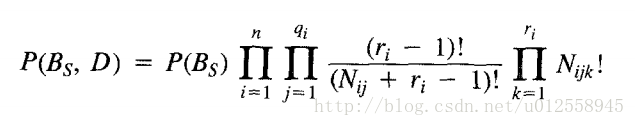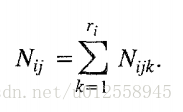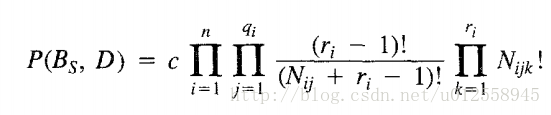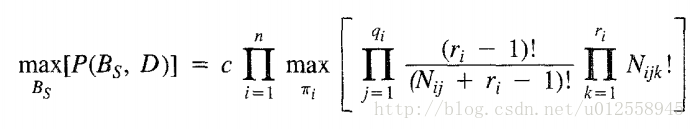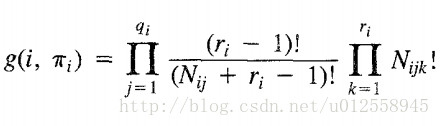标签:coop inf smi ace 顺序 最大的 拓展 info 不同的
一 算法简介
基于搜索的贝叶斯网络结构学习算法核心主要包含两块:一是确定评分函数,用以评价网络结构的好坏。二是确定搜索策略以找到最好的结果。
二 评分函数
对网络结构的学习其实可以归结为求给定数据D下,具有最大后验概率的网络结构Bs,即求Bs使P(Bs| D)最大。
而P(Bs | D) = P(Bs , D) / P(D),分母P(D)与Bs无关,所以最终的目标是求使P(Bs , D)最大的Bs,通过一系列推导(具体推导过程请看最上方链接的paper),可以得到:
其中P(Bs)是关于关于Bs的先验概率,也就是在不给定数据的情况下,我们给每种结构设定的概率。在后面,我们可以假设每种结构的概率服从均匀分布,即概率都是相同的常数c。
令Z是一个包含n个离散随机变量的集合,每个变量Xi有ri种可能的取值(Vi1,Vi2.....Viri)。令D一个数据库,包含m个case,每个case就是对所有Z中随机变量的实例化。用Bs表示一个正好包含Z中随机变量的信念网络。变量Xi在Bs中的父节点表示为πi。Wij表示πi的第j种实例化。πi共有qi种实例化。比如变量Xi有2个父变量,第一个父变量有2种取值,第二个父变量有3种取值,那么qi最多为2*3=6。Nijk表示数据D中Xi取值为Vik并且πi被实例化为Wij。同时:
第一个连乘符号通过i遍历每个随机变量Xi,n为随机变量的个数。
第二个连乘符号通过j遍历当前变量Xi的所有父变量实例,qi表示变量Xi父变量实例的种类数。。
最后一个连乘符号变量遍历当前变量Xi的所有可能取值,ri为可能取值的个数。
用常数代替P(Bs)后:
我们的目标是寻找Bs使后验概率最大:
当找到一个最好的网络结构,把该结构下的Nijk数据带入上式可以得到最大值。从上式可以看出,我们只要最大化每个变量的局部最大,就能得到整体最大。我们将每个变量的部分提出来作为新的评分函数:
三 搜索策略
因此,我们只要对每个变量求出使评分函数最大的父变量集。K2算法使用贪心搜索去获取最大值。首先假设随机变量是有顺序的,如果Xi在Xj之前,那么不能存在从Xj到Xi的边。同时假设每个变量最多的父变量个数为u。每次挑选使评分函数最大的父变量放入集合,当无法使评分函数增大时,停止循环,具体算法如下,其中Pred(Xi)表示顺序在Xi之前的变量:
四 算法拓展
其实我们可以计算log g(i, πi),而不是直接计算g(i, πi)。因为通过log函数可以将乘法运算转变为加法运算。
还有一种算法叫做K2R(K2 Reverse),它从一个全连接的信念网络开始,不断应用贪心算法从结构中移除边。我们可以用K2和K2R分别学习两个结构并从中挑选后验概率更大的结构。也可以在执行K2算法时,初始化不同的节点顺序,并挑选输出的网络结构中较好的那个。
标签:coop inf smi ace 顺序 最大的 拓展 info 不同的
原文地址:https://www.cnblogs.com/think90/p/11619636.html