标签:不可 原创 实现 pyplot div 很多 有用 文章 view
论文地址:https://arxiv.org/pdf/1812.01187.pdf
更多方法和代码可见:图像分类任务中的tricks总结
更多更全的tricks补充(补充链接也是福利满满~)
目录
2 训练过程(baseline复现原文精度,作为下面的基础)
3 高效训练(大BS为出发,但部分小BS也适用)(效率改进)
3.1 大批量训练(主要是学习率)
3.1.4 无偏衰减 -0.3%(预防过拟合)
4 模型变体(模型上改进)
综述:我们可以看到作者从普通的tricks,随机翻转这些出发。构造baseline证明了,作者复现的精度是可信的。然后在此基础上,考虑高效率的训练,大BS为背景,主要从学习率角度出发改进,之后改进了ResNet,然后又说了一些训练方法的技巧。
实验实现建立第一个baseline,利用下面的6个步骤,小批量 SGD。下图中reference是模型在其原文中的精度。发现利用下面baseline的方法,复现精度左右稍有偏差,合情合理。
随机采样一张图片,并解码为 32 位的原始像素浮点值,每一个像素值的取值范围为 [0, 255]。
随机以 [3/4, 4/3] 为长宽比、[8%, 100%] 为比例裁减矩形区域,然后再缩放为 224*224 的方图。
以 0.5 的概率随机水平翻转图像。
从均匀分布 [0.6, 1.4] 中抽取系数,并用于缩放色调和明亮度等。
从正态分布 N (0, 0.1) 中采样一个系数,以添加 PCA 噪声。
图像分别通过减去(123.68, 116.779, 103.939),并除以(58.393, 57.12, 57.375)而获得经归一化的 RGB 三通道。
除此之外,我们学习一下自定义初始化~~附赠:

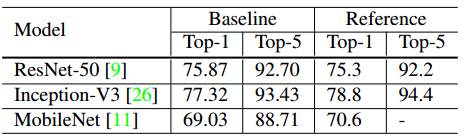
表 2:文献中实现的验证准确率与我们基线模型的验证准确率,注意 Inception V3 的输入图像大小是 299*299。
随着 GPU 等硬件的流行,很多与性能相关的权衡取舍或最优选择都已经发生了改变【例如下面的低精度训练】。在这一章节中,我们研究了能利用低精度和大批量训练优势的多种技术,它们都不会损害模型的准确率,甚至有一些技术还能同时提升准确率与训练速度。
对于凸优化问题,随着批量的增加,收敛速度会降低。对于相同数量的 epoch,大批量训练的模型与使用较小批量训练的模型相比,验证准确率会降低。因此有很多方法与技巧都旨在解决这个问题:
思路:原先BS(batchsize)大的时候,因为凸优化,收敛速度变慢收缩的慢,1000那我可以不可以提高学习率,让收敛的快些呢?
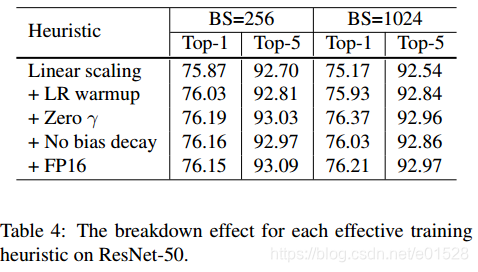
理论依据:BS增大,mini-batch梯度的噪声减少,随机梯度的期望不变,但是方差降低,因此初试学习率可以变大。
实际方法:0.1*bs/256 【对应的,传统的bs=256,初试学习率为0.1,在30 60 90 各变为原来的0.1倍】
为什么:因为刚开始训练,所有的参数都是初始化的结果,离最终差很远,如果采用太大的学习率,容易导致numerical instability
怎么办:在刚开始训练用小学习率预热一下,知道训练稳定后,再变成初始学习率。具体方法:假设初始学习率为0.1,决定让前4个epoch作为预热,那么,学习率分别设置为0.1*i/5,i表示epoch,当然我自己觉得不用那么多预热,我也可以设置前4000个分别为0.02,0.04,0.06 0.08
γx ^ + β.
