标签:优化器 部分 结构 适用于 正文 手动 简单 大小 sql查询
hash join是一种数据库在进行多表连接时的处理算法,对于多表连接还有两种比较常用的方式:sort merge-join 和 nested loop。 为了比较清楚的介绍hash join的使用场景以及为何要引入这样一种连接算法,这里也会顺带简单介绍一下上面提到的两种join方式。
连接方式是一个什么样的概念,或者说我们为何要有而且有好几种,对于不太了解数据库的人来讲可能这些是开头的疑惑。简单来讲,我们将数据存在不同的表中,而不同的表有着它们自身的表结构,不同表之间可以是有关联的,大部分实际使用中,不会仅仅只需要一张表的信息,比如需要从一个班级表中找出杭州地区的学生,再用这个信息去检索成绩表中他们的数学成绩,如果没有多表连接,那只能手动将第一个表的信息查询出来作为第二个表的检索信息去查询最终的结果,可想而知这将会是多么繁琐。
对于几个常见的数据库,像oracle,postgresql它们都是支持hash-join的,mysql并不支持。在这方面,oracle和pg都已经做的比较完善了,hash-join本身的实现并不是很复杂,但是它需要优化器的实现配合才能最大的发挥本身的优势,我觉得这才是最难的地方。
多表连接的查询方式又分为以下几种:内连接,外连接和交叉连接。外连接又分为:左外连接,右外连接和全外连接。对于不同的查询方式,使用相同的join算法也会有不同的代价产生,这个是跟其实现方式紧密相关的,需要考虑不同的查询方式如何实现,对于具体使用哪一种连接方式是由优化器通过代价的衡量来决定的,后面会简单介绍一下几种连接方式代价的计算。 hashjoin其实还有很多需要考虑和实现的地方,比如数据倾斜严重如何处理、内存放不下怎木办,hash如何处理冲突等,这些并不是本文介绍的重点,不再详述,每个拿出来都可以再讲一篇了。
nested loop join
嵌套循环连接,是比较通用的连接方式,分为内外表,每扫描外表的一行数据都要在内表中查找与之相匹配的行,没有索引的复杂度是O(N*M),这样的复杂度对于大数据集是非常劣势的,一般来讲会通过索引来提升性能。
sort merge-join
merge join需要首先对两个表按照关联的字段进行排序,分别从两个表中取出一行数据进行匹配,如果合适放入结果集;不匹配将较小的那行丢掉继续匹配另一个表的下一行,依次处理直到将两表的数据取完。merge join的很大一部分开销花在排序上,也是同等条件下差于hash join的一个主要原因。
简单的对于两个表来讲,hash-join就算讲两表中的小表(称S)作为hash表,然后去扫描另一个表(称M)的每一行数据,用得出来的行数据根据连接条件去映射建立的hash表,hash表是放在内存中的,这样可以很快的得到对应的S表与M表相匹配的行。
对于结果集很大的情况,merge-join需要对其排序效率并不会很高,而nested loop join是一种嵌套循环的查询方式无疑更不适合大数据集的连接,而hash-join正是为处理这种棘手的查询方式而生,尤其是对于一个大表和一个小表的情况,基本上只需要将大小表扫描一遍就可以得出最终的结果集。
不过hash-join只适用于等值连接,对于>, <, <=, >=这样的查询连接还是需要nested loop这种通用的连接算法来处理。如果连接key本来就是有序的或者需要排序,那么可能用merge-join的代价会比hash-join更小,此时merge-join会更有优势。
好了,废话说了不少了,来讲讲实现,拿一条简单的多表sql查询语句来举个栗子:select * from t1 join t2 on t1.c1 = t2.c1 where t1.c2 > t2.c2 and t1.c1 > 1。这样一条sql进入数据库系统中,它是如何被处理和解剖的呢?sql:鬼知道我都经历了些什么。。。
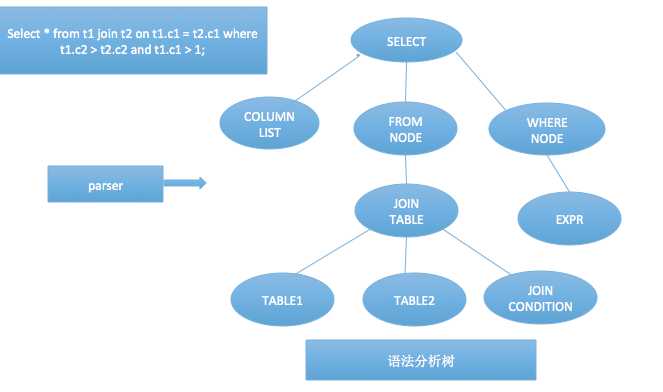
