标签:advance shuf HERE number ase main from inf def
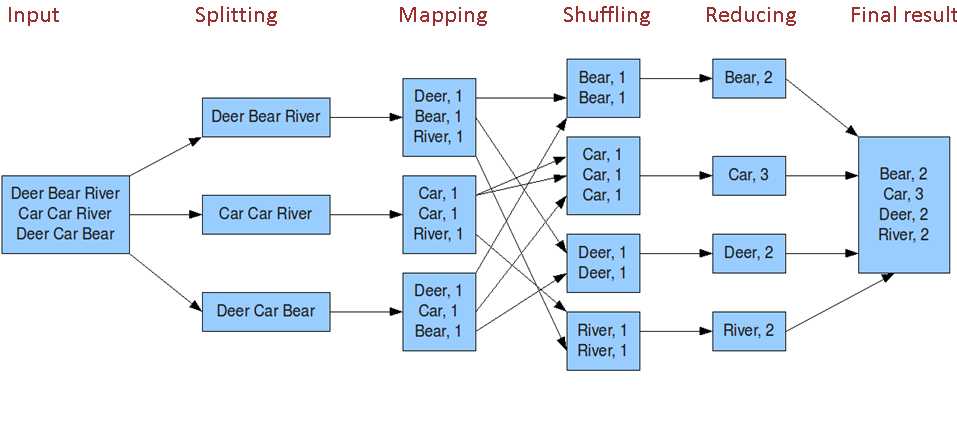
注,reduce之前已经shuff。
mapper.py
#!/usr/bin/env python """mapper.py""" import sys # input comes from STDIN (standard input) for line in sys.stdin: # remove leading and trailing whitespace line = line.strip() # split the line into words words = line.split() # increase counters for word in words: # write the results to STDOUT (standard output); # what we output here will be the input for the # Reduce step, i.e. the input for reducer.py # # tab-delimited; the trivial word count is 1 print ‘%s\t%s‘ % (word, 1)
reducer.py
#!/usr/bin/env python """reducer.py""" from operator import itemgetter import sys current_word = None current_count = 0 word = None # input comes from STDIN for line in sys.stdin: # remove leading and trailing whitespace line = line.strip() # parse the input we got from mapper.py word, count = line.split(‘\t‘, 1) # convert count (currently a string) to int try: count = int(count) except ValueError: # count was not a number, so silently # ignore/discard this line continue # this IF-switch only works because Hadoop sorts map output # by key (here: word) before it is passed to the reducer if current_word == word: current_count += count else: if current_word: # write result to STDOUT print ‘%s\t%s‘ % (current_word, current_count) current_count = count current_word = word # do not forget to output the last word if needed! if current_word == word: print ‘%s\t%s‘ % (current_word, current_count)
mapper.py
#!/usr/bin/env python """A more advanced Mapper, using Python iterators and generators.""" import sys def read_input(file): for line in file: # split the line into words yield line.split() def main(separator=‘\t‘): # input comes from STDIN (standard input) data = read_input(sys.stdin) for words in data: # write the results to STDOUT (standard output); # what we output here will be the input for the # Reduce step, i.e. the input for reducer.py # # tab-delimited; the trivial word count is 1 for word in words: print ‘%s%s%d‘ % (word, separator, 1) if __name__ == "__main__": main()
reducer.py
#!/usr/bin/env python """A more advanced Reducer, using Python iterators and generators.""" from itertools import groupby from operator import itemgetter import sys def read_mapper_output(file, separator=‘\t‘): for line in file: yield line.rstrip().split(separator, 1) def main(separator=‘\t‘): # input comes from STDIN (standard input) data = read_mapper_output(sys.stdin, separator=separator) # groupby groups multiple word-count pairs by word, # and creates an iterator that returns consecutive keys and their group: # current_word - string containing a word (the key) # group - iterator yielding all ["<current_word>", "<count>"] items for current_word, group in groupby(data, itemgetter(0)): try: total_count = sum(int(count) for current_word, count in group) print "%s%s%d" % (current_word, separator, total_count) except ValueError: # count was not a number, so silently discard this item pass if __name__ == "__main__": main()
标签:advance shuf HERE number ase main from inf def
原文地址:https://www.cnblogs.com/pengwang52/p/11619614.html