标签:apach protoc continue string sea 依赖 url 标题 类型
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.javaxl</groupId> <artifactId>T226_jsoup</artifactId> <version>0.0.1-SNAPSHOT</version> <packaging>jar</packaging> <name>T226_jsoup</name> <url>http://maven.apache.org</url> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> </properties> <dependencies> <!-- jdbc驱动包 --> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.44</version> </dependency> <!-- 添加Httpclient支持 --> <dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpclient</artifactId> <version>4.5.2</version> </dependency> <!-- 添加jsoup支持 --> <dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.10.1</version> </dependency> <!-- 添加日志支持 --> <dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> <version>1.2.16</version> </dependency> <!-- 添加ehcache支持 --> <dependency> <groupId>net.sf.ehcache</groupId> <artifactId>ehcache</artifactId> <version>2.10.3</version> </dependency> <!-- 添加commons io支持 --> <dependency> <groupId>commons-io</groupId> <artifactId>commons-io</artifactId> <version>2.5</version> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.47</version> </dependency> </dependencies> </project>
BlogCrawlerStarter(爬取网站数据)
package com.javaxl.crawler; import java.io.File; import java.io.IOException; import java.sql.Connection; import java.sql.PreparedStatement; import java.sql.SQLException; import java.util.HashMap; import java.util.List; import java.util.Map; import java.util.UUID; import org.apache.commons.io.FileUtils; import org.apache.http.HttpEntity; import org.apache.http.client.ClientProtocolException; import org.apache.http.client.config.RequestConfig; import org.apache.http.client.methods.CloseableHttpResponse; import org.apache.http.client.methods.HttpGet; import org.apache.http.impl.client.CloseableHttpClient; import org.apache.http.impl.client.HttpClients; import org.apache.http.util.EntityUtils; import org.apache.log4j.Logger; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; import com.javaxl.util.DateUtil; import com.javaxl.util.DbUtil; import com.javaxl.util.PropertiesUtil; import net.sf.ehcache.Cache; import net.sf.ehcache.CacheManager; import net.sf.ehcache.Status; /** * @author Administrator * */ public class BlogCrawlerStarter { private static Logger logger = Logger.getLogger(BlogCrawlerStarter.class); // https://www.csdn.net/nav/newarticles private static String HOMEURL = "https://www.cnblogs.com/"; private static CloseableHttpClient httpClient; private static Connection con; private static CacheManager cacheManager; private static Cache cache; /** * httpclient解析首页,获取首页内容 */ public static void parseHomePage() { logger.info("开始爬取首页:" + HOMEURL); cacheManager = CacheManager.create(PropertiesUtil.getValue("ehcacheXmlPath")); cache = cacheManager.getCache("cnblog"); httpClient = HttpClients.createDefault(); HttpGet httpGet = new HttpGet(HOMEURL); RequestConfig config = RequestConfig.custom().setConnectTimeout(5000).setSocketTimeout(8000).build(); httpGet.setConfig(config); CloseableHttpResponse