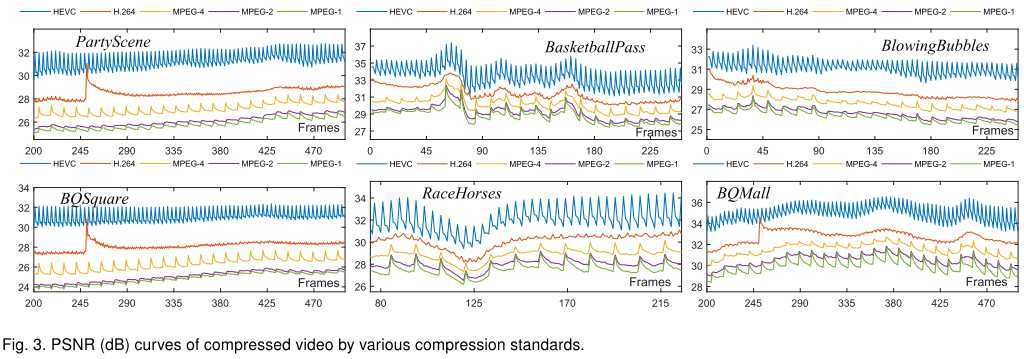
可见,无论是HEVC、H264还是MPEG-1/2/4,这种质量波动性都是存在的,并且在HEVC中尤为明显。本文以HEVC为主要分析对象。
进一步,我们对这种质量波动性进行量化。我们衡量两个指标:
我们在整个视频库(108个视频)中统计了上述两个指标的平均值,结果如表:
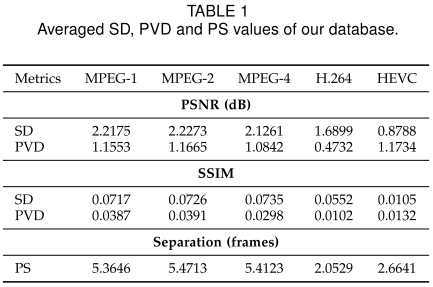
质量波动性有两点意义:
进一步,我们得看看好帧补偿差帧是否可行。我们测量了相邻若干帧的两帧之间的相关系数及其标准差,如图:
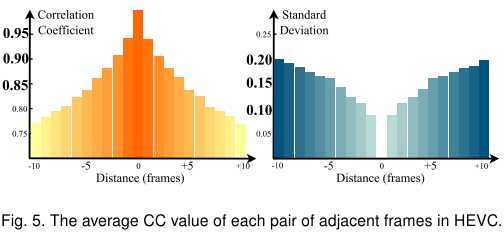
结果说明:
那么,压缩视频中好帧(局部质量峰值)之间的平均距离大概是多少呢?我们在上一个表格中展示了PS这个指标,在HEVC大概是2.66。好帧之间的距离如此近,结合上图可知,两个相邻好帧 与它们中间的差帧 之间的相关性极高。
总之,我们的思想是有前景的!
我们的MFQE方法由一个框图说明:
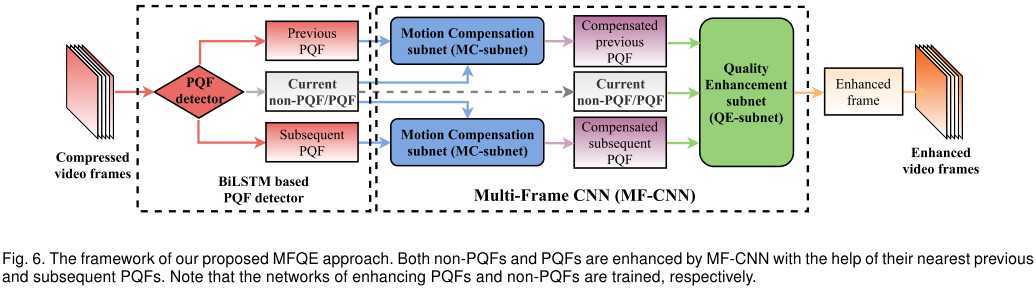
