标签:arc ORC 技巧 char dfs 设计思想 形式 val 乘法
包括:按位与(&)、按位或(|)、按位异或(^)、按位取反(~)、按位左移(<<)、按位右移(>>)
1 &(and) 对两个数进行操作,然后返回一个新的数,这个数的每个位都需要两个输入数的(同一位)都为1时才为1
举个例子:
1 1 1 1 1 0
0 0 1 1 1 0
=0 0 1 1 1 0
2 |(or) 比较两个数,然后返回一个新的数,这个数的每一位设置1的条件是两个输入数的同一位都不为0(即任意一个为1,或都为1)
举个例子:
1 0 1 1 0 0
0 1 1 1 1 0
=1 1 1 1 1 0
3 ^(xor)---这里用c语言的标准符号表示。比较两个数,然后返回一个数,这个数的每个位设为1的条件是两个输入数的同一位不同,如果相同就设为0
举个例子:
1 0 1 1 0 1
1 0 0 0 1 0
=0 0 1 1 1 1
4 ~(not/取反)对一个操作数的每一位都取反(包括符号位+/-)
举个例子:
0 0 0 1 1 1
=1 1 1 0 0 0
5 <<(左移) 将操作数的所有位向左移动指定的位数。
举个例子:
0 0 1 1 1 0=14
14<<1
=0 1 1 1 0 0=24
相当于乘2
6 >>(右移) 将操作数的所有位向右移动指定的位数。
举个例子:
0 0 1 1 1 0=14
14>>1
=0 0 0 1 1 1=24
相当于除2(注:如果除不尽则向下取整)
提醒:大小比较符号> & > ^ > |
建议使用括号保证正确性
inline int quick_pow(int a,int b){
int cnt=1;
while(b){
if(b&1) cnt=cnt*a;
a=a*a;
b>>=1;
}
return cnt;
}
注:可直接在内部取模运算
二进制压缩,是指将一个长度为m的bool数组用一个m位二进制整数表示并储存的方法,利用下列运算操作可以实现原bool数组中对应下标元素的存储
取出整数n 在二进制下表示下的第k位 (n>>k) &1
取出整数n 在二进制下表示下的第0 ~k-1 位置(后k位) n & ( ( 1 << k ) - 1 )
把整数 n 在二进制下表示下的第k位取反 n xor (1 << k)
对整数 n 在二进制表示下的第 k 位赋值1 n \ ( 1<<k)
对整数n 在二进制表示下的第k 位赋值 0 n& (~(1<<k))
这种方法运算简便,并且节省了程序运行的时间和空间 在c++中我们可以STL中的bitset实现
lowbit(n)定义为非负整数n在二进制表示下"最低位的1及其后面所有的0"构成的数值。
举个例子:
10在二进制表示为(1010)2,则lowbit(n)=2=(10)2
lowbit(n) = n&(~n+1) = n&(-n)
递归:从已知问题的结果出发,用迭代表达式逐步推算出问题的开始的条件,即顺推法的逆过程,称为递归。
递推:递推算法是一种用若干步可重复运算来描述复杂问题的方法。递推是序列计算中的一种常用算法。通常是通过计算机前面的一些项来得出序列中的指定象的值。
递归与递推区别:相对于递归算法,递推算法免除了数据进出栈的过程,也就是说,不需要函数不断的向边界值靠拢,而直接从边界出发,直到求出函数值。
好像就没什么了
这里引用红脸书生的博客:https://www.cnblogs.com/steven_oyj/archive/2010/05/22/1741370.html
在计算机科学中,分治法是一种很重要的算法。字面上的解释是“分而治之”,就是把一个复杂的问题分成两个或更多的相同或相似的子问题,再把子问题分成更小的子问题……直到最后子问题可以简单的直接求解,原问题的解即子问题的解的合并。这个技巧是很多高效算法的基础,如排序算法(快速排序,归并排序),傅立叶变换(快速傅立叶变换)……
任何一个可以用计算机求解的问题所需的计算时间都与其规模有关。问题的规模越小,越容易直接求解,解题所需的计算时间也越少。例如,对于n个元素的排序问题,当n=1时,不需任何计算。n=2时,只要作一次比较即可排好序。n=3时只要作3次比较即可,…。而当n较大时,问题就不那么容易处理了。要想直接解决一个规模较大的问题,有时是相当困难的。