response = null; try { response = httpClient.execute(httpGet); if (response == null) { logger.info(HOMEURL + ":爬取无响应"); return; } if (response.getStatusLine().getStatusCode() == 200) { HttpEntity entity = response.getEntity(); String homePageContent = EntityUtils.toString(entity, "utf-8"); // System.out.println(homePageContent); parseHomePageContent(homePageContent); } } catch (ClientProtocolException e) { logger.error(HOMEURL + "-ClientProtocolException", e); } catch (IOException e) { logger.error(HOMEURL + "-IOException", e); } finally { try { if (response != null) { response.close(); } if (httpClient != null) { httpClient.close(); } } catch (IOException e) { logger.error(HOMEURL + "-IOException", e); } } if(cache.getStatus() == Status.STATUS_ALIVE) { cache.flush(); } cacheManager.shutdown(); logger.info("结束爬取首页:" + HOMEURL); } /** * 通过网络爬虫框架jsoup,解析网页类容,获取想要数据(博客的连接) * * @param homePageContent */ private static void parseHomePageContent(String homePageContent) { Document doc = Jsoup.parse(homePageContent); //#feedlist_id .list_con .title h2 a Elements aEles = doc.select("#post_list .post_item .post_item_body h3 a"); for (Element aEle : aEles) { // 这个是首页中的博客列表中的单个链接URL String blogUrl = aEle.attr("href"); if (null == blogUrl || "".equals(blogUrl)) { logger.info("该博客未内容,不再爬取插入数据库!"); continue; } if(cache.get(blogUrl) != null) { logger.info("该数据已经被爬取到数据库中,数据库不再收录!"); continue; } // System.out.println("************************"+blogUrl+"****************************"); parseBlogUrl(blogUrl); } } /** * 通过博客地址获取博客的标题,以及博客的类容 * * @param blogUrl */ private static void parseBlogUrl(String blogUrl) { logger.info("开始爬取博客网页:" + blogUrl); httpClient = HttpClients.createDefault(); HttpGet httpGet = new HttpGet(blogUrl); RequestConfig config = RequestConfig.custom().setConnectTimeout(5000).setSocketTimeout(8000).build(); httpGet.setConfig(config); CloseableHttpResponse response = null; try { response = httpClient.execute(httpGet); if (response == null) { logger.info(blogUrl + ":爬取无响应"); return; } if (response.getStatusLine().getStatusCode() == 200) { HttpEntity entity = response.getEntity(); String blogContent = EntityUtils.toString(entity, "utf-8"); parseBlogContent(blogContent, blogUrl); } } catch (ClientProtocolException e) { logger.error(blogUrl + "-ClientProtocolException", e); } catch (IOException e) { logger.error(blogUrl + "-IOException", e); } finally { try { if (response != null) { response.close(); } } catch (IOException e) { logger.error(blogUrl + "-IOException", e); } } logger.info("结束爬取博客网页:" + HOMEURL); } /** * 解析博客类容,获取博客中标题以及所有内容 * * @param blogContent */ private static void parseBlogContent(String blogContent, String link) { Document doc = Jsoup.parse(blogContent); if(!link.contains("ansion2014")) { System.out.println(blogContent); } Elements titleEles = doc //#mainBox main .blog-content-box .article-header-box .article-header .article-title-box h1 .select("#topics .post h1 a"); System.out.println("123"); System.out.println(titleEles.toString()); System.out.println("123"); if (titleEles.size() == 0) { logger.info("博客标题为空,不插入数据库!"); return; } String title = titleEles.get(0).html(); Elements blogContentEles = doc.select("#cnblogs_post_body "); if (blogContentEles.size() == 0) { logger.info("博客内容为空,不插入数据库!"); return; } String blogContentBody = blogContentEles.get(0).html(); // Elements imgEles = doc.select("img"); // List<String> imgUrlList = new LinkedList<String>(); // if(imgEles.size() > 0) { // for (Element imgEle : imgEles) { // imgUrlList.add(imgEle.attr("src")); // } // } // // if(imgUrlList.size() > 0) { // Map<String, String> replaceUrlMap = downloadImgList(imgUrlList); // blogContent = replaceContent(blogContent,replaceUrlMap); // } String sql = "insert into `t_jsoup_article` values(null,?,?,null,now(),0,0,null,?,0,null)"; try { PreparedStatement pst = con.prepareStatement(sql); pst.setObject(1, title); pst.setObject(2, blogContentBody); pst.setObject(3, link); if(pst.executeUpdate() == 0) { logger.info("爬取博客信息插入数据库失败"); }else { cache.put(new net.sf.ehcache.Element(link, link)); logger.info("爬取博客信息插入数据库成功"); } } catch (SQLException e) { logger.error("数据异常-SQLException:",e); } } /** * 将别人博客内容进行加工,将原有图片地址换成本地的图片地址 * @param blogContent * @param replaceUrlMap * @return */ private static String replaceContent(String blogContent, Map<String, String> replaceUrlMap) { for(Map.Entry<String, String> entry: replaceUrlMap.entrySet()) { blogContent = blogContent.replace(entry.getKey(), entry.getValue()); } return blogContent; } /** * 别人服务器图片本地化 * @param imgUrlList * @return */ private static Map<String, String> downloadImgList(List<String> imgUrlList) { Map<String, String> replaceMap = new HashMap<String, String>(); for (String imgUrl : imgUrlList) { CloseableHttpClient httpClient = HttpClients.createDefault(); HttpGet httpGet = new HttpGet(imgUrl); RequestConfig config = RequestConfig.custom().setConnectTimeout(5000).setSocketTimeout(8000).build(); httpGet.setConfig(config); CloseableHttpResponse response = null; try { response = httpClient.execute(httpGet); if (response == null) { logger.info(HOMEURL + ":爬取无响应"); }else { if (response.getStatusLine().getStatusCode() == 200) { HttpEntity entity = response.getEntity(); String blogImagesPath = PropertiesUtil.getValue("blogImages"); String dateDir = DateUtil.getCurrentDatePath(); String uuid = UUID.randomUUID().toString(); String subfix = entity.getContentType().getValue().split("/")[1]; String fileName = blogImagesPath + dateDir + "/" + uuid + "." + subfix; FileUtils.copyInputStreamToFile(entity.getContent(), new File(fileName)); replaceMap.put(imgUrl, fileName); } } } catch (ClientProtocolException e) { logger.error(imgUrl + "-ClientProtocolException", e); } catch (IOException e) { logger.error(imgUrl + "-IOException", e); } catch (Exception e) { logger.error(imgUrl + "-Exception", e); } finally { try { if (response != null) { response.close(); } } catch (IOException e) { logger.error(imgUrl + "-IOException", e); } } } return replaceMap; } public static void start() { while(true) { DbUtil dbUtil = new DbUtil(); try { con = dbUtil.getCon(); parseHomePage(); } catch (Exception e) { logger.error("数据库连接势失败!"); } finally { try { if (con != null) { con.close(); } } catch (SQLException e) { logger.error("数据关闭异常-SQLException:",e); } } try { Thread.sleep(1000*60); } catch (InterruptedException e) { logger.error("主线程休眠异常-InterruptedException:",e); } } } public static void main(String[] args) { start(); } }
下面来看一下结果
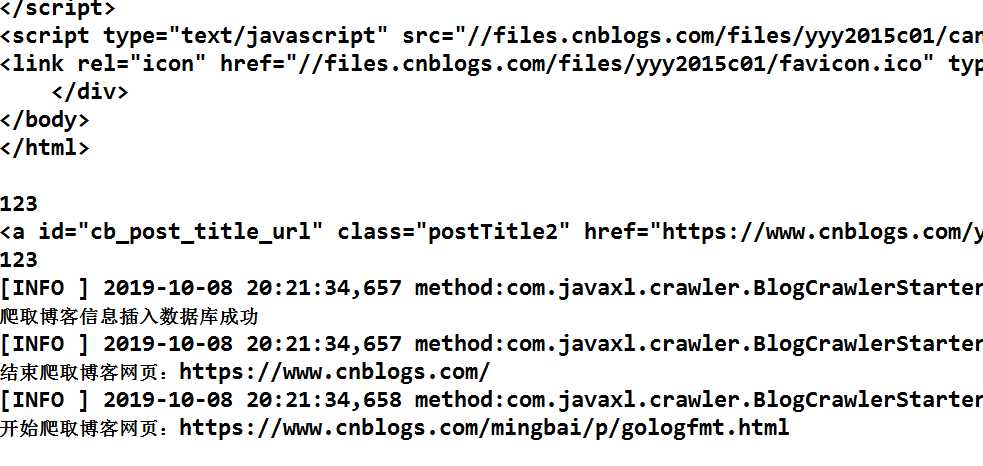
再看一下数据库的数据


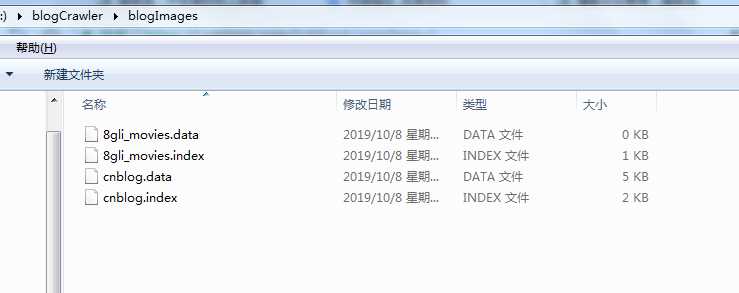
这张就是需要爬取的图片

代码如下
package com.javaxl.crawler; import java.io.File; import java.io.IOException; import java.util.UUID; import org.apache.commons.io.FileUtils; import org.apache.http.HttpEntity; import org.apache.http.client.ClientProtocolException; import org.apache.http.client.config.RequestConfig; import org.apache.http.client.methods.CloseableHttpResponse; import org.apache.http.client.methods.HttpGet; import org.apache.http.impl.client.CloseableHttpClient; import org.apache.http.impl.client.HttpClients; import org.apache.log4j.Logger; import com.javaxl.util.DateUtil; import com.javaxl.util.PropertiesUtil; public class DownloadImg { private static Logger logger = Logger.getLogger(DownloadImg.class); private static String URL = "http://pic16.nipic.com/20111006/6239936_092702973000_2.jpg"; public static void main(String[] args) { logger.info("开始爬取首页:" + URL); CloseableHttpClient httpClient = HttpClients.createDefault(); HttpGet httpGet = new HttpGet(URL); RequestConfig config = RequestConfig.custom().setConnectTimeout(5000).setSocketTimeout(8000).build(); httpGet.setConfig(config); CloseableHttpResponse response = null; try { response = httpClient.execute(httpGet); if (response == null) { logger.info("连接超时!!!"); } else { HttpEntity entity = response.getEntity(); String imgPath = PropertiesUtil.getValue("blogImages"); String dateDir = DateUtil.getCurrentDatePath(); String uuid = UUID.randomUUID().toString(); String subfix = entity.getContentType().getValue().split("/")[1]; String localFile = imgPath+dateDir+"/"+uuid+"."+subfix; // System.out.println(localFile); FileUtils.copyInputStreamToFile(entity.getContent(), new File(localFile)); } } catch (ClientProtocolException e) { logger.error(URL+"-ClientProtocolException", e); } catch (IOException e) { logger.error(URL+"-IOException", e); } catch (Exception e) { logger.error(URL+"-Exception", e); } finally { try { if (response != null) { response.close(); } if(httpClient != null) { httpClient.close(); } } catch (IOException e) { logger.error(URL+"-IOException", e); } } logger.info("结束首页爬取:" + URL); } }
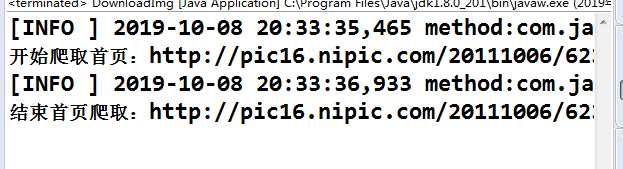
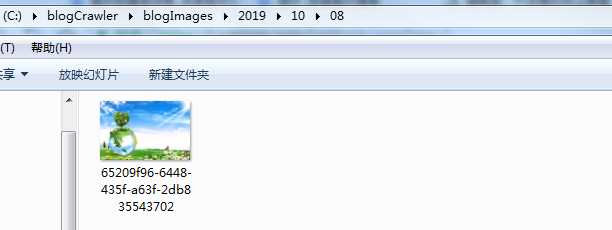
可以到看图片已经进来了,这些就是我们爬取的效果,谢谢浏览!
标签:apach protoc continue string sea 依赖 url 标题 类型
原文地址:https://www.cnblogs.com/xmf3628/p/11637770.html