这一章节主要目的是介绍 Dataset 的基础操作, 当然, DataFrame 就是 Dataset, 所以这些操作大部分也适用于 DataFrame
-
有类型的转换操作
-
无类型的转换操作
-
基础
Action -
空值如何处理
-
统计操作
标签:sem ane 大数 出现 ted 导入 针对 image 数组
这一章节主要目的是介绍 Dataset 的基础操作, 当然, DataFrame 就是 Dataset, 所以这些操作大部分也适用于 DataFrame
有类型的转换操作
无类型的转换操作
基础 Action
空值如何处理
统计操作
| 分类 | 算子 | 解释 |
|---|---|---|
|
转换 |
|
通过 |
|
|
|
|
|
|
|
|
|
|
 |
|
|
|
|
|
|
过滤 |
|
|
|
聚合 |
|
其实这也印证了分组后必须聚合的道理 |
|
切分 |
|
|
|
|
|
|
|
排序 |
|
|
|
|
其实 |
|
|
分区 |
|
减少分区, 此算子和 |
|
|
|
|
|
去重 |
|
使用 |
|
|
当  所以, 使用 |
|
|
集合操作 |
|
|
|
|
求得两个集合的交集 |
|
|
|
求得两个集合的并集 |
|
|
|
限制结果集数量 |
| 分类 | 算子 | 解释 |
|---|---|---|
|
选择 |
|
|
|
|
在 |
|
|
|
通过 |
|
|
|
修改列名 |
|
|
剪除 |
drop |
剪掉某个列 |
|
聚合 |
groupBy |
按照给定的行进行分组 |
Column 表示了 Dataset 中的一个列, 并且可以持有一个表达式, 这个表达式作用于每一条数据, 对每条数据都生成一个值, 之所以有单独这样的一个章节是因为列的操作属于细节, 但是又比较常见, 会在很多算子中配合出现
| 分类 | 操作 | 解释 |
|---|---|---|
|
创建 |
|
单引号 |
|
|
同理, |
|
|
|
|
|
|
|
|
|
|
|
前面的 |
|
|
|
可以通过
|
|
|
别名和转换 |
|
|
|
|
通过 |
|
|
添加列 |
|
通过 |
|
操作 |
|
通过 |
|
|
通过 |
|
|
|
在排序的时候, 可以通过 |
DataFrame 中什么时候会有无效值
DataFrame 如何处理无效的值
DataFrame 如何处理 null
如果想探究如何处理无效值, 首先要知道无效值从哪来, 从而分析可能产生的无效值有哪些类型, 在分别去看如何处理无效值
一个值本身的含义是这个值不存在则称之为缺失值, 也就是说这个值本身代表着缺失, 或者这个值本身无意义, 比如说 null, 比如说空字符串

关于数据的分析其实就是统计分析的概念, 如果这样的话, 当数据集中存在缺失值, 则无法进行统计和分析, 对很多操作都有影响

Spark 大多时候处理的数据来自于业务系统中, 业务系统中可能会因为各种原因, 产生一些异常的数据
例如说因为前后端的判断失误, 提交了一些非法参数. 再例如说因为业务系统修改 MySQL 表结构产生的一些空值数据等. 总之在业务系统中出现缺失值其实是非常常见的一件事, 所以大数据系统就一定要考虑这件事.
常见的缺失值有两种
null, NaN 等特殊类型的值, 某些语言中 null 可以理解是一个对象, 但是代表没有对象, NaN 是一个数字, 可以代表不是数字
针对这一类的缺失值, Spark 提供了一个名为 DataFrameNaFunctions 特殊类型来操作和处理
"Null", "NA", " " 等解析为字符串的类型, 但是其实并不是常规字符串数据
针对这类字符串, 需要对数据集进行采样, 观察异常数据, 总结经验, 各个击破
DataFrameNaFunctionsSparkSQL 处理 null 和 NaN ?SparkSQL 处理异常字符串 ?groupBy
rollup
cube
pivot
RelationalGroupedDataset 上的聚合操作
groupByrollup 操作符rollup 完成 pm 值的统计cubeSparkSQL 中支持的 SQL 语句实现 cube 功能RelationalGroupedDataset无类型连接 join
连接类型 Join Types
join 的 API按照 PostgreSQL 的文档中所说, 只要能在一个查询中, 同一时间并发的访问多条数据, 就叫做连接.