分治法的设计思想是:将一个难以直接解决的大问题,分割成一些规模较小的相同问题,以便各个击破,分而治之。
分治策略是:对于一个规模为n的问题,若该问题可以容易地解决(比如说规模n较小)则直接解决,否则将其分解为k个规模较小的子问题,这些子问题互相独立且与原问题形式相同,递归地解这些子问题,然后将各子问题的解合并得到原问题的解。这种算法设计策略叫做分治法。
如果原问题可分割成k个子问题,1<k≤n,且这些子问题都可解并可利用这些子问题的解求出原问题的解,那么这种分治法就是可行的。由分治法产生的子问题往往是原问题的较小模式,这就为使用递归技术提供了方便。在这种情况下,反复应用分治手段,可以使子问题与原问题类型一致而其规模却不断缩小,最终使子问题缩小到很容易直接求出其解。这自然导致递归过程的产生。分治与递归像一对孪生兄弟,经常同时应用在算法设计之中,并由此产生许多高效算法。
分治法所能解决的问题一般具有以下几个特征:
1) 该问题的规模缩小到一定的程度就可以容易地解决
2) 该问题可以分解为若干个规模较小的相同问题,即该问题具有最优子结构性质。
3) 利用该问题分解出的子问题的解可以合并为该问题的解;
4) 该问题所分解出的各个子问题是相互独立的,即子问题之间不包含公共的子子问题。
第一条特征是绝大多数问题都可以满足的,因为问题的计算复杂性一般是随着问题规模的增加而增加;
第二条特征是应用分治法的前提它也是大多数问题可以满足的,此特征反映了递归思想的应用;
第三条特征是关键,能否利用分治法完全取决于问题是否具有第三条特征,如果具备了第一条和第二条特征,而不具备第三条特征,则可以考虑用贪心法或动态规划法。
第四条特征涉及到分治法的效率,如果各子问题是不独立的则分治法要做许多不必要的工作,重复地解公共的子问题,此时虽然可用分治法,但一般用动态规划法较好。
step1 分解:将原问题分解为若干个规模较小,相互独立,与原问题形式相同的子问题;
step2 解决:若子问题规模较小而容易被解决则直接解,否则递归地解各个子问题
step3 合并:将各个子问题的解合并为原问题的解。
(1)二分搜索
(2)大整数乘法
(3)Strassen矩阵乘法
(4)棋盘覆盖
(5)合并排序
(6)快速排序
(7)线性时间选择
(8)最接近点对问题
(9)循环赛日程表
(10)汉诺塔
实际上就是类似于数学归纳法,找到解决本问题的求解方程公式,然后根据方程公式设计递归程序。
1、一定是先找到最小问题规模时的求解方法
2、然后考虑随着问题规模增大时的求解方法
3、找到求解的递归函数式后(各种规模或因子),设计递归程序即可。
所谓差分就是就是去维护一个数列的差值数组
前缀和其实可以把它理解为数学上的数列的前n项和(对于一个一维数组的前缀和)
这个好像也没什么了
二分答案要求满足条件的答案单调

step1: 在答案可能的范围内[L,R]二分查找答案,
step2: 检查当前答案是否满足题目的条件要求
step3: 根据判断结果更新查找区间,继续判断答案,达到最优值
(1)Codeforces 浇花
(2)NOIP2012 借教室
(3)NOIP2015 跳石头
(4)洛谷P1182 数列分段 Section II
(5)NOIP2011 聪明的质检员
(6)洛谷P1873 砍树
(7)洛谷P1577 切绳子
(8)洛谷P2390 地标访问
(9)洛谷P2440 木材加工
(10)洛谷P3853 [TJOI2007]路标设置
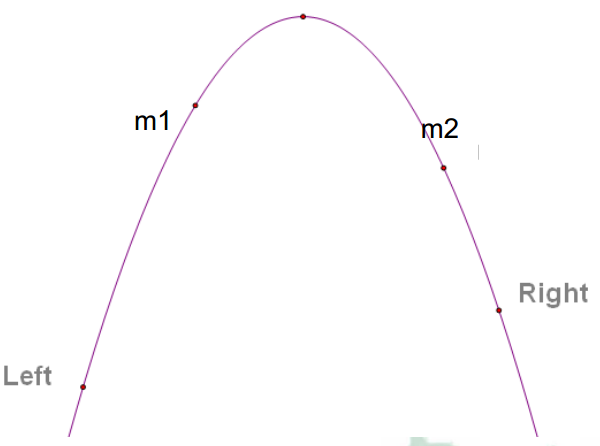
三分法的思路与二分法很类似,不过其用途没有那么广泛,主要用于求单峰函数的极值。
三分法,设当前区间在[L,R]
取三分点x1,x2
则区间被分为三块 [L,x1],[x1,x2],[x2,R]
这个时候看f(x1),f(x2)的关系
如果f(x1)<f(x2)说明解在[L,x2]中
否则如果说明解在[x1,R]当中
注意这里取得是x1(比较靠左的端点),就是为了解决x1,x2分别位于峰值的两边的情况,因为这样的话无论怎么搞都会将峰值囊括进去
重复上述过程,直到 L-R<EPS(精度要求)即可
学什么???sort不就好了吗???
