标签:长度 enc etop sig 相关 系统 两种 纪元 pool
在本章中,将会学到:
l 如何使用Kelp.Net来执行自己的测试
l 如何编写测试
l 如何对函数进行基准测试
Kelp.Net是一个用c#编写的深度学习库。由于能够将函数链到函数堆栈中,它在一个非常灵活和直观的平台中提供了惊人的功能。它还充分利用OpenCL语言平台,在支持cpu和gpu的设备上实现无缝操作。深度学习是一个非常强大的工具,对Caffe和Chainer模型加载的本机支持使这个平台更加强大。您将看到,只需几行代码就可以创建一个100万个隐藏层的深度学习网络。
Kelp.Net还使得从磁盘存储中保存和加载模型变得非常容易。这是一个非常强大的特性,允许您执行训练、保存模型,然后根据需要加载和测试。它还使代码的产品化变得更加容易,并且真正地将训练和测试阶段分离开来。
其中,Kelp.Net是一个非常强大的工具,可以帮助你更好地学习和理解各种类型的函数、它们的交互和性能。例如,你可以使用不同的优化器在相同的网络上运行测试,并通过更改一行代码来查看结果。此外,可以轻松地设计你的测试,以查看使用不同批处理大小、隐藏层数、纪元、和更多内容。
深度学习是机器学习和人工智能的一个分支,它使用许多层次的神经网络层(如果你愿意,可以称之为层次结构)来完成它的工作。在很多情况下,这些网络的建立是为了反映我们对人类大脑的认知,神经元像错综复杂的网状结构一样将不同的层连接在一起。这允许以非线性的方式进行数据处理。每一层都处理来自上一层的数据(当然,第一层除外),并将其信息传递到下一层。幸运的话,每一层都改进了模型,最终,我们实现了目标并解决了问题。
Kelp.Net 大量使用了开源计算语言(OpenCL).
OpenCL认为计算系统是由许多计算设备组成的,这些计算设备可以是中央处理器(CPU),也可以是附加在主机处理器(CPU)上的图形处理单元(GPU)等加速器。在OpenCL设备上执行的函数称为内核。单个计算设备通常由几个计算单元组成,这些计算单元又由多个处理元素(PS)组成。一个内核执行可以在所有或多个PEs上并行运行。
在OpenCL中,任务是在命令队列中调度的。每个设备至少有一个命令队列。OpenCL运行时将调度数据的并行任务分成几部分,并将这些任务发送给设备处理元素。
OpenCL定义了一个内存层次结构:
Global:由所有处理元素共享,并且具有高延迟。
Read-only:更小,更低的延迟,可由主机CPU写入,但不包括计算设备。
Local:由流程元素组共享。
Per-elemen:私有内存。
OpenCL还提供了一个更接近数学的API。这可以在固定长度向量类型的公开中看到,比如float4(单精度浮点数的四个向量),它的长度为2、3、4、8和16。如果你接触了更多的Kelp.Net并开始创建自己的函数,你将会遇到OpenCL编程。现在,只要知道它的存在就足够了,而且它正在被广泛地使用。
在Kelp.Net各种OpenCL资源的层次结构如下图所示:
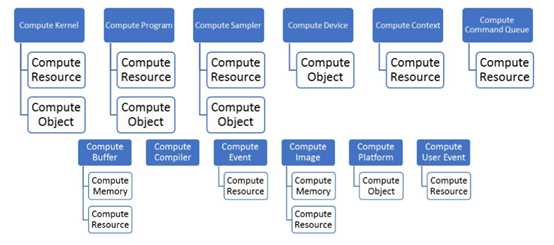
让我们更详细地描述这些。
Compute kernel
内核对象封装在程序中声明的特定内核函数,以及执行此内核函数时使用的参数值。
Compute program
由一组内核组成的OpenCL程序。程序还可以包含内核函数和常量数据调用的辅助函数。
Compute sampler
描述如何在内核中读取图像时对图像进行采样的对象。图像读取函数以采样器作为参数。采样器指定图像寻址模式(表示如何处理范围外的坐标)、过滤模式以及输入图像坐标是规范化还是非规范化值。
Compute device
计算设备是计算单元的集合。命令队列用于将命令排队到设备。命令示例包括执行内核或读写内存对象。OpenCL设备通常对应于GPU、多核CPU和其他处理器,如数字信号处理器(DSP)和cell/B.E.处理器。
Compute resource
可以由应用程序创建和删除的OpenCL资源。
Compute object
在OpenCL环境中由句柄标识的对象。
Compute context
计算上下文是内核执行的实际环境和定义同步和内存管理的域。
Compute command queue
命令队列是一个对象,它包含将在特定设备上执行的命令。命令队列是在上下文中的特定设备上创建的。对队列的命令按顺序排队,但可以按顺序执行,也可以不按顺序执行。
Compute buffer
存储线性字节集合的内存对象。可以使用在设备上执行的内核中的指针来访问缓冲区对象。
Compute event
事件封装了操作(如命令)的状态。它可用于同步上下文中的操作。
Compute image
存储2D或3D结构数组的内存对象。图像数据只能通过读写函数访问。读取函数使用采样器。
Compute platform
主机加上OpenCL框架管理的设备集合,允许应用程序共享资源并在平台上的设备上执行内核。
Compute user event
这表示用户创建的事件。
函数是Kelp.Net神经网络的基本组成部分。单个函数在函数堆栈中链接在一起,以创建功能强大且可能复杂的网络链。
我们需要了解四种主要的函数类型:
Single-input functions 单输入函数
Dual-input
