标签:struct char 如何 mod class big 地方 inf byte
参考链接:https://www.liaoxuefeng.com/wiki/1016959663602400/1017685387246080
在使用Python 实现字符向字节数据类型转换的时候,Python没有提供专门处理字节的数据类型,不过Python提供了一个Struct模块提供bytes和其他二进制数据类型的转换
pack(),将任意数据类型转变为bytes数据类型
>>> import struct >>> struct.pack(‘>I‘, 10240099) b‘\x00\x9c@c‘
pack的第一个参数是处理指令,‘>I‘的意思是:
>表示字节顺序是big-endian,也就是网络序,I表示4字节无符号整数。
后面的参数个数要和处理指令一致。如果不一致会报错
>>> struct.pack(‘I‘,‘2‘) Traceback (most recent call last): File "<stdin>", line 1, in <module> struct.error: required argument is not an integer >>>
unpack把bytes变成相应的数据类型:
>>> struct.unpack(‘>IH‘, b‘\xf0\xf0\xf0\xf0\x80\x80‘) (4042322160, 32896)
H代表两个字节的无符号整数,
c代表一个字节的字符
所以,尽管Python不适合编写底层操作字节流的代码,但在对性能要求不高的地方,利用struct就方便多了。
struct模块定义的数据类型可以参考Python官方文档:https://docs.python.org/3/library/struct.html#format-characters
参考链接:https://blog.csdn.net/favory/article/details/4441361
与数据在存储器中的存放地址有关
小端存储:较低的有效字节存放在较低的存储器地址,较高的有效字节存放在较高的存储器地址
大端存储:较高的有效字节存放在较低的存储器地址,较低的有效字节存放在较高的存储器地址
为什么会有较高的有效字节,和较低的有效字节的区分呢?
这是因为目前的计算机系统中,我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为8bit,而C语言中除了有8bit的char外,还有16bit的short类型,还用32bit的long类型(不同的编译器还不一样),那么加入我们存放一个长度32bit的整数:
(由于一个地址单元是8bit,需要将这个长度为32bit的数据存放在4个地址单元中)
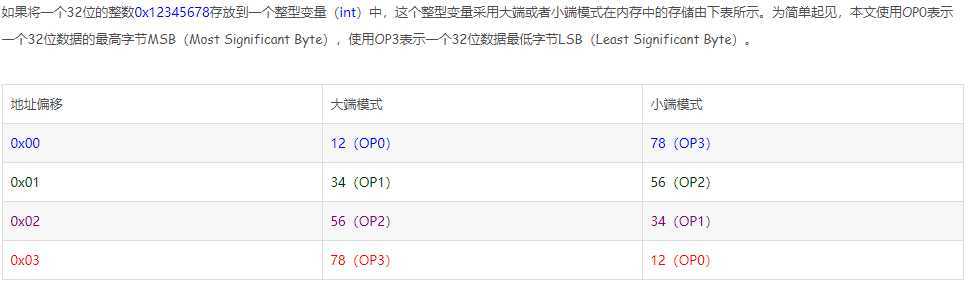
另外,对于16位或者32位的这些寄存器长度大于8位的处理器,由于寄存器的宽度大于一个内存地址,也面临这一个如何将多个字节安排的问题。
标签:struct char 如何 mod class big 地方 inf byte
原文地址:https://www.cnblogs.com/Gaoqiking/p/11614333.html