做到这件事有两种方式
一种是把两张表在逻辑上连接起来, 一条语句中同时访问两张表
select * from user join address on user.address_id = address.id还有一种方式就是表连接自己, 一条语句也能访问自己中的多条数据
select * from user u1 join (select * from user) u2 on u1.id = u2.idjoin 算子的使用非常简单, 大致的调用方式如下join(right: Dataset[_], joinExprs: Column, joinType: String): DataFrame表结构如下
+---+------+------+ +---+---------+
| id| name|cityId| | id| name|
+---+------+------+ +---+---------+
| 0| Lucy| 0| | 0| Beijing|
| 1| Lily| 0| | 1| Shanghai|
| 2| Tim| 2| | 2|Guangzhou|
| 3|Danial| 0| +---+---------+
+---+------+------+如果希望对这两张表进行连接, 首先应该注意的是可以连接的字段, 比如说此处的左侧表 cityId 和右侧表 id 就是可以连接的字段, 使用 join 算子就可以将两个表连接起来, 进行统一的查询
val person = Seq((0, "Lucy", 0), (1, "Lily", 0), (2, "Tim", 2), (3, "Danial", 0))
.toDF("id", "name", "cityId")
val cities = Seq((0, "Beijing"), (1, "Shanghai"), (2, "Guangzhou"))
.toDF("id", "name")
person.join(cities, person.col("cityId") === cities.col("id"))
.select(person.col("id"),
person.col("name"),
cities.col("name") as "city")
.show()
/**
* 执行结果:
*
* +---+------+---------+
* | id| name| city|
* +---+------+---------+
* | 0| Lucy| Beijing|
* | 1| Lily| Beijing|
* | 2| Tim|Guangzhou|
* | 3|Danial| Beijing|
* +---+------+---------+