functions 双输入函数
Multi-input
functions 多输入函数
Multi-output
functions 多输出函数
当从磁盘加载网络时,函数也被链接在一起。
每个函数都有一个向前和向后的方法。
public abstract NdArray[] Forward(params NdArray[] xs); public virtual void Backward([CanBeNull] params NdArray[] ys){}
函数堆栈是在向前、向后或更新传递中同时执行的函数层。当我们创建一个测试或从磁盘加载一个模型时,将创建函数堆栈。下面是一些函数堆栈的例子。
它们可以小而简单:
FunctionStack nn = new FunctionStack( new Linear(2, 2, name: "l1 Linear"), new Sigmoid(name: "l1 Sigmoid"), new Linear(2, 2, name: "l2 Linear"));
它们也可以在大一点:
FunctionStack nn = new FunctionStack( // Do not forget the GPU flag if necessary new Convolution2D(1, 2, 3, name: "conv1", gpuEnable: true), new ReLU(), new MaxPooling(2, 2), new Convolution2D(2, 2, 2, name: "conv2", gpuEnable: true), new ReLU(), new MaxPooling(2, 2), new Linear(8, 2, name: "fl3"), new ReLU(), new Linear(2, 2, name: "fl4") );
它们也可以非常大:
FunctionStack nn = new FunctionStack( new Linear(neuronCount * neuronCount, N, name: "l1 Linear"),//L1 new BatchNormalization(N, name: "l1 BatchNorm"), new LeakyReLU(slope: 0.000001, name: "l1 LeakyReLU"), new Linear(N, N, name: "l2 Linear"), // L2 new BatchNormalization(N, name: "l2 BatchNorm"), new LeakyReLU(slope: 0.000001, name: "l2 LeakyReLU"), new Linear(N, N, name: "l3 Linear"), // L3 new BatchNormalization(N, name: "l3 BatchNorm"), new LeakyReLU(slope: 0.000001, name: "l3 LeakyReLU"), new Linear(N, N, name: "l4 Linear"), // L4 new BatchNormalization(N, name: "l4 BatchNorm"), new LeakyReLU(slope: 0.000001, name: "l4 LeakyReLU"), new Linear(N, N, name: "l5 Linear"), // L5 new BatchNormalization(N, name: "l5 BatchNorm"), new LeakyReLU(slope: 0.000001, name: "l5 LeakyReLU"), new Linear(N, N, name: "l6 Linear"), // L6 new BatchNormalization(N, name: "l6 BatchNorm"), new LeakyReLU(slope: 0.000001, name: "l6 LeakyReLU"), new Linear(N, N, name: "l7 Linear"), // L7 new BatchNormalization(N, name: "l7 BatchNorm"), new LeakyReLU(slope: 0.000001, name: "l7 ReLU"), new Linear(N, N, name: "l8 Linear"), // L8 new BatchNormalization(N, name: "l8 BatchNorm"), new LeakyReLU(slope: 0.000001, name: "l8 LeakyReLU"), new Linear(N, N, name: "l9 Linear"), // L9 new BatchNormalization(N, name: "l9 BatchNorm"), new PolynomialApproximantSteep(slope: 0.000001, name: "l9 PolynomialApproximantSteep"), new Linear(N, N, name: "l10 