原理:注意 ResNet 块的最后一层可以是批归一化层(BN)。在 zero γ启发式方法中,我们对所有残差块末端的 BN 层初始化γ=0。因此,所有的残差块仅返回输入值,这相当于网络拥有更少的层,在初始阶段更容易训练。
操作:普通的BN初始化,γ=1,β=0,残差块末端BN的γ=0,β=0。
我不懂的地方,请教诸神一下。到底对应的是下面的哪一个啊,是右边残差块,最下面的一个BN吗?
无偏衰减启发式方法仅应用权重衰减到卷积层和全连接层的权重,其它如 BN 中的γ和β都不进行衰减。原理类似于L2正则化,防止权重过拟合。(具体我也不清楚)
训练更快,有时候甚至更准。。由于硬件的原因和TFLOPS有关。
一般我们用到的是float point 32(FP32),由于硬件的更新,导致FP16,速度会快2-3倍。但是FP32的还没有针对增强。
然而,新硬件可能具有增强的算术逻辑单元以用于较低精度的数据类型。尽管具备性能优势,但是精度降低具有较窄的取值范围,因此有可能出现超出范围而扰乱训练进度的情况。
所以存储参数和计算梯度用FP16,参数更新用,复制了的FP32格式的。【有点不明白,求更清楚的解说】
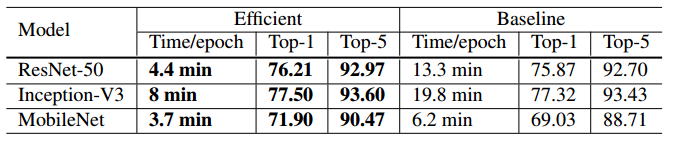
表 3:ResNet-50 在基线(BS = 256 与 FP32)和更高效硬件设置(BS = 1024 与 FP16)之间的训练时间和验证准确率的比较。
注意哈,上面所有的实验都是验证BS大的情况,所以先看BS=1024的情况,BS=256 是对看的。
初试学习率BS=1024对应的是0.4(线性扩展学习率算来的),就算经过了他,BS大的还是比小的-0.9%,要不用估计会更低。
可以看出无偏衰减没卵用啊,对于大的BS,FP16有用,小的不管用。不考虑大BS的话,我们能常用到的就是第二个和第三个了。
![]()
我们将简要介绍 ResNet 架构,特别是与模型变体调整相关的模块。ResNet 网络由一个输入主干、四个后续阶段和一个最终输出层组成,如图 1 所示。输入主干有一个 7×7 卷积,输出通道有 64 个,步幅为 2,接着是 3 ×3 最大池化层,步幅为 2。输入主干(input stem)将输入宽度和高度减小 4 倍,并将其通道尺寸增加到 64。
从阶段 2 开始,每个阶段从下采样块开始,然后是几个残差块。在下采样块中,存在路径 A 和路径 B。路径 A 具有三个卷积,其卷积核大小分别为 1×1、3×3 和 1×1。第一个卷积的步幅为 2,以将输入长度和宽度减半,最后一个卷积的输出通道比前两个大 4 倍,称为瓶颈结构。路径 B 使用步长为 2 的 1×1 卷积将输入形状变换为路径 A 的输出形状,因此我们可以对两个路径的输出求和以获得下采样块的输出。残差块类似于下采样块,除了仅使用步幅为 1 的卷积。
我们可以改变每个阶段中残差块的数量以获得不同的 ResNet 模型,例如 ResNet-50 和 ResNet-152,其中的数字表示网络中卷积层的数量。
1*1的卷积,最好不用于stride=2,降低特征图尺寸用,原文说会丢失3/4的信息(但是精度为什么没有降很多呢?)