“离散化,就是把无限空间中有限的个体映射到有限的空间中去,以提高算法的时空效率。”
很多算法的复杂度与数据中的最大值有关,比如树状数组和纯用数组实现的一对一标记。时常会遇到这种情况:数据的范围非常大或者其中含有负数,但数据本身的个数并不是很多(远小于数据范围)。在这种情况下,如果每个数据元素的具体值并不重要,重要的是他们之间的大小关系的话,我们可以先对这些数据进行离散化,使数据中的最大值尽可能小且保证所有数据都是正数。
例如,有这样一个长为5的序列:102131511,123,9813186,-611,55。其中有非常大的数以及负数,会给许多算法的实现带来困扰,我们可以把这个序列离散化,使它变成这样:5,3,4,1,2。各个元素间的大小关系没有任何改变,但数据的范围一下子就变得很舒服了。
离散化的原理和实现都很简单。为了确保不出错且尽可能地提高效率,我们希望离散化能实现以下几种功能:1.保证离散化后的数据非负且尽可能的小2.离散化后各数据项之间的大小关系不变,原本相等的也要保持相等。由此,找出数据项在原序列中从小到大排第几就是离散化的关键。
可以通过下面的方法以O(nlong)的时间复杂度完成离散化,n为序列长度。
1.对原序列进行排序,使其按升序排列。
2.去掉序列中重复的元素。
3.此时序列中各位置的值和位置的序号就是离散化的映射方式。
//树状数组
#include<iostream>
#include<cmath>
#include<cstring>
#include<algorithm>
#include<cstdio>
using namespace std;
#define int long long
const int maxn=1000100;
int t[maxn];
int r[maxn];
int n;
struct point{
int id;
int val;
}p[maxn];
inline int read(){
int x=0,w=1,ch=getchar();
for(;ch<‘0‘||ch>‘9‘;ch=getchar()) if(ch==‘-‘) w=-1;
for(;ch>=‘0‘&&ch<=‘9‘;ch=getchar()) x=x*10+ch-‘0‘;
return x*w;
}
bool cmp(point a,point b){
if(a.val==b.val) return a.id<b.id;
return a.val<b.val;
}
int lowbit(int x){
return x&(-x);
}
void add(int x){
while(x<=n){
t[x]+=1;
x+=lowbit(x);
}
}
int query(int x){
int ans=0;
while(x>=1){
ans+=t[x];
x-=lowbit(x);
}
return ans;
}
signed main(){
n=read();
for(int i=1;i<=n;i++){
p[i].val=read();
p[i].id=i;
}
sort(p+1,p+1+n,cmp);
for(int i=1;i<=n;i++) r[p[i].id]=i;
int sum=0;
for(int i=n;i>=1;i--){
add(r[i]);
sum+=query(r[i]-1);
}
cout<<sum<<endl;
return 0;
}
例题:
现在已知N和K,求1…N的所有特定排列,这些排列的逆序对的数量恰好为K。输出这些特定排列的数量。
将1…N的逆序对数量为K的特定排列的数量输出。为了避免高精度计算,请将结果mod 10000以后再输出
#include<iostream>
#include<cmath>
#include<cstring>
#include<algorithm>
#include<cstdio>
using namespace std;
const int maxn=1000100;
const int mod=10000;
int f[5000][5000];
int N,K;
int main(){
cin>>N>>K;
f[1][0]=1;
f[2][0]=1;
f[2][1]=1;
for(int i=3;i<=N;i++){
for(int j=0;j<=K;j++){
for(int k=0;k<=i-1&&j-k>=0;k++){
f[i][j]=(f[i][j]%mod+f[i-1][j-k]%mod)%mod;
}
}
}
cout<<f[N][K]<<endl;
return 0;
}
倍增就是根据已经得到的信息,将考虑的范围扩大一倍,从而加速操作的一种思想。
使用了倍增思想的算法有很多,包括归并排序、快速幂、基于ST表的RMQ算法(区间最值)和树上倍增找LCA等,还有FFT、后缀数组等高级算法
#include<iostream>
#include<cmath>
#include<cstring>