*/现在两个表连接得到了如下的表
+---+------+---------+
| id| name| city|
+---+------+---------+
| 0| Lucy| Beijing|
| 1| Lily| Beijing|
| 2| Tim|Guangzhou|
| 3|Danial| Beijing|
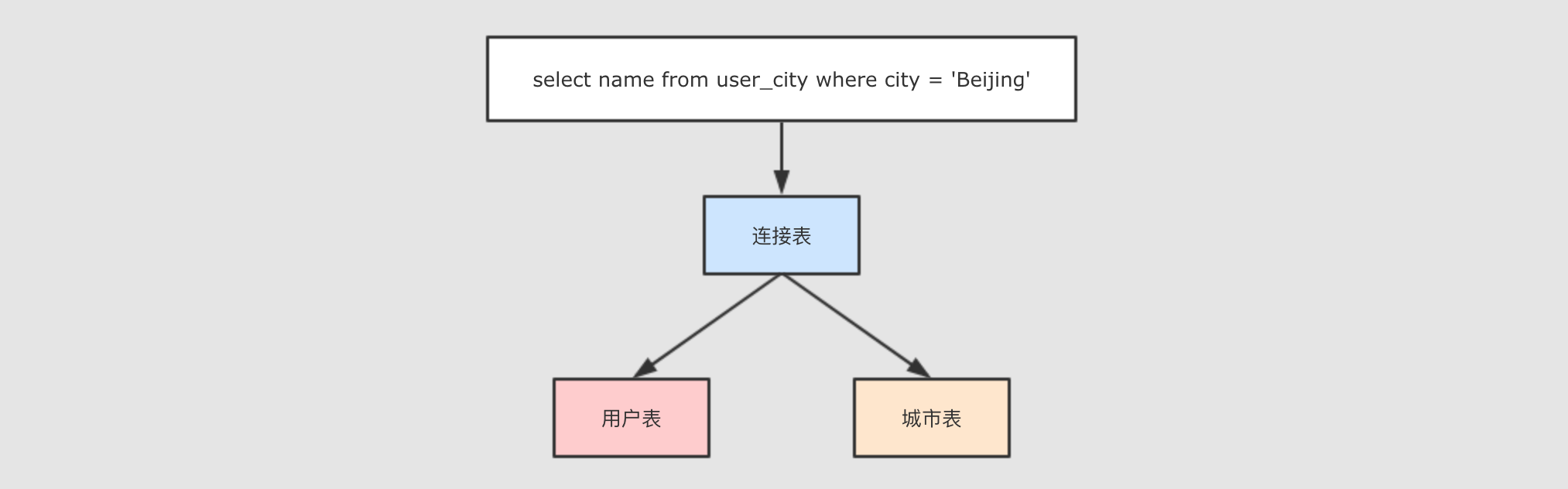
+---+------+---------+通过对这张表的查询, 这个查询是作用于两张表的, 所以是同一时间访问了多条数据
spark.sql("select name from user_city where city = ‘Beijing‘").show()
/**
* 执行结果
*
* +------+
* | name|
* +------+
* | Lucy|
* | Lily|
* |Danial|
* +------+
*/
如果要运行如下代码, 需要先进行数据准备
private val spark = SparkSession.builder()
.master("local[6]")
.appName("aggregation")
.getOrCreate()
import spark.implicits._
val person = Seq((0, "Lucy", 0), (1, "Lily", 0), (2, "Tim", 2), (3, "Danial", 3))
.toDF("id", "name", "cityId")
person.createOrReplaceTempView("person")
val cities = Seq((0, "Beijing"), (1, "Shanghai"), (2, "Guangzhou"))
.toDF("id", "name")
cities.createOrReplaceTempView("cities")| 连接类型 | 类型字段 | 解释 |
|---|---|---|
|
交叉连接 |
|
|
|
内连接 |
|
|
|
全外连接 |
|
|
|
左外连接 |
|
|
|
|
|
|
|
|
|
|
|
右外连接 |
|
|
Join 过程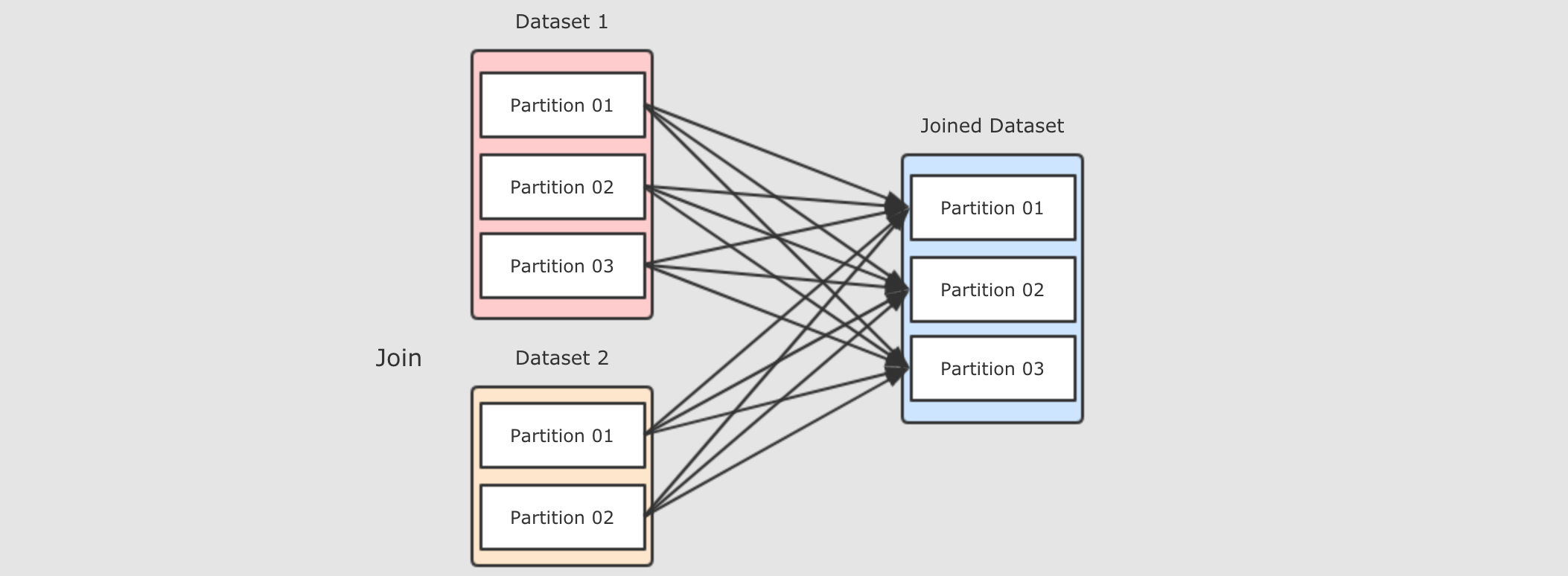
Join 会在集群中分发两个数据集, 两个数据集都要复制到 Reducer 端, 是一个非常复杂和标准的 ShuffleDependency, 有什么可以优化效率吗?
Map 端 Join前面图中看的过程, 之所以说它效率很低, 原因是需要在集群中进行数据拷贝, 如果能减少数据拷贝, 就能减少开销
如果能够只分发一个较小的数据集呢?