resnet-B 就把降低特征图尺寸的任务交给了3*3的卷积。
resnet-C 把最开始的7*7*64大卷积换成下面图中的表示,红体字表示channel。ResNet-50-C这种修改,虽然对计算量影响不大,不过根据我的经验,对速度的影响应该会比较大。
resnet-D 不用1*1的卷积降低特征图尺寸用,用到的x部分。
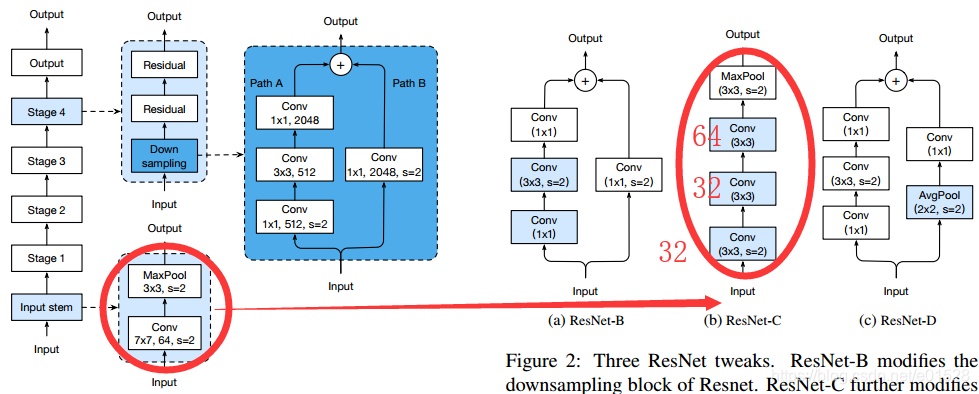
图 2:三个 ResNet 变体。ResNet-B 修改 ResNet 的下采样模块。ResNet-C 进一步修改输入主干。在此基础上,ResNet-D 再次修改了下采样块。
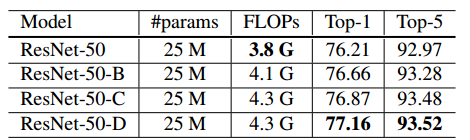
表 5:将 ResNet-50 与三种模型变体进行模型大小(参数数量)、FLOPs 和 ImageNet 验证准确率(top-1、top-5)的比较。
pytorch:scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=5,eta_min=4e-08)
传统的两种衰减:
He et al. [9] decreases rate at 0.1 for every 30 epochs, we call it “step decay”. Szegedy et al. [26]
decreases rate at 0.94 for every two epochs
Loshchilov 等人 [18] 提出余弦退火策略,其简化版本是按照余弦函数将学习速率从初始值降低到 0。假设批次总数为 T(忽略预热阶段),然后在批次 t,学习率η_t 计算如下:

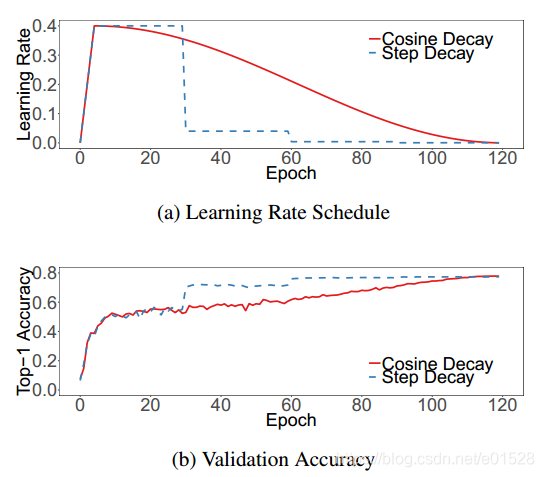
补充:在这里学习到论文里说到的两个迭代之间相差0.94倍。
标签平滑的想法首先被提出用于训练 Inception-v2 [26]。它将真实概率的构造改成:
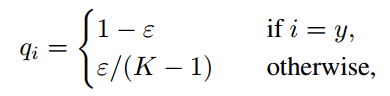
其中ε是一个小常数,K 是标签总数量。
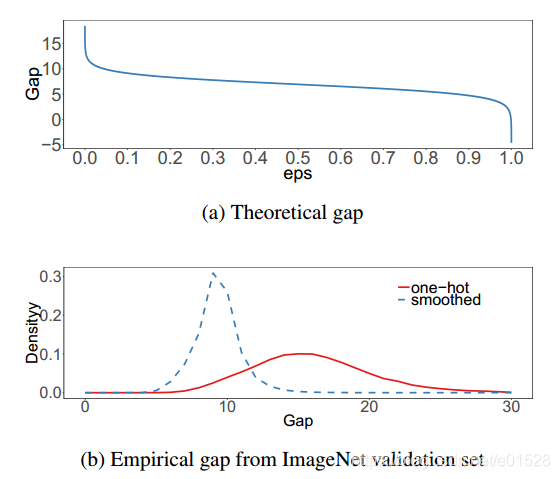
图 4:ImageNet 上标签平滑效果的可视化。顶部:当增加ε时,目标类别与其它类别之间的理论差距减小。下图:最大预测与其它类别平均值之间差距的经验分布。很明显,通过标签平滑,分布中心处于理论值并具有较少的极端值。
调用的时候注意
在知识蒸馏 [10] 中,我们使用教师模型来帮助训练当前模型(被称为学生模型)。教师模型通常是具有更高准确率的预训练模型,因此通过模仿,学生模型能够在保持模型复杂性相同的同时提高其自身的准确率。一个例子是使用 ResNet-152 作为教师模型来帮助训练 ResNet-50。
