标签:-- 方向 creat 条件查询 等于 style alt loaded end
1.普通索引:加速查找 2.主键索引:加速查找 + 约束(不能为空) + 唯一 3.唯一索引:加速查找 + 唯一 4.联合索引(多列) - 联合主键索引 - 联合唯一索引 - 联合普通索引 ‘‘‘ 前三个是单列(字段)索引 ‘‘‘
#不同的存储引擎支持的索引类型也不一样 InnoDB 支持事务,支持行级别锁定,支持 B-tree、Full-text 等索引,不支持 Hash 索引; MyISAM 不支持事务,支持表级别锁定,支持 B-tree、Full-text 等索引,不支持 Hash 索引; Memory 不支持事务,支持表级别锁定,支持 B-tree、Hash 等索引,不支持 Full-text 索引; NDB 支持事务,支持行级别锁定,支持 Hash 索引,不支持 B-tree、Full-text 等索引; Archive 不支持事务,支持表级别锁定,不支持 B-tree、Hash、Full-text 等索引;
# 缺点:因为hash数值是随机生成的,导致了存在hash索引表中的数据的无序,所以如果当你要查找id大于5(范围)的数据时,就会慢了 # 优点:找单值速度快
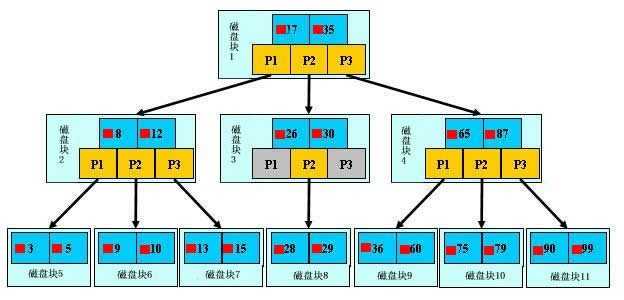
如上图,是一颗b+树,关于b+树的定义可以参见B+树,这里只说一些重点,浅蓝色的块我们称之为一个磁盘块,可以看到每个磁盘块包含几个数据项(深蓝色所示)和指针(黄色所示),如磁盘块1包含数据项17和35,包含指针P1、P2、P3,P1表示小于17的磁盘块,P2表示在17和35之间的磁盘块,P3表示大于35的磁盘块。真实的数据存在于叶子节点即3、5、9、10、13、15、28、29、36、60、75、79、90、99。非叶子节点只不存储真实的数据,只存储指引搜索方向的数据项,如17、35并不真实存在于数据表中。
如图所示,如果要查找数据项29,那么首先会把磁盘块1由磁盘加载到内存,此时发生一次IO,在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针,内存时间因为非常短(相比磁盘的IO)可以忽略不计,通过磁盘块1的P2指针的磁盘地址把磁盘块3由磁盘加载到内存,发生第二次IO,29在26和30之间,锁定磁盘块3的P2指针,通过指针加载磁盘块8到内存,发生第三次IO,同时内存中做二分查找找到29,结束查询,总计三次IO。真实的情况是,3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,性能提高将是巨大的,如果没有索引,每个数据项都要发生一次IO,那么总共需要百万次的IO,显然成本非常非常高。
1.索引字段要尽量的小:通过上面的分析,我们知道IO次数取决于b+数的高度h,假设当前数据表的数据为N,每个磁盘块的数据项的数量是m,则有h=㏒(m+1)N,当数据量N一定的情况下,m越大,h越小;而m = 磁盘块的大小 / 数据项的大小,磁盘块的大小也就是一个数据页的大小,是固定的,如果数据项占的空间越小,数据项的数量越多,树的高度越低。这就是为什么每个数据项,即索引字段要尽量的小,比如int占4字节,要比bigint8字节少一半。这也是为什么b+树要求把真实的数据放到叶子节点而不是内层节点,一旦放到内层节点,磁盘块的数据项会大幅度下降,导致树增高。当数据项等于1时将会退化成线性表。
2.索引的最左匹配特性:当b+树的数据项是复合的数据结构,比如(name,age,sex)的时候,b+数是按照从左到右的顺序来建立搜索树的,比如当(张三,20,F)这样的数据来检索的时候,b+树会优先比较name来确定下一步的所搜方向,如果name相同再依次比较age和sex,最后得到检索的数据;但当(20,F)这样的没有name的数据来的时候,b+树就不知道下一步该查哪个节点,因为建立搜索树的时候name就是第一个比较因子,必须要先根据name来搜索才能知道下一步去哪里查询。比如当(张三,F)这样的数据来检索时,b+树可以用name来指定搜索方向,但下一个字段age的缺失,所以只能把名字等于张三的数据都找到,然后再匹配性别是F的数据了, 这个是非常重要的性质,即索引的最左匹配特性。
优点:查询速度快(命中索引)
缺点:更新,删除数据变慢,因为要重新编排索引文件
1.创建普通索引: 方式一: create table in1( nid int not null auto_increment primary key, name varchar(32) not null, email varchar(64) not null, extra text, index ix_name (name) ) 方式二: create index ix_name on 表名(emil); # 给emil字段创建索引,取名ix_name 删除普通索引: drop index ix_name on 表名 查看索引: show index from table_name; ‘‘‘ ps: 创建索引会创建额外的文件占用硬盘空间 ‘‘‘
2.创建唯一索引 方式一: create table in1( nid int not null auto_increment primary key, name varchar(32) not null, email varchar(64) not null, extra text, unique ix_name (name) ) 方式二: create unique index 索引名 on 表名(列名) 删除唯一索引 drop unique index 索引名 on 表名