批注:MFQEv1.0对于好帧的增强采用的是图像增强方法DS-CNN。这里好帧也用相邻好帧进行增强,得到了审稿人好评,因为网络得到了统一和简化。
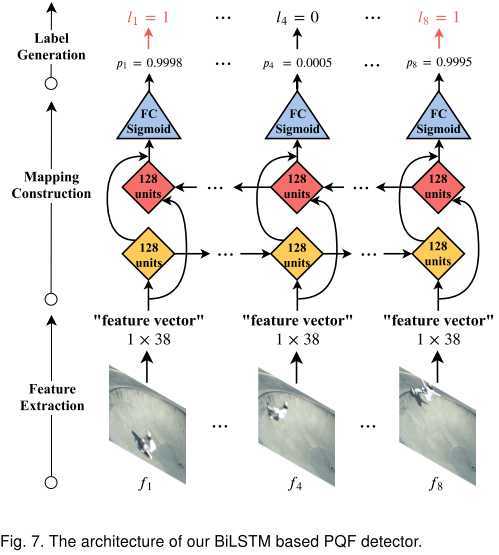
分类器用BiLSTM搭建。对于每一帧,我们都采用参考文献[2]提供的质量评估方法,得到一个36维的向量;然后我们再添加这一帧的比特率和QP(这些都可以从码流中轻易获得),得到一个38维的向量,表征这一帧,输入BiLSTM网络。
理想状况下,BiLSTM能够通过比较这些特征向量,找出局部质量极大值点。
要注意,这是一个无参考(no-reference)的分类器:即不需要原始无损视频信息,不需要PSNR信息,而是通过传统的质量评估方法获得的“特征向量”,再进行学习。
批注:MFQEv1.0中的分类器采用的是SVM。这里用BiLSTM,极大提升了分类准确率,并且降低了分类难度,提升了分类速度。
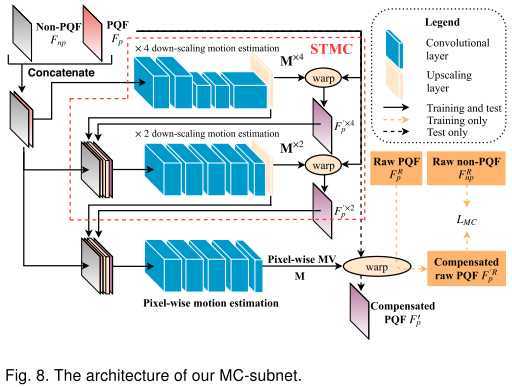
为了让整体网络可以端到端训练,这里的运动补偿网络采用的是基于CNN的光流预测网络[29]。
