标签:反序 地址 ext2 变量 port mamicode print 存储 pickle序列化
我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化
json就是一种序列化的传输手段(json序列化的是字典类型的数据类型)
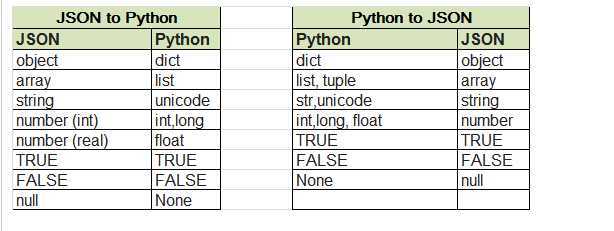
Python把一个字典序列化到一个文本文件中,使用json.dump或者dumps,如下:
import json dic={‘name‘:‘ljj‘,‘age‘:18} data=json.dumps(dic) f=open(‘json_text‘,‘w‘) f.write(data) f.close()
或者如下:
import json dic={‘name‘:‘ljj‘,‘age‘:18} f=open(‘json_text2‘,‘w‘) # data=json.dumps(dic) # f.write(data) json.dump(dic,f) f.close()
dump与dumps的区别就是dumps需要自己将序列化的字典write到文件中,而dump内部已经帮我们做了这一步
从文本文件中读取,使用json.load或者loads,则如下:
import json f = open(‘json_text‘,‘r‘) data=f.read() data=json.loads(data) print(data[‘name‘])
或者如下:
import json f = open(‘json_text2‘,‘r‘) # data=f.read() data=json.load(f) print(data[‘name‘])
load与loads的区别就是loads需要自己将文件中的信息反序列化到内存中再read,而load内部已经帮我们做了这一步
pickle就是一种序列化的传输手段(pickle序列化的是函数和类)
序列化到文件中
import pickle def foo(): print(‘ok‘) data = pickle.dumps(foo) f = open(‘PICKLE_text‘,‘wb‘) f.write(data) f.close()
反序列化到内存里
import pickle def foo(): print(‘ok‘) f = open(‘PICKLE_text‘,‘rb‘) data = f.read() data=pickle.loads(data) data()#需要上面添加foo()函数才不会报错,因为反序列化之后,foo的引用地址会找不到foo函数,需要重新加载
什么是序列化,Python中json的load,loads,dump,dumps和pickle的load,loads,dump,dumps的区别
标签:反序 地址 ext2 变量 port mamicode print 存储 pickle序列化
原文地址:https://www.cnblogs.com/softtester/p/11612498.html