标签:语句 原则 ted 相同 class 一起 throws size int
本文的内存模型只写虚拟机内存模型,物理机的不予描述。
在Java中,虚拟机将运行时区域分成6中,如下图:
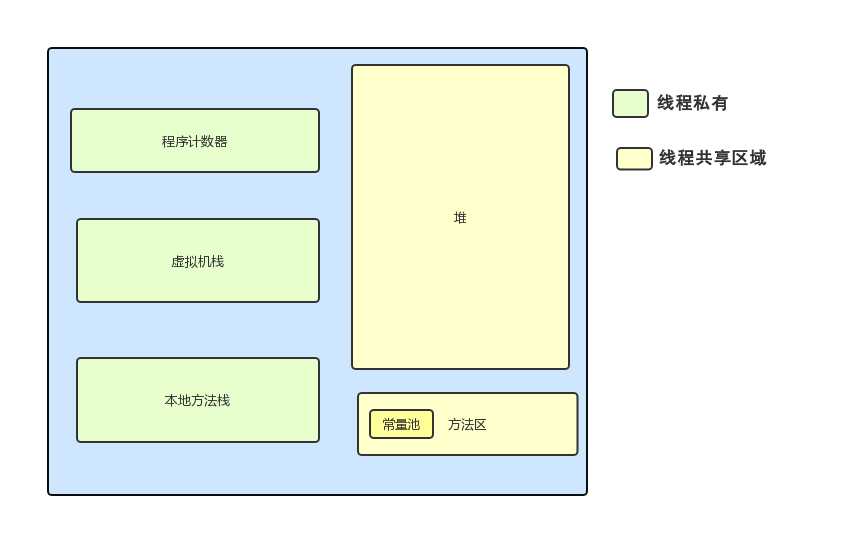
由于类和方法的信息难以确定,不好设定大小,太大则影响年老代,太小容易内存溢出。
GC不好处理,回收效率低下,调优困难。
在上面的6种类型中,前三种是线程私有的,也就是说里面存放的值其他线程是看不到的,而后面三种(真正意义上讲只有堆一种)是线程之间共享的,这里面的变量对于各个线程都是可见的。如下图所示,前三种存放在线程内存中,大家都是相互独立的,而主内存可以理解为堆内存(实际上只是堆内存中的对象实例数据部分,其他例如对象头和对象的填充数据并不算入在内),为线程之间共享:
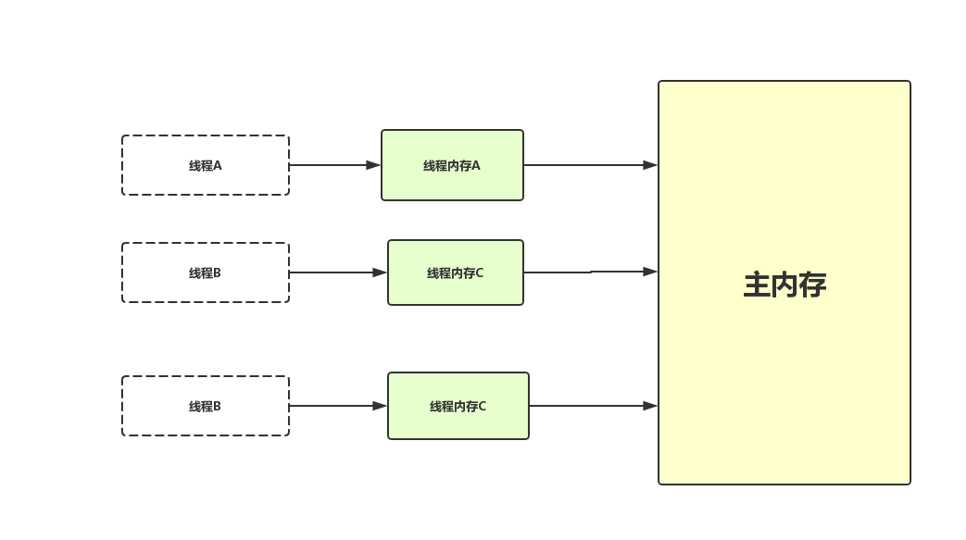
这里的变量指的是可以放在堆中的变量,其他例如局部变量、方法参数这些并不算入在内。线程内存跟主内存变量之间的交互是非常重要的,Java虚拟机把这些交互规范为以下8种操作,每一种都是原子性的(非volatile修饰的Double和Long除外)操作。
可能有同学会不理解read和load、store和write的区别,觉得这两对的操作类似,可以这样理解:一个是申请操作,另一个是审核通过(允许赋值)。例如:线程内存A向主内存提交了变更变量的申请(store操作),主内存通过之后修改变量的值(write操作)。可以通过下面的图来理解:
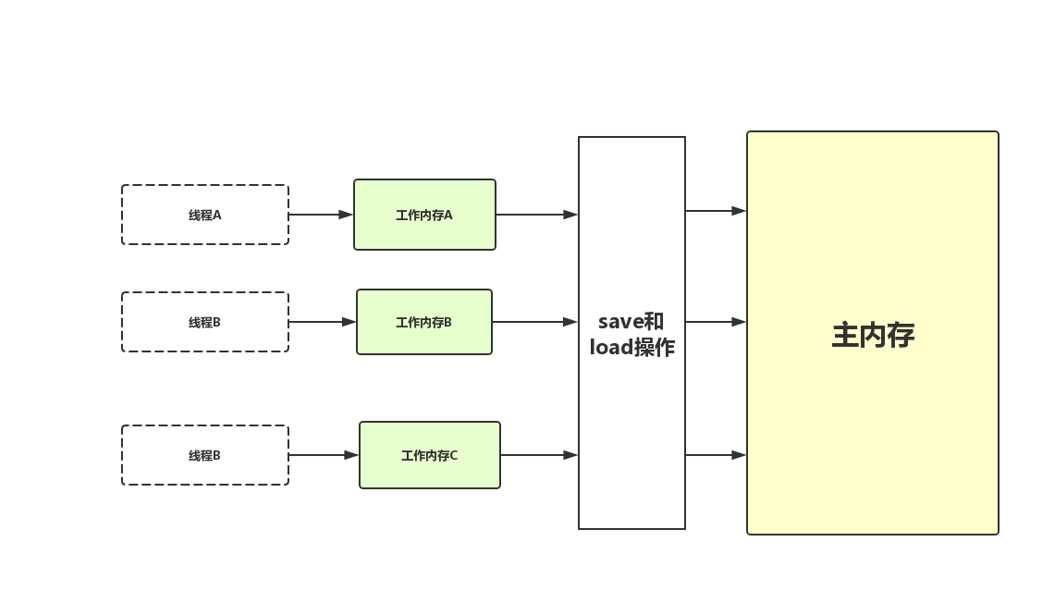
参照《深入理解Java虚拟机》
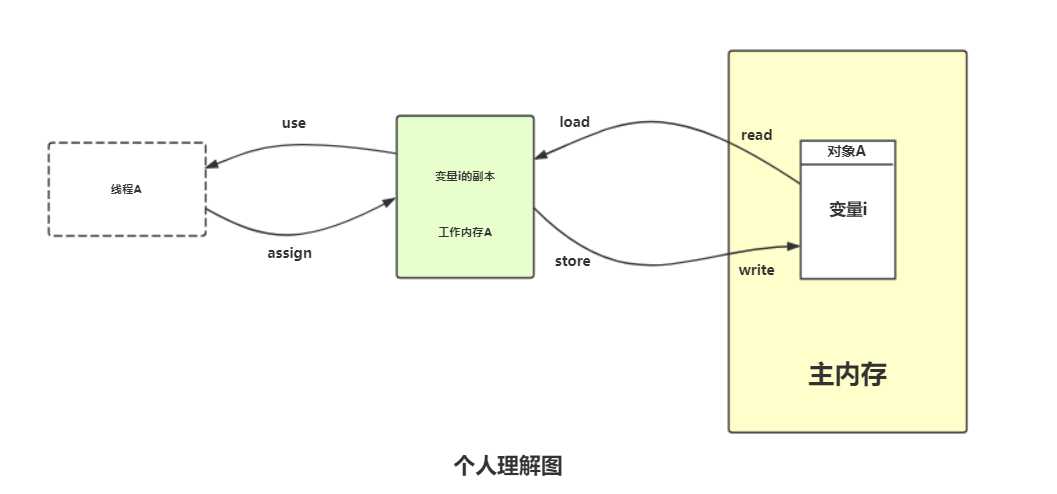
对于普通的变量来说(非volatile修饰的变量),虚拟机要求read、load有相对顺序即可,例如从主内存读取i、j两个变量,可能的操作是read i->read j->load j-> load i,并不一定是连续的。此外虚拟机还为这8种操作定制了操作的规则:
