标签:数据库 一个 概率 保存 step 冲突 怎么 必须 统一
按锁的粒度划分:表级锁、行级锁、页级锁
按锁级别划分:共享锁、排它锁、意向锁
按加锁方式划分:自动锁、显示锁
按使用方式划分:乐观锁、悲观锁
行级锁:行级锁分为共享锁和排他锁。行级锁是MySQL中锁定粒度最细的锁。InnoDB引擎支持行级锁和表级锁,只有在通过索引条件检索数据的时候,才使用行级锁,否就使用表级锁。行级锁开销大,加锁慢,锁定粒度最小,发生锁冲突的概率最低,并发度最高。
表级锁:表级锁分为表共享锁和表独占锁。表级锁开销小,加锁快,锁定粒度大,发生锁冲突最高,并发度最低
页级锁:页级锁是MySQL中锁定粒度介于行级锁和表级锁中间的一种锁。表级锁速度快,但冲突多,行级冲突少,但速度慢。所以取了折中的页级,一次锁定相邻的一组记录。BDB支持页级锁。开销和加锁时间界于表锁和行锁之间;会出现死锁。锁定粒度界于表锁和行锁之间,并发度一般。
排它锁(exclusive lock)
排他锁又叫写锁,如果事务T对A加上排它锁,则其他事务都不能对A加任何类型的锁。获准排它锁的事务既能读数据,又能写数据
共享锁(share lock)
共享锁又叫读锁,如果事务T对A加上共享锁,则其他事务只能对A再加共享锁,不能加其他锁。共享锁的事务只能读数据,不能写数据。
其实有排它锁和共享锁就足够了为什么还需要有意向锁,这里举一个比较形象的例子:
在mysql中有表锁,读锁锁表,会阻塞其他事务修改表数据。写锁锁表,会阻塞其他事务读和写。
数据库要怎么判断这个冲突呢?
注意step2,这样的判断方法效率实在不高,因为需要遍历整个表。于是就有了意向锁。在意向锁存在的情况下,事务A必须先申请表的意向共享锁,成功后再申请一行的行锁。
在意向锁存在的情况下,上面的判断可以改成
注意:申请意向锁的动作是数据库完成的,就是说,事务A申请一行的行锁的时候,数据库会自动先开始申请表的意向锁,不需要我们程序员使用代码来申请。
InnoDB的锁定模式实际上可以分为四种:共享锁(S)、排它锁(X)、意向共享锁(IS)和意向排它锁(IX),我们可以通过以下表来总结上面四种锁的共存逻辑关系:
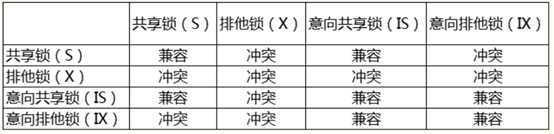
如果一个事务请求的锁模式与当前的锁兼容,InnoDB就将请求的锁授予该事务;反之,如果两者不兼容,该事务就要等待锁释放。
意向锁是InnoDB自动加的,不需用户干预。对于UPDATE、DELETE和INSERT语句,InnoDB会自动给涉及数据集加排他锁(X);对于普通SELECT语句,InnoDB不会加任何锁;
Read Uncommitted,读写均不使用锁,数据的一致性最差,也会出现许多逻辑错误。
Read committed,使用写锁,但是读会出现不一致,不可重复度
Repeatable Read,使用读锁和写锁,解决不可重复读的问题,但会有幻读
Serializable,使用事务串行化调度,避免出现因为插入数据没法加锁导致的不一致的情况
读不提交,造成脏读(Read Uncommitted)
一个事务中的读操作可能读到另一个事务中未提交修改的数据,如果事务发生回滚就可能造成错误。
例子:A打100块给B,B看账户,这是两个操作,针对同一个数据库,两个事物,如果B读到了A事务中的100块,认为钱打过来了,但是A的事务最后回滚了,造成损失。
避免这些事情的发生就需要我们在写操作的时候加锁,使读写分离,保证读数据的时候,数据不被修改,写数据的时候,数据不被读取。从而保证写的同时不能被另个事务写和读。
读提交(Read Committed)
我们加了写锁,就可以保证不出现脏读,也就是保证读的都是提交之后的数据,但是会造成不可重读,即读的时候不加锁,一个读的事务过程中,如果读取数据两次,在两次之间有写事务修改了数据,将会导致两次读取的结果不一致,从而导致逻辑错误。
可重复度(Repeatable Read)
解决不可重复读问题,一个事务中如果有多次读取操作,读取结果需要一致(指的是固定一条数据的一致,幻读指的是查询出的数量不一致)。 这就牵涉到事务中是否加读锁,并且读操作加锁后是否在事务commit之前持有锁的问题,如果不加读锁,必然出现不可重复读,如果加锁读完立即释放,不持有,那么就可能在其他事务中被修改,若其他事务已经执行完成,此时该事务中再次读取就会出现不可重复读,
可串行话(Serializable)
解决幻读问题,在同一个事务中,同一个查询多次返回的结果不一致。事务A新增了一条记录,事务B在事务A提交前后各执行了一次查询操作,发现后一次比前一次多了一条记录。幻读是由于并发事务增加记录导致的,这个不能像不可重复读通过记录加锁解决,因为对于新增的记录根本无法加锁。需要将事务串行化,才能避免幻读。
这是最高的隔离级别,它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。简言之,它是在每个读的数据行上加上共享锁。在这个级别,可能导致大量的超时现象和锁竞争
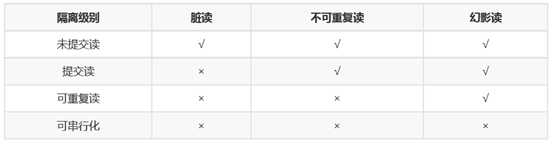
MySQL默认的事务隔离级别为可重复读
当我们用范围条件而不是相等条件检索数据,并请求共享或排他锁时,InnoDB会给符合条件的已有数据记录的 索引项加锁;对于键值在条件范围内但并不存在的记录,叫做"间隙(GAP)",InnoDB也会对这个"间隙"加锁,这种锁机制就是所谓的间隙锁 (Next-Key锁)。
举例来说,假如emp表中只有101条记录,其empid的值分别是 1,2,…,100,101,下面的SQL:
Select * from emp where empid > 100 for update;
是一个范围条件的检索,InnoDB不仅会对符合条件的empid值为101的记录加锁,也会对empid大于101(这些记录并不存在)的"间隙"加锁。
InnoDB使用间隙锁的目的,一方面是为了防止幻读,以满足相关隔离级别的要求,对于上面的例子,要是不使 用间隙锁,如果其他事务插入了empid大于100的任何记录,那么本事务如果再次执行上述语句,就会发生幻读;另外一方面,是为了满足其恢复和复制的需要。
很显然,在使用范围条件检索并锁定记录时,InnoDB这种加锁机制会阻塞符合条件范围内键值的并发插入,这往往会造成严重的锁等待。因此,在实际应用开发中,尤其是并发插入比较多的应用,我们要尽量优化业务逻辑,尽量使用相等条件来访问更新数据,避免使用范围条件。
还要特别说明的是,InnoDB除了通过范围条件加锁时使用间隙锁外,如果使用相等条件请求给一个不存在的记录加锁,InnoDB也会使用间隙锁!下面这个例子假设emp表中只有101条记录,其empid的值分别是1,2,……,100,101。
InnoDB存储引擎的间隙锁阻塞例子