在混合训练(mixup)中,每次我们随机抽样两个样本 (x_i,y_i) 和 (x_j,y_j)。然后我们通过这两个样本的加权线性插值构建一个新的样本,训练只在新样本中训练:
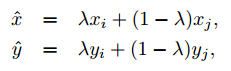
其中 λ∈[0,1] 是从 Beta(α, α) 分布提取的随机数。在混合训练中,我们只使用新的样本 (x hat, y hat)。


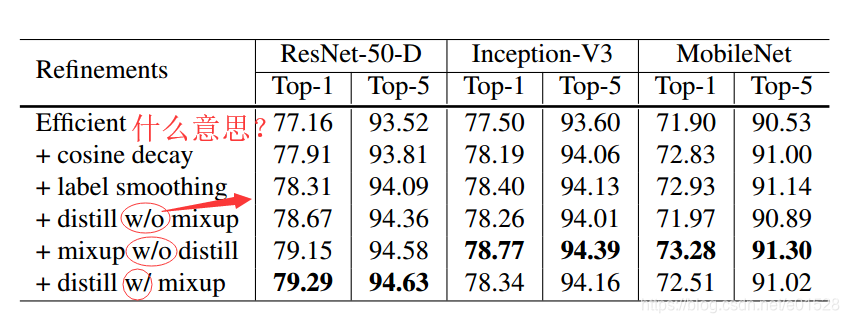
表 6:通过堆叠训练改进方法,得到的 ImageNet 验证准确率。基线模型为第 3 节所描述的。
作者之后又在另外一个数据集上试了下,证明可以。
自 2012 年 AlexNet 大展神威以来,研究者已经提出了各种卷积架构,包括 VGG、NiN、Inception、ResNet、DenseNet 和 NASNet 等,我们会发现模型的准确率正稳定提升。
但是现在这些提升并不仅仅来源于架构的修正,还来源于训练过程的改进:包括损失函数的优化、数据预处理方法的提炼和最优化方法的提升等。在过去几年中,卷积网络与图像分割出现大量的改进,但大多数在文献中只作为实现细节而简要提及,而其它还有一些技巧甚至只能在源代码中找到。
在这篇论文中,李沐等研究者研究了一系列训练过程和模型架构的改进方法。这些方法都能提升模型的准确率,且几乎不增加任何计算复杂度。它们大多数都是次要的「技巧」,例如修正卷积步幅大小或调整学习率策略等。总的来说,采用这些技巧会产生很大的不同。因此研究者希望在多个神经网络架构和数据集上评估它们,并研究它们对最终模型准确率的影响。
研究者的实验表明,一些技巧可以显著提升准确率,且将它们组合在一起能进一步提升模型的准确率。研究者还对比了基线 ResNet 、加了各种技巧的 ResNet、以及其它相关的神经网络,下表 1 展示了所有的准确率对比。这些技巧将 ResNet50 的 Top-1 验证准确率从 75.3%提高到 79.29%,还优于其他更新和改进的网络架构。此外,研究者还表示这些技巧很多都可以迁移到其它领域和数据集,例如目标检测和语义分割等。
训练技巧详解【含有部分代码】Bag of Tricks for Image Classification with Convolutional Neural Networks
标签:不可 原创 实现 pyplot div 很多 有用 文章 view
原文地址:https://www.cnblogs.com/think90/p/11610923.html