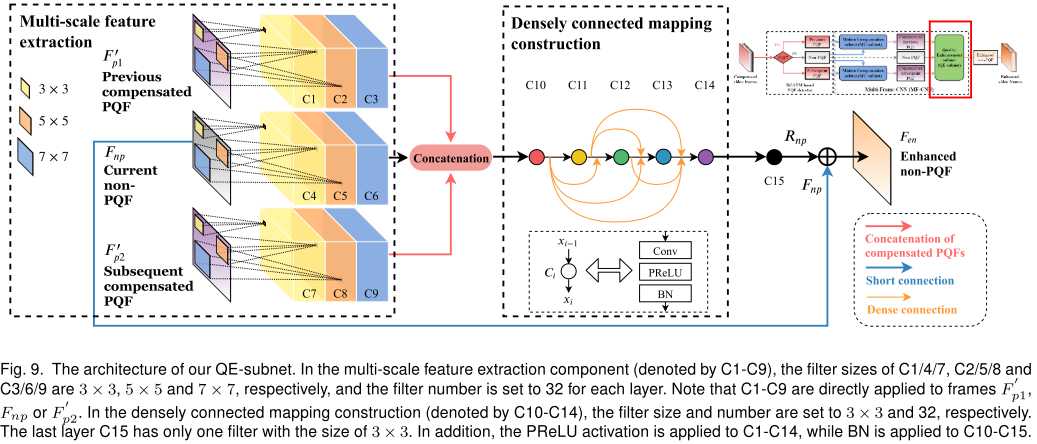
运动补偿后的好帧,与差帧一起输入网络。在前端,我们采用了三种scale的特征提取;在后端,我们采用了稠密连接和BN技巧。整体上,我们还采用了短连接。
批注:MFQEv1.0中的质量增强网络是渐进融合网络,效果差得多,参数量也大得多(5倍以上)。
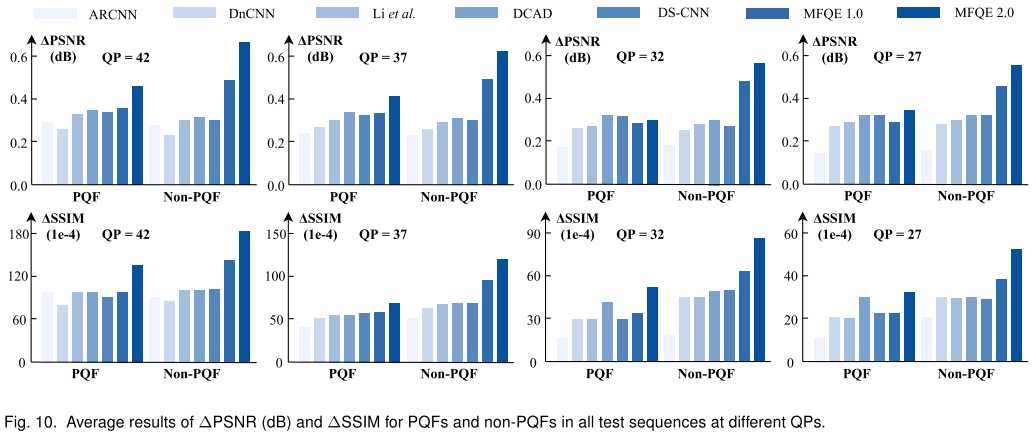
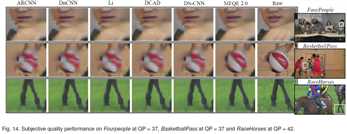
好帧在文中就是PQF,差帧就是non-PQF。如图,MFQEv2.0算法在好帧增强上略高于其他算法,但在差帧增强方面显著高于其他算法。这就体现了MFQEv2.0的优势。
我们以PSNR的增强数据为标准。如大表格:
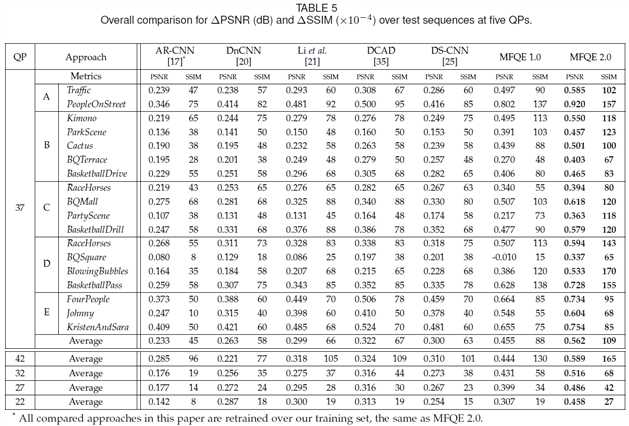
在国际标准测试序列(18个视频)上,MFQEv2.0全面胜出,展现出较好的泛化能力。
编码领域通常还衡量BDBR指标。我们看看结果:
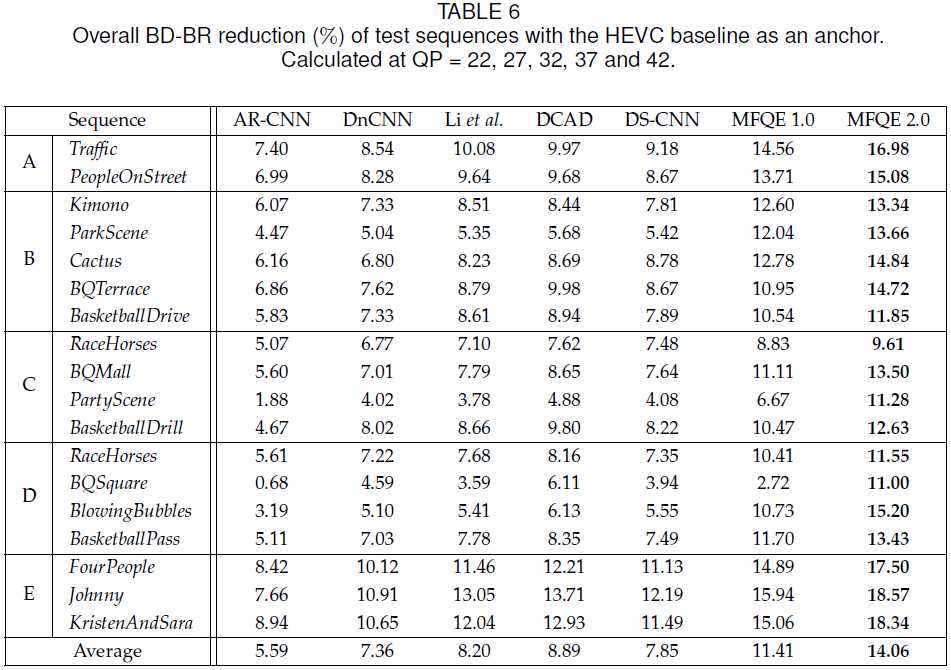