语法分析,顾名思义这部分只是语法层面的剖析,将一个string的sql语句处理成为一颗有着雏形结构的node tree,每个结点有它们自身的特殊标识,但是并没有分析和处理这个结点的具体含义和值。
重写的过程不同的数据库可能有不同的处理,有些可能是跟逻辑执行过程放在一起,有的则分开。
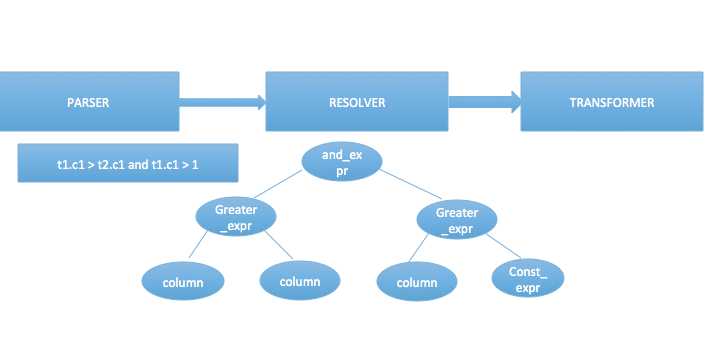
这一步做完树的形状大体上是与语法分析树保持一致的,但是此时的结点都携带了一些具体的信息,以where后面的表达式为例,这颗中缀表达式每一个结点都有了自身的类型和特定的信息,并不关心值是什么,这步做完后进入改写过程,改写是一种逻辑优化方式,使得一些复杂的sql语句变得更简单或者更符合数据库的处理流程。
优化器的处理是比较复杂的,也是sql模块最难的地方,优化无止境,所以优化器没有最优只有更优。优化器需要考虑方方面面的因素既要做的通用型很强又要保证很强的优化能力和正确性。
优化器最重要的作用莫过于路径选择了,对于多表连接如何确定表连接的顺序和连接方式,不同的数据库有着不同的处理方式,pg支持动态规划算法,表数量过多的时候使用遗传算法。路径的确定又依赖于代价模型的实现,代价模型会维护一些统计信息,像列的最大值、最小值、NDV和DISTINCT值等,通过这些信息可以计算选择率从而进一步计算代价。

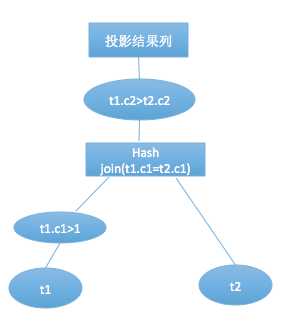
回归到正文,使用哪一种连接方式就是在这里决定的,hash join 对大小表是有要求的,所以这里形成的计划是t1-t2还是t2-t1是不一样的,每种连接方式有着自身的代价计算方式。
hash join的代价估算:
COST = BUILD_COST + M_SCAN_COST + JOIN_CONDITION_COST + FILTER_COST
简单来看,hash join的代价主要在于建立hash表、扫描M表、join条件连接和filter过滤,对于S表和M表都是只需要扫描一次即可,filter过滤是指t1.c2>t2.c2这样的条件过滤,对于t1.c1>1这样只涉及单表的条件会被下压,在做连接之前就被过滤了。
优化器处理过后,会生成一颗执行计划树,真正的实现过程根据执行计划的流程操作数据,由低向上地递归处理并返回数据。
hash join的实现分为build table也就是被用来建立hash map的小表和probe table,首先依次读取小表的数据,对于每一行数据根据连接条件生成一个hash map中的一个元組,数据缓存在内存中,如果内存放不下需要dump到外存。依次扫描探测表拿到每一行数据根据join condition生成hash key映射hash map中对应的元組,元組对应的行和探测表的这一行有着同样的hash key, 这时并不能确定这两行就是满足条件的数据,需要再次过一遍join condition和filter,满足条件的数据集返回需要的投影列。
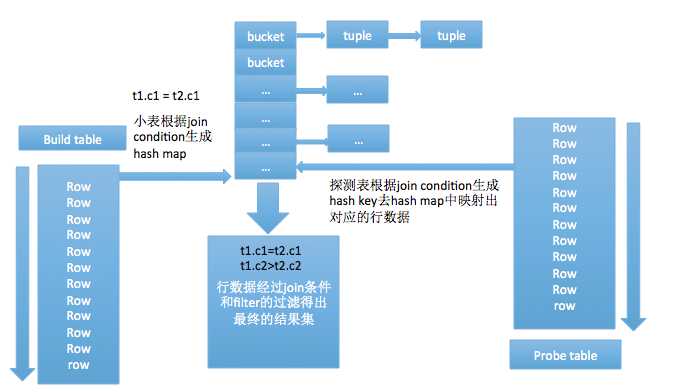
1.hash join本身的实现不要去判断哪个是小表,优化器生成执行计划时就已经确定了表的连接顺序,以左表为小表建立hash table,那对应的代价模型就会以左表作为小表来得出代价,这样根据代价生成的路径就是符合实现要求的。
2.hash table的大小、需要分配多少个桶这个是需要在一开始就做好的,那分配多少是一个问题,分配太大会造成内存浪费,分配太小会导致桶数过小开链过长性能变差,一旦超过这里的内存限制,会考虑dump到外存,不同数据库有它们自身的实现方式。
3.如何对数据hash,不同数据库有着自己的方式,不同的哈希方法也会对性能造成一定的影响。
标签:优化器 部分 结构 适用于 正文 手动 简单 大小 sql查询
原文地址:https://www.cnblogs.com/echojson/p/11615549.html