#include<cstdio>
#include<algorithm>
using namespace std;
const int maxn=500001;
struct yyy{
int to;
int next;
}e[2*maxn];
int depth[maxn],fa[maxn][21],lg[maxn],head[maxn];
int tot;
void add(int x,int y){
tot++;
e[tot].next=head[x];
e[tot].to=y;
head[x]=tot;
}
void dfs(int f,int fath){
depth[f]=depth[fath]+1;
fa[f][0]=fath;
for(int i=1;(1<<i)<=depth[f];i++) fa[f][i]=fa[fa[f][i-1]][i-1];
for(int i=head[f];i;i=e[i].next) if(e[i].to!=fath) dfs(e[i].to,f);
}
int lca(int x,int y){
if(depth[x]<depth[y]) swap(x,y);
while(depth[x]>depth[y]) x=fa[x][lg[depth[x]-depth[y]]-1];
if(x==y) return x;
for(int k=lg[depth[x]]-1;k>=0;k--) if(fa[x][k]!=fa[y][k]) x=fa[x][k],y=fa[y][k];
return fa[x][0];
}
int n,m,s;
int x,y;
int main(){
scanf("%d%d%d",&n,&m,&s);
for(int i=1;i<=n-1;i++){
scanf("%d%d",&x,&y);
add(x,y);
add(y,x);
}
dfs(s,0);
for(int i=1;i<=n;i++) lg[i]=lg[i-1]+(1<<lg[i-1]==i);
for(int i=1;i<=m;i++){
scanf("%d%d",&x,&y);
printf("%d\n",lca(x,y));
}
return 0;
}
所谓lca倍增算法,就是按2的倍数来增大,也就是跳 1,2,4,8,16,32 …… 不过在这我们不是按从小到大跳,而是从大向小跳,即按……32,16,8,4,2,1来跳,如果大的跳不过去,再把它调小。这是因为从小开始跳,可能会出现“悔棋”的现象。拿 55 为例,从小向大跳,5≠1+2+4,所以我们还要回溯一步,然后才能得出5=1+4;而从大向小跳,直接可以得出5=4+5=4+1。这也可以拿二进制为例,5(101),从高位向低位填很简单,如果填了这位之后比原数大了,那我就不填,这个过程是很好操作的。
#include<cstdio>
#include<iostream>
using namespace std;
struct edge{
int to,ne;
}e[1000005];
int n,m,s,ecnt,head[500005],dep[500005],siz[500005],son[500005],top[500005],f[500005];
void add(int x,int y)
{
e[++ecnt].to=y;
e[ecnt].ne=head[x];
head[x]=ecnt;
}
void dfs1(int x)
{
siz[x]=1;
dep[x]=dep[f[x]]+1;
for(int i=head[x];i;i=e[i].ne)
{
int dd=e[i].to;
if(dd==f[x])continue;
f[dd]=x;
dfs1(dd);
siz[x]+=siz[dd];
if(!son[x]||siz[son[x]]<siz[dd])
son[x]=dd;
}
}
void dfs2(int x,int tv)
{
top[x]=tv;
if(son[x])dfs2(son[x],tv);
for(int i=head[x];i;i=e[i].ne)
{
int dd=e[i].to;
if(dd==f[x]||dd==son[x])continue;
dfs2(dd,dd);
}
}
int main()
{
scanf("%d%d%d",&n,&m,&s);
for(int i=1;i<n;++i)
{
int x,y;
scanf("%d%d",&x,&y);
add(x,y);
add(y,x);
}
dfs1(s);
dfs2(s,s);
for(int i=1;i<=m;++i)
{
int x,y;
scanf("%d%d",&x,&y);
while(top[x]!=top[y])
{
if(dep[top[x]]>=dep[top[y]])x=f[top[x]];
else y=f[top[y]];
}
printf("%d\n",dep[x]<dep[y]?x:y);
