标签:需要 set alter cal 优缺点 学生 对象 select 实体关系图
目录
case when end 是sql的高级用法,会自动的开辟一个新的列,做用是把比较后的结果输出到一个新的列。可用别名做列名。可以和列(集合)比也可以和单个元素比,比较的结果也可以是列或者单个元素。并且,是列则都是有序对应的。(如此说来也可以列和列比较了,有可能行)
当colume 与condition 条件相等时结果为result。把colume列中所有等于condition的比较结果输出为result
case colume
when condition then result
when condition then result
when condition then result
else result
end另一种方式反而更好用,把性别列的所有男都换成女,之后输出新的列,可以取别名,可以不用ELSE如果不用else那么例外的情况都会输出为null。
SELECT
tb_stu.gender,
tb_stu.id,
CASE
WHEN gender='男' THEN
'man'
ELSE 'woman'
END
FROM
tb_stu加快查询速度1. 索引是一种特殊的数据
2. 索引类似书上的目录,保存的是实际数据的位置,每次查找数据时数据库先查找索引,通过索引找到对应数据的位置。优点:
加快查询速度
缺点:
降低增删改速度,因为需要同时更新索引
需要占用更多存储空间
创建索引需要比较多时间
对数据没有特殊的约束
删除索引
drop index 索引名 on 表;
或
alter table 表名 drop index 索引名;
建表后添加主键
alter table 表名 add primary key 主键名(列);
删除
alter table 表名 drop primary key
删除语法和普通索引一样
主要用于大文本类型(Text)
使用全文索引
select * from 表名 where match(列名) against (‘值‘);
全文索引将整个文章分为多个单词组合,可以按每个单词查询
最左前缀原则:把最重要的列放在左边,不重要的放右边
查询时按列1、列2为条件,索引可以生效
按列2、列3为条件,索引失效
列存在大量的空值
使用函数作为条件
比如: where year(product_date) = 2019;
非聚簇(Non-Clustered)索引
索引的顺序和实际数据的顺序不一致,类似于新华字典中偏旁目录
非聚簇索引表可以有多个
BTree是一种平衡搜索多叉树