Linear"), // L10 new BatchNormalization(N, name: "l10 BatchNorm"), new PolynomialApproximantSteep(slope: 0.000001, name: "l10 PolynomialApproximantSteep"), new Linear(N, N, name: "l11 Linear"), // L11 new BatchNormalization(N, name: "l11 BatchNorm"), new PolynomialApproximantSteep(slope: 0.000001, name: "l11 PolynomialApproximantSteep"), new Linear(N, N, name: "l12 Linear"), // L12 new BatchNormalization(N, name: "l12 BatchNorm"), new PolynomialApproximantSteep(slope: 0.000001, name: "l12 PolynomialApproximantSteep"), new Linear(N, N, name: "l13 Linear"), // L13 new BatchNormalization(N, name: "l13 BatchNorm"), new PolynomialApproximantSteep(slope: 0.000001, name: "l13 PolynomialApproximantSteep"), new Linear(N, N, name: "l14 Linear"), // L14 new BatchNormalization(N, name: "l14 BatchNorm"), new PolynomialApproximantSteep(slope: 0.000001, name: "l14 PolynomialApproximantSteep"), new Linear(N, 10, name: "l15 Linear") // L15 );
函数字典是一个可序列化的函数字典(如前所述)。当从磁盘加载网络模型时,将返回一个函数字典,并且可以像在代码中创建函数堆栈一样对其进行操作。函数字典主要用于Caffe数据模型加载器。
Kelp.Net是围绕Caffe风格开发的,它支持许多特性。
Caffe为多媒体科学家和实践者提供了一个简洁和可修改的框架,用于最先进的深度学习算法和一组参考模型。该框架是一个bsd许可的c++库,带有Python和MATLAB绑定,用于在普通架构上高效地培训和部署通用卷积神经网络和其他深度模型。Caffe通过CUDA GPU计算满足了行业和互联网规模的媒体需求,在一个K40或Titan GPU上每天处理超过4000万张图像(大约每张图像2毫秒)。通过分离模型表示和实际实现,Caffe允许在平台之间进行试验和无缝切换,以简化开发和部署,从原型机到云环境。
“Chainer是一个灵活的神经网络框架。一个主要的目标是灵活性,因此它必须使我们能够简单而直观地编写复杂的体系结构。”
Chainer采用了按运行定义的方案,即通过实际的正向计算动态地定义网络。更准确地说,Chainer存储的是计算历史,而不是编程逻辑。例如,Chainer不需要任何东西就可以将条件和循环引入到网络定义中。按运行定义方案是Chainer的核心概念。这种策略也使得编写多gpu并行化变得容易,因为逻辑更接近于网络操作。
Kelp.Net可以直接从磁盘加载Chainer模型。
Kelp.Net由一个抽象的LossFunction类组成,设计用于确定如何评估损失的特定实例。
在机器学习中,损失函数或成本函数是将一个事件或一个或多个变量的值直观地映射到一个实数上的函数,表示与该事件相关的一些成本。Kelp.Net提供了两个开箱即用的损失函数:均方误差和软最大交叉熵。我们可以很容易地扩展它们以满足我们的需求。
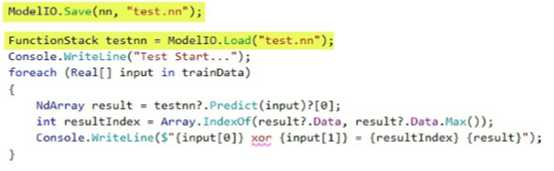
Kelp.Net使得通过调用一个简单的类来保存和加载模型变得非常容易。ModelIO类同时提供了保存和加载方法,以便轻松地保存和加载到磁盘。下面是一个非常简单的例子,在训练、重新加载并对模型执行测试之后保存模型:
优化算法根据模型的参数最小化或最大化误差函数。参数的例子有权重和偏差。它们通过最小化损失来帮助计算输出值并将模型更新到最优解的位置。扩展Kelp.Net以添加我们自己的优化算法是一个简单的过程,尽管添加OpenCL和资源方面的东西是一个协调的工作。
Kelp.Net提供了许多预定义的优化器,比如:
AdaDelta
AdaGrad
Adam
GradientClipping
MomentumSGD
RMSprop
SGD
这些都是基于抽象的优化器类。
Kelp.Net本身支持以下数据集:
CIFAR
MNIST
CIFAR
CIFAR数据集有两种形式,CIFAR-10和CIFAR 100,它们之间的区别是类的数量。让我们简要地讨论一下两者。
CIFAR-10