3.创建主键索引 方式一: create table in1( nid int not null auto_increment primary key, name varchar(32) not null, email varchar(64) not null, extra text, index ix_name (name) ) ? 方式二: create table in1( nid int not null auto_increment, name varchar(32) not null, email varchar(64) not null, extra text, primary key(ni1), index ix_name (name) ) 方式三: alter table 表名 add primary key(列名); 删除主键索引: 1.alter table 表名 drop primary key; 2.alter table 表名 modify 列名 int, drop primary key;
4.创建组合索引 方式一: create table in3( nid int not null auto_increment primary key, name varchar(32) not null, email varchar(64) not null, extra text ) 方式二: create index ix_name_email on in3(name,email); ‘‘‘ 其应用场景为:频繁的同时使用n列来进行查询,如:where name = ‘xionger‘ and email = 666@qq.com。 ‘‘‘ 补充: 最左前缀匹配: create index ix_name_email on userinfo(name,email); ? select * from userinfo where name=‘xionger‘; # 走索引 select * from userinfo where name=‘xionger‘ and emil=‘111@qq.com‘; # 走索引 select * from userinfo where emil=‘111@qq,com‘; # 不走索引
例: id为一张表的索引字段 select * from userinfo where id = 666; select id from userinfo where id = 666; # 覆盖索引
把多个单列索引合并着使用
例:id和emil是一张表的两个单列索引 select * from userinfo where id = 666 and emil = 111@qq.com; 补充: 组合索引效率 > 合并索引
会将所有的字段都生成索引,但在生长的时候不会这么做,会借助第三方数据库操作
例: id 和 emil 是一张表中的两个单列索引 - like ‘%xx‘ # 数据量小可以使用,数据量多避免使用,可以使用第三方工具 select * from tb1 where name like ‘%cn‘; - 避免使用函数 select * from tb1 where reverse(name) = ‘wupeiqi‘; - or select * from tb1 where nid = 1 or email = ‘seven@live.com‘; 特别的:当or条件中有未建立索引的列才失效,以下会走索引 select * from tb1 where nid = 1 or name = ‘seven‘; # 不走索引 select * from tb1 where nid = 1 or email = ‘seven@live.com‘ and name = ‘alex‘ # 走索引 - 类型不一致 如果列是字符串类型,传入条件是必须用引号引起来,不然... select * from tb1 where name = 999; - != select * from tb1 where name != ‘alex‘ 特别的:如果是主键,则还是会走索引 select * from tb1 where nid != 123 - > select * from tb1 where name > ‘alex‘ 特别的:如果是主键或索引是整数类型,则还是会走索引 select * from tb1 where nid > 123 select * from tb1 where num > 123 - order by select email from tb1 order by name desc; 当根据索引排序时候,选择的映射如果不是索引,则不走索引 特别的:如果对主键排序,则还是走索引: select * from tb1 order by nid desc; - 组合索引最左前缀 如果组合索引为:(name,email) name and email -- 使用索引 name -- 使用索引 email -- 不使用索引
create index ix_name on 表名(字段(4)) # 其中4表示取该字段数据的前4个字符做索引 需要用局部索引的类型: text
- 避免使用select * - count(1)或count(列) 代替 count(*) - 创建表时尽量时 char 代替 varchar - 表的字段顺序固定长度的字段优先 - 组合索引代替多个单列索引(经常使用多个条件查询时) - 尽量使用短索引 - 使用连接(JOIN)来代替子查询(Sub-Queries) - 连表时注意条件类型需一致 - 索引散列值(重复少)不适合建索引,例:性别不适合
标签:-- 方向 creat 条件查询 等于 style alt loaded end
原文地址:https://www.cnblogs.com/waller/p/11615508.html