每个节点由键和值组成,节点之间有指针指向下层节点位置
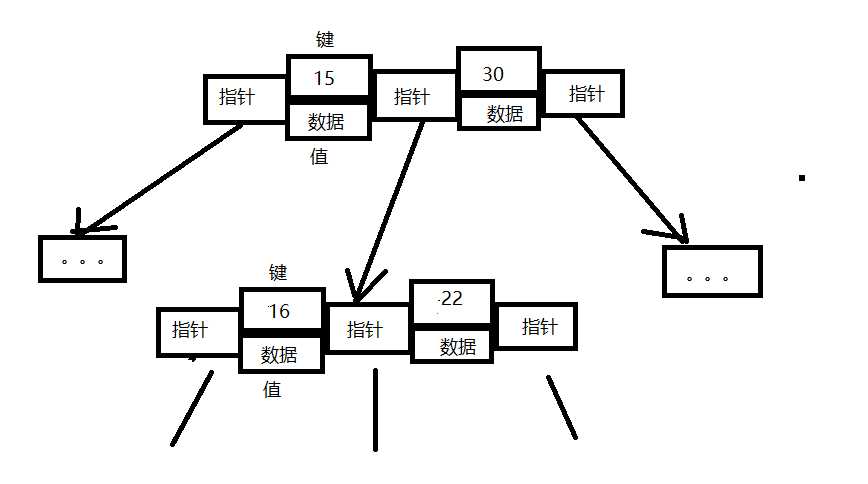
BTree使用二分法进行查找,效率比较高,查找的速度取决于树的高度,高度越小速度越快,高度越大速度越慢。
树的每一层数据容量是一定的,数据越多、节点越多、高度越大。
B+Tree 是BTree升级版,在根节点和枝节点中不存放数据,只存放键和指针,这样每一层保存节点可以更多,树的高度就降低,查找速度更快,数据只放在叶子节点中。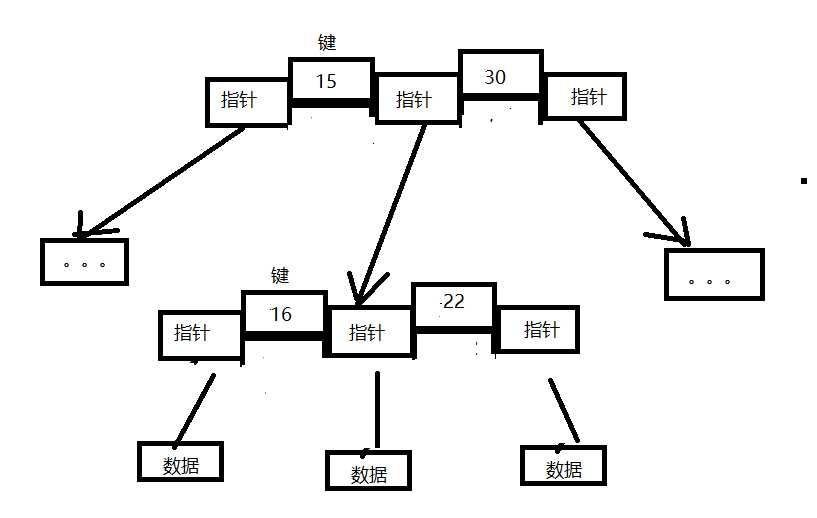
是一种虚拟的表,数据保存在实际的表中
1)简化查询的过程
2)提高数据库安全性,设置权限,给不同用户看不同的数据创建:
create view 视图名 as 查询语句;
使用:
select * from 视图;
类似于Java中的方法,可以用于封装SQL代码,便于重复调用。
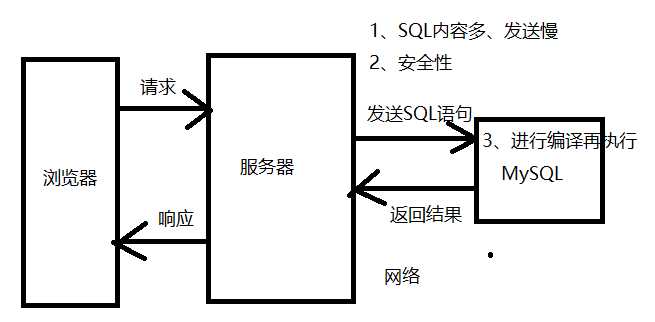
1. 已经保存在数据库中,服务器不需要发送SQL语句,只需要发送调用命令
2. 不发送SQL语句,降低了网络中对SQL语句进行截获或修改的安全问题
3. 存储过程是编译好的,不需要再编译,速度快保存在数据库中,增加了维护的难度delimiter //
create procedure 存储过程名( [in|out|inout]参数名 类型 )
begin
SQL语句;
end//
delimiter ;call 存储过程名(参数);查询某个地区学生的人数
drop procedure if exists pro_select_student_by_address;
delimiter //
create procedure pro_select_student_by_address(s_address varchar(200),out s_count int)
BEGIN
-- 使用into语句给out参数赋值
select count(*) into s_count from tb_student where address = s_address;
end//
输出参数的值
select @count ‘人数‘;
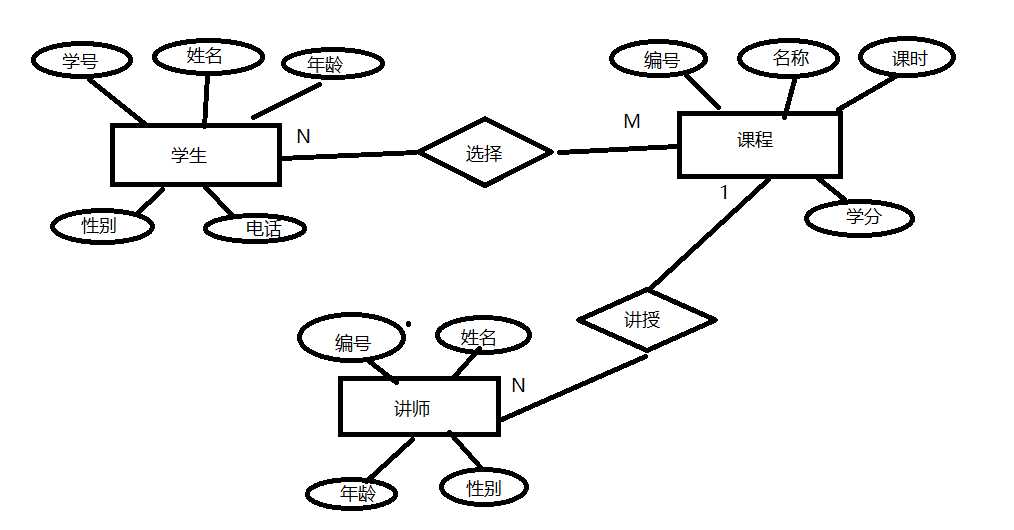
实体关系图(Entity Relationship)
用图形方式标识数据库存在的实体,实体的属性,实体和实体之间的关系
由四种图形组成:
1. 长方形 表示实体
2. 椭圆形 表示属性
3. 连接线
4. 菱形 表示关系