MVCC(Multi-Version Concurrency Control)即多版本并发控制。
MySQL的大多数事务型(如InnoDB,Falcon等)存储引擎实现的都不是简单的行级锁。基于提升并发性能的考虑,他们一般都同时实现了MVCC。当前不仅仅是MySQL,其它数据库系统(如Oracle,PostgreSQL)也都实现了MVCC。MVCC并没有一个统一的实现标准,所以不同的数据库,不同的存储引擎的实现都不尽相同。
MVCC是通过在每行记录后面保存两个隐藏的列来实现的。这两个列,一个保存了行的创建时间,一个保存行的过期时间(或删除时间)。当然存储的并不是实际的时间值,而是系统版本号(system version number)。每开始一个新的事务,系统版本号都会自动递增。事务开始时刻的系统版本号会作为事务的版本号,用来和查询到的每行记录的版本号进行比较。
下面看一下在REPEATABLE READ隔离级别下,MVCC具体是如何操作的。
SELECT
InnoDB会根据以下两个条件检查每行记录:
只有符合上述两个条件的记录,才能返回作为查询结果
INSERT
InnoDB为新插入的每一行保存当前系统版本号作为行版本号。
DELETE
InnoDB为删除的每一行保存当前系统版本号作为行删除标识。
UPDATE
InnoDB为插入一行新记录,保存当前系统版本号作为行版本号,同时保存当前系统版本号到原来的行作为行删除标识。
保存这两个额外系统版本号,使大多数读操作都可以不用加锁。这样设计使得读数据操作很简单,性能很好,并且也能保证只会读取到符合标准的行,不足之处是每行记录都需要额外的存储空间,需要做更多的行检查工作,以及一些额外的维护工作
举例说明

transaction 1:

假设系统初始事务ID为1;

transaction 2:

SELECT
假设当执行事务2的过程中,准备执行语句(2)时,开始执行事务3:
transaction 3:

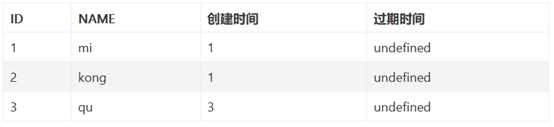
事务3执行完毕,开始执行事务2 语句2,由于事务2只能查询创建时间小于等于2的,所以事务3新增的记录在事务2中是查不出来的,这就通过乐观锁的方式避免了幻读的产生
UPDATE
假设当执行事务2的过程中,准备执行语句(2)时,开始执行事务4:
transaction session 4:

InnoDB执行UPDATE,实际上是新插入了一行记录,并保存其创建时间为当前事务的ID,同时保存当前事务ID到要UPDATE的行的删除时间
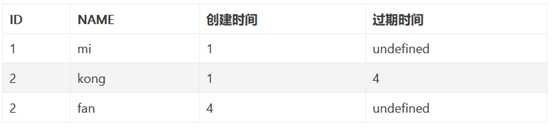
事务4执行完毕,开始执行事务2 语句2,由于事务2只能查询创建时间小于等于2的,所以事务修改的记录在事务2中是查不出来的,这样就保证了事务在两次读取时读取到的数据的状态是一致的
DELETE
假设当执行事务2的过程中,准备执行语句(2)时,开始执行事务5:
transaction session 5:


事务5执行完毕,开始执行事务2 语句2,由于事务2只能查询创建时间小于等于2、并且过期时间大于等于2,所以id=2的记录在事务2 语句2中,也是可以查出来的,这样就保证了事务在两次读取时读取到的数据的状态是一致的
标签:数据库 一个 概率 保存 step 冲突 怎么 必须 统一
原文地址:https://www.cnblogs.com/kexinxin/p/11620345.html