}
}
树剖就是把树剖分成若干条不相交的链,目前常用做法是剖成轻重链
所以我们定义siz[x]为以x为根结点的子树的结点个数
对于每个结点x,在它的所有子结点中寻找一个结点y
使得对于y的兄弟节点z,都有siz[y]≥siz[z]
此时x就有一条重边连向y,有若干条轻边连向他的其他子结点【比如z】
这样的话,树上的不在重链上的边的数量就会大大减少
然后我们每次求LCA(x,y)的时候就可以判断两点是否在同一链上
如果两点在同一条链上我们只要找到这两点中深度较小的点输出就行了
如果两点不在同一条链上
那就找到深度较大的点令它等于它所在的重链链端的父节点即为x=f[top[x]]
直到两点到达同一条链上,输出两点中深度较小的点
ST表的功能很简单
它是解决RMQ问题(区间最值问题)的一种强有力的工具
它可以做到O(nlogn)O(nlogn)预处理,O(1)O(1)查询最值
ST表是利用的是倍增的思想
拿最大值来说
我们用Max[i][j]Max[i][j]表示,从ii位置开始的2^j2 j 个数中的最大值,例如Max[i][1]Max[i][1]表示的是ii位置和i+1i+1位置中两个数的最大值
那么转移的时候我们可以把当前区间拆成两个区间并分别取最大值(注意这里的编号是从11开始的)
查询的时候也比较简单
我们计算出log_2{\text{区间长度}}log 2 区间长度 然后对于左端点和右端点分别进行查询,这样可以保证一定可以覆盖查询的区间
#include<cstdio>
#include<cmath>
#include<algorithm>
using namespace std;
const int MAXN=1e6+10;
inline int read()
{
char c=getchar();int x=0,f=1;
while(c<‘0‘||c>‘9‘){if(c==‘-‘)f=-1;c=getchar();}
while(c>=‘0‘&&c<=‘9‘){x=x*10+c-‘0‘;c=getchar();}
return x*f;
}
int Max[MAXN][21];
int Query(int l,int r)
{
int k=log2(r-l+1);
return max(Max[l][k],Max[r-(1<<k)+1][k]);//把拆出来的区间分别取最值
}
int main()
{
#ifdef WIN32
freopen("a.in","r",stdin);
#endif
int N=read(),M=read();
for(int i=1;i<=N;i++) Max[i][0]=read();
for(int j=1;j<=21;j++)
for(int i=1;i+(1<<j)-1<=N;i++)//注意这里要控制边界
Max[i][j]=max(Max[i][j-1],Max[i+(1<<(j-1))][j-1]);//如果看不懂边界的话建议好好看看图
for(int i=1;i<=M;i++)
{
int l=read(),r=read();
printf("%d\n",Query(l,r));
}
return 0;
}
顾名思义,贪心算法总是作出在当前看来最好的选择。也就是说贪心算法并不从整体最优考虑,它所作出的选择只是在某种意义上的局部最优选择。当然,希望贪心算法得到的最终结果也是整体最优的。虽然贪心算法不能对所有问题都得到整体最优解,但对许多问题它能产生整体最优解。如单源最短路经问题,最小生成树问题等。在一些情况下,即使贪心算法不能得到整体最优解,其最终结果却是最优解的很好近似。
1.贪心选择性质。所谓贪心选择性质是指所求问题的整体最优解可以通过一系列局部最优的选择,即贪心选择来达到。这是贪心算法可行的第一个基本要素,也是贪心算法与动态规划算法的主要区别。
动态规划算法通常以自底向上的方式解各子问题,而贪心算法则通常以自顶向下的方式进行,以迭代的方式作出相继的贪心选择,每作一次贪心选择就将所求问题简化为规模更小的子问题。
对于一个具体问题,要确定它是否具有贪心选择性质,必须证明每一步所作的贪心选择最终导致问题的整体最优解。
从问题的某一个初始解出发逐步逼近给定的目标,以尽可能快的地求得更好的解。当达到算法中的某一步不能再继续前进时,算法停止。
该算法存在问题:
不能保证求得的最后解是最佳的;
不能用来求最大或最小解问题;
只能求满足某些约束条件的可行解的范围。
实现该算法的过程:
从问题的某一初始解出发;
while 能朝给定总目标前进一步 do
求出可行解的一个解元素;
由所有解元素组合成问题的一个可行解;
推荐一个博客:https://blog.csdn.net/u010182186/article/details/52836284
写的真的非常好
标签:arc ORC 技巧 char dfs 设计思想 形式 val 乘法
原文地址:https://www.cnblogs.com/zxjg/p/11642909.html