用于规范化数据库的设计,减少数据库的冗余
第三范式
每个列都和主键直接相关,不存在传递依赖
学生表
学号、姓名、年龄、联系电话
课程表
课程号、课程名、学分
成绩表
编号、学生姓名、课程名、分数
问题:学生姓名和课程名和成绩编号没有直接关系
修改:在成绩表中只保存学生编号和课程编号
学生表
学号、姓名、年龄、联系电话
课程表
课程号、课程名、学分
成绩表
编号、学生id、课程id、分数
开发时表的设计一般符合第三范式,范式越高、表就越多、结构越复杂、性能越差。
case - end语句
类似Java中的多重if和switch结构
case
when 条件1 then 结果1
when 条件2 then 结果1
else 缺省值
end
或者
case 列名
when 值1 then 结果1
when 值2 then 结果2
else 缺省值
end
使用max函数取分数最大值
select s.id 学号,s.name 姓名,
max(case c.name
when ‘数学‘ then cs.score
else 0
end) 数学,
max(case c.name
when ‘语文‘ then cs.score
else 0
end) 语文,
max(case c.name
when ‘英语‘ then cs.score
else 0
end) 英语
from tb_stu s left join tb_score cs on s.id = cs.stu_id
left join tb_course c on c.id = cs.course_id group by s.id;
创建部门表(编号、名称、职能描述)、费用类型表(编号,类型名称)、费用统计表(编号,部门编号,费用类型编号,费用金额)
插入测试数据
1)使用行转列实现财务报表,格式如下: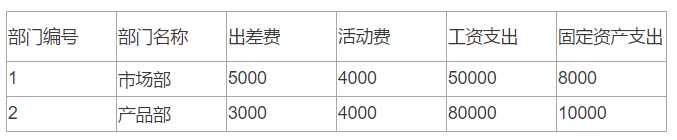
2)使用视图
1)包装该部门的财务报表
2)基于上面的学生表、课程表、成绩表,编写班主任视图(查询学生编号、姓名、性 别、年龄、考试课程和成绩等级优良中差),编写教务视图(查询学生编号,课程)
3)编写几个存储过程分别实现:
1)通过部门名称查询该部门信息
2)插入部门
3)通过编号删除部门
4)通过编号修改部门名称和职能描述
5)通过部门编号查询该部门的总费用,并使用out参数返回费用标签:需要 set alter cal 优缺点 学生 对象 select 实体关系图
原文地址:https://www.cnblogs.com/macht/p/11639396.html