CIFAR-10数据集包含10个类中的60000张32×32张彩色图像,每个类包含6000张图像。有50,000张训练图像和10,000张测试图像。数据集分为五个训练批次和一个测试批次,每个测试批次有10,000张图像。测试批次包含从每个类中随机选择的1000个图像。训练批次包含随机顺序的剩余图像,但是一些训练批次可能包含一个类的图像多于另一个类的图像。在他们之间,每批训练包含了5000张图片。
CIFAR-100
CIFAR-100数据集与CIFAR-10一样,只是它有100个类,每个类包含600个图像。每班有500张训练图片和100张测试图片。CIFAR-100中的100个类被分为20个超类。每个图像都有一个细标签(它所属的类)和一个粗标签(它所属的超类)。以下是CIFAR-100的类型列表:
|
Superclass |
Classes |
|
水生哺乳动物 |
海狸、海豚、水獭、海豹和鲸鱼 |
|
鱼 |
水族鱼,比目鱼,鳐鱼,鲨鱼和鱼 |
|
花 |
兰花、罂粟、玫瑰、向日葵和郁金香 |
|
食品容器 |
瓶子、碗、罐子、杯子和盘子 |
|
水果和蔬菜 |
苹果、蘑菇、桔子、梨和甜椒 |
|
家用电器设备 |
时钟、电脑键盘、灯、电话和电视 |
|
家用家具 |
床、椅子、沙发、桌子和衣柜 |
|
昆虫 |
蜜蜂、甲虫、蝴蝶、毛虫和蟑螂 |
|
大型食肉动物 |
熊、豹、狮子、老虎和狼 |
|
大型人造户外用品 |
桥、城堡、房子、道路和摩天大楼 |
|
大型自然户外景观 |
云、林、山、平原、海 |
|
大型杂食动物和食草动物 |
骆驼、牛、黑猩猩、大象和袋鼠 |
|
中等大小的哺乳动物 |
狐狸,豪猪,负鼠,浣熊和臭鼬 |
|
无脊椎动物 |
螃蟹、龙虾、蜗牛、蜘蛛和蠕虫 |
|
人 |
宝贝,男孩,女孩,男人,女人 |
|
爬行动物 |
鳄鱼、恐龙、蜥蜴、蛇和乌龟 |
|
小型哺乳动物 |
仓鼠,老鼠,兔子,鼩鼱和松鼠 |
|
树 |
枫树、橡树、棕榈树、松树和柳树 |
|
车辆1 |
自行车、公共汽车、摩托车、小货车和火车 |
|
车辆2 |
割草机、火箭、有轨电车、坦克和拖拉机 |
MNIST
MNIST数据库是一个手写数字的大型数据库,通常用于训练各种图像处理系统。该数据库还广泛用于机器学习领域的培训和测试。它有一个包含6万个例子的训练集和一个包含1万个例子的测试集。数字的大小已经标准化,并集中在一个固定大小的图像中,这使它成为人们想要尝试各种学习技术而不需要进行预处理和格式化的标准选择:

测试是实际的执行事件,也可以说是小程序。由于OpenCL的使用,这些程序是在运行时编译的。要创建一个测试,您只需要提供一个封装代码的静态运行函数。Kelp.Net提供了一个预配置的测试器,这使得添加我们自己的测试变得非常简单。
现在,这里有一个简单的XOR测试程序的例子:
public static void Run() { const int learningCount = 10000; Real[][] trainData = { new Real[] { 0, 0 }, new Real[] { 1, 0 }, new Real[] { 0, 1 }, new Real[] { 1, 1 } }; Real[][] trainLabel = { new Real[] { 0 }, new Real[] { 1 }, new Real[] { 1 }, new Real[] { 0 } }; FunctionStack nn = new FunctionStack( new Linear(2, 2, name: "l1 Linear"), new ReLU(name: "l1 ReLU"), new Linear(2, 1, name: "l2 Linear")); nn.SetOptimizer(new AdaGrad()); RILogManager.Default?.SendDebug("Training..."); for (int i = 0; i < learningCount; i++) { //use MeanSquaredError for loss function Trainer.Train(nn,trainData[0],trainLabel[0],newMeanSquaredError(), false); Trainer.Train(nn, trainData[1], trainLabel[1], new MeanSquaredError(), false); Trainer.Train(nn, trainData[2], trainLabel[2], new MeanSquaredError(), false); Trainer.Train(nn, trainData[3], trainLabel[3], new MeanSquaredError(), false); //If you do not update every time after training, you can update it as a mini batch nn.Update(); } RILogManager.Default?.SendDebug("Test Start..."); foreach (Real[] val in trainData) { NdArray result = nn.Predict(val)[0]; RILogManager.Default?.SendDebug($"{val[0]} xor {val[1]} = {(result.Data[0] > 0.5 ? 1 : 0)} {result}"); } }