图像方法最多能到9%,而MFQE方法能达到14%。
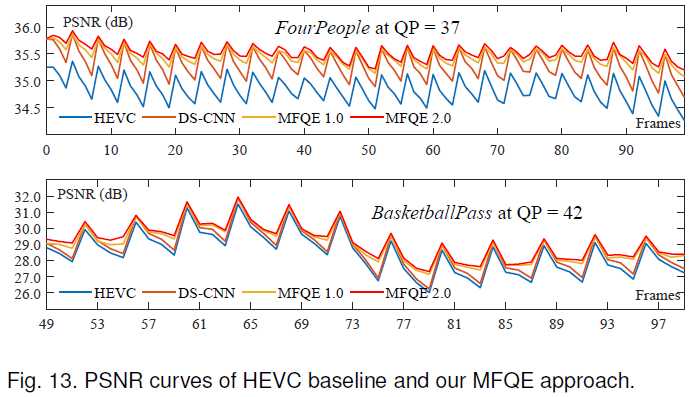
由于MFQEv2.0对差帧的提升非常显著,因此可以缓和质量波动现象。我们通过示例和数值来验证这一点:
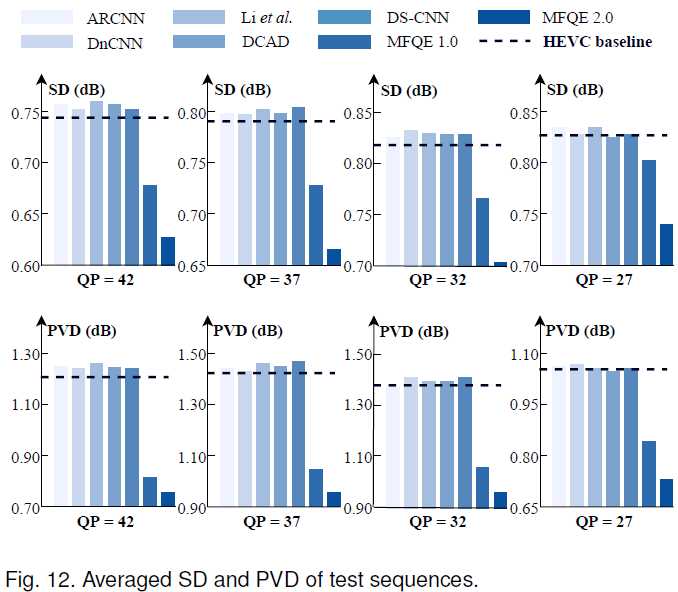
如图,PSNR的标准差显著下降,而峰值-谷值差距减小,说明质量波动下降明显。从PSNR曲线上我们也可以看到:
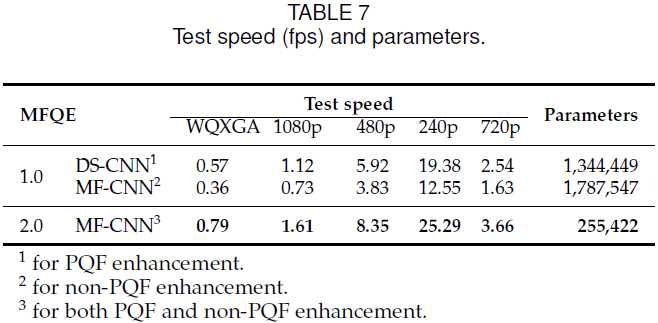
MFQEv2.0不仅效果好,而且参数少、帧速率快。这进一步说明了多帧方法的优势:我们不需要冗余的网络,多帧信息是我们的杀手锏。
Paper | MFQE 2.0: A New Approach for Multi-frame Quality Enhancement on Compressed Video
标签:全面 也会 分类 cal 比特率 一点 ram 准确率 文献
原文地址:https://www.cnblogs.com/RyanXing/p/11610438.html