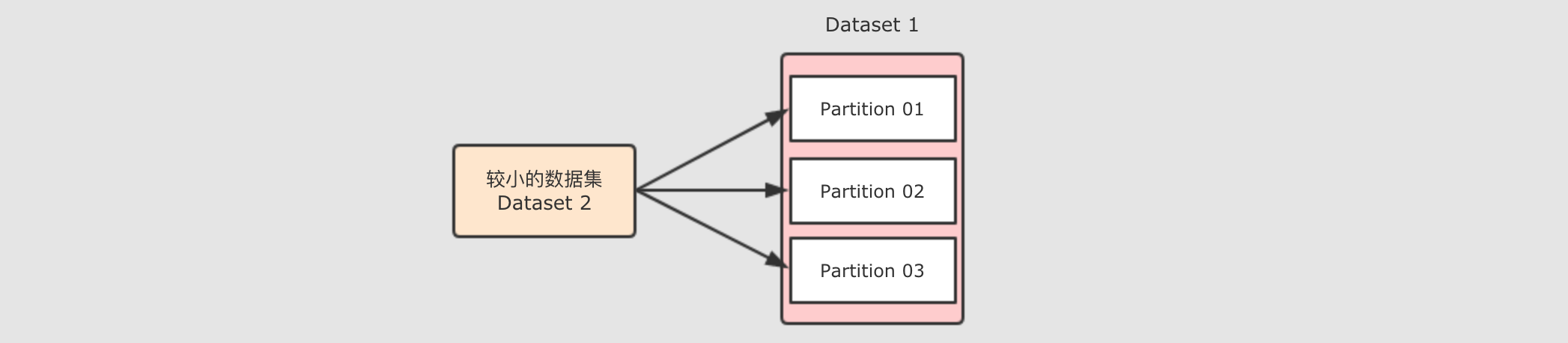
可以将小数据集收集起来, 分发给每一个 Executor, 然后在需要 Join 的时候, 让较大的数据集在 Map 端直接获取小数据集, 从而进行 Join, 这种方式是不需要进行 Shuffle 的, 所以称之为 Map 端 Join
Map 端 Join 的常规实现如果使用 RDD 的话, 该如何实现 Map 端 Join 呢?
val personRDD = spark.sparkContext.parallelize(Seq((0, "Lucy", 0),
(1, "Lily", 0), (2, "Tim", 2), (3, "Danial", 3)))
val citiesRDD = spark.sparkContext.parallelize(Seq((0, "Beijing"),
(1, "Shanghai"), (2, "Guangzhou")))
val citiesBroadcast = spark.sparkContext.broadcast(citiesRDD.collectAsMap())
val result = personRDD.mapPartitions(
iter => {
val citiesMap = citiesBroadcast.value
// 使用列表生成式 yield 生成列表
val result = for (person <- iter if citiesMap.contains(person._3))
yield (person._1, person._2, citiesMap(person._3))
result
}
).collect()
result.foreach(println(_))Dataset 实现 Join 的时候会自动进行 Map 端 Join自动进行 Map 端 Join 需要依赖一个系统参数 spark.sql.autoBroadcastJoinThreshold, 当数据集小于这个参数的大小时, 会自动进行 Map 端 Join
如下, 开启自动 Join
println(spark.conf.get("spark.sql.autoBroadcastJoinThreshold").toInt / 1024 / 1024)
println(person.crossJoin(cities).queryExecution.sparkPlan.numberedTreeString)当关闭这个参数的时候, 则不会自动 Map 端 Join 了
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", -1)
println(person.crossJoin(cities).queryExecution.sparkPlan.numberedTreeString)在使用 Dataset 的 join 时, 可以使用 broadcast 函数来实现 Map 端 Join
import org.apache.spark.sql.functions._
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", -1)
println(person.crossJoin(broadcast(cities)).queryExecution.sparkPlan.numberedTreeString)即使是使用 SQL 也可以使用特殊的语法开启
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", -1)
val resultDF = spark.sql(
"""
|select /*+ MAPJOIN (rt) */ * from person cross join cities rt
""".stripMargin)
println(resultDF.queryExecution.sparkPlan.numberedTreeString)
Update:sparksql:第3节 Dataset (DataFrame) 的基础操作 & 第4节 SparkSQL_聚合操作_连接操作
标签:sem ane 大数 出现 ted 导入 针对 image 数组
原文地址:https://www.cnblogs.com/mediocreWorld/p/11626168.html