Weaver是Kelp.Net的重要组成部分。是运行测试时要执行的第一个对象调用。这个对象包含各种OpenCL对象,比如:
l 计算上下文
l 一组计算设备
l 计算命令队列
l 一个布尔标志,表明GPU是否为启用状态
l 可核心计算资源的字典
Weaver是用来告诉我们的程序我们将使用CPU还是GPU,以及我们将使用哪个设备(如果我们的系统能够支持多个设备)的地方。我们只需要在我们的程序开始时对Weaver做一个简单的调用,就像在这里看到的:
Weaver.Initialize(ComputeDeviceTypes.Gpu);
我们还可以避免使用weaver的初始化调用,并允许它确定需要自动发生什么。
以下是Weaver的基本内容。它的目的是构建(在运行时动态编译)将执行的程序:
///<summary>上下文</summary> internal static ComputeContext Context; ///<summary>设备</summary> private static ComputeDevice[] Devices; ///<summary>命令队列</summary> internal static ComputeCommandQueue CommandQueue; ///<summary>设备的从零开始索引</summary> private static int DeviceIndex; ///<summary>True启用,false禁用</summary> internal static bool Enable; ///<summary>平台</summary> private static ComputePlatform Platform; ///<summary>核心资源</summary> private static readonly Dictionary<string, string> KernelSources = new Dictionary<string, string>();
为Kelp.Net创建测试非常简单。我们编写的每个测试只需要公开一个运行函数。剩下的就是我们希望网络如何运作的逻辑了。
运行函数的一般准则是:
Real[][] trainData = new Real[N][]; Real[][] trainLabel = new Real[N][]; for (int i = 0; i < N; i++) { //Prepare Sin wave for one cycle Real radian = -Math.PI + Math.PI * 2.0 * i / (N - 1); trainData[i] = new[] { radian }; trainLabel[i] = new Real[] { Math.Sin(radian) };
2.创建函数堆栈:
FunctionStack nn = new FunctionStack( new Linear(1, 4, name: "l1 Linear"), new Tanh(name: "l1 Tanh"), new Linear(4, 1, name: "l2 Linear") );
3.选择优化器:
nn.SetOptimizer(new SGD());
4.训练数据:
for (int i = 0; i < EPOCH; i++) { Real loss = 0; for (int j = 0; j < N; j++) { //When training is executed in the network, an error is returned to the return value loss += Trainer.Train(nn, trainData[j], trainLabel[j], new MeanSquaredError()); } if (i % (EPOCH / 10) == 0) { RILogManager.Default?.SendDebug("loss:" + loss / N); RILogManager.Default?.SendDebug(""); } }
5.测试数据:
RILogManager.Default?.SendDebug("Test Start..."); foreach (Real[] val in trainData) { RILogManager.Default?.SendDebug(val[0]+":"+nn.Predict(val)[0].Data[0]); }
在这一章中,我们进入了深度学习的世界。我们学习了如何使用Kelp.Net作为我们的研究平台,它几乎可以测试任何假设。我们还看到了Kelp.Net的强大功能和灵活性。
标签:长度 enc etop sig 相关 系统 两种 纪元 pool
原文地址:https://www.cnblogs.com/wangzhenyao1994/p/11615754.html