对于关键字volatile,大家都知道其一般作为并发的轻量级关键字,并且具有两个重要的语义:
但这两个语义都是因为在使用volatile关键字修饰变量的时候,内存间变量的交互规则会发生一些变化:
从上面volatile的特殊规则中,我们可以知道1、2条其实就是volatile内存可见性的语义,第三条就是禁止指令重排序的语义。另外还有其他的一些特殊规则,例如对于非volatile修饰的double或者long这两个64位的数据类型中,虚拟机允许对其当做两次32位的操作来进行,也就是说可以分解成非原子性的两个操作,但是这种可能性出现的情况也相当的小。因为Java内存模型虽然允许这样子做,但却“强烈建议”虚拟机选择实现这两种类型操作的原子性,所以平时不会出现读到“半个变量”的情况。
虽然volatile修饰的变量可以强制刷新内存,但是其并不具备原子性,稍加思考就可以理解,虽然其要求对变量的(read、load、use)、(assign、store、write)必须是连续出现,即以组的形式出现,但是这两组操作还是分开的。比如说,两个线程同时完成了第一组操作(read、load、use),但是还没进行第二组操作(assign、store、write),此时是没错的,然后两个线程开始第二组操作,这样最终其中一个线程的操作会被覆盖掉,导致数据的不准确。如果你觉得这是JOJO的奇妙比喻,可以看下面的代码来理解
public class TestForVolatile { public static volatile int i = 0; public static void main(String[] args) throws InterruptedException { // 创建四个线程,每个线程对i执行一定次数的自增操作 new Thread(() -> { int k = 0; while (k++ < 10000) { i++; } System.err.println("线程" + Thread.currentThread().getName() + "执行完毕"); }).start(); new Thread(() -> { int k = 0; while (k++ < 10000) { i++; } System.err.println("线程" + Thread.currentThread().getName() + "执行完毕"); }).start(); new Thread(() -> { int k = 0; while (k++ < 10000) { i++; } System.err.println("线程" + Thread.currentThread().getName() + "执行完毕"); }).start(); new Thread(() -> { int k = 0; while (k++ < 10000) { i++; } System.err.println("线程" + Thread.currentThread().getName() + "执行完毕"); }).start(); // 睡眠一定时间确保四个线程全部执行完毕 Thread.sleep(1000);
// 最终结果为33555,没有预期的4W System.out.println(i);
} }
结果图:
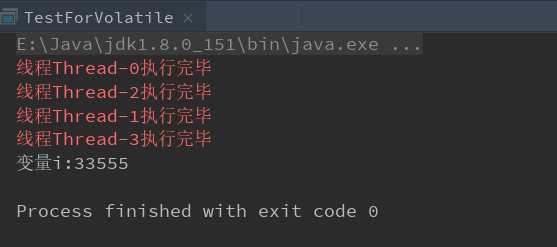
解释一下:因为i++操作其实为i = i + 1,假设在主内存i = 99的时候同时有两个线程完成了第一组操作(read、load、use),也就是完成了等号后面变量i的读取操作,这时候是没问题的,然后进行运算,都得出i+1=100的结果,接着对变量i进行赋值操作,这就开始第二组操作(assign、store、write),是不是同时赋值的无所谓,这样一来,两个线程都会以i = 100把值写到主内存中,也就是说,其中一个线程的操作结果会被覆盖,相当于无效操作,这就导致上面程序最终结果的不准确。
如果要保证原子性的话可以使用synchronize关键字,其可以保证原子性和内存可见性(但是不具备有禁止指令重排序的语义,这也是为什么double-check的单例模式中,实例要用volatile修饰的原因);当然你也可以使用JUC包的原子类AtomicInteger之类的。
暂时写到这里,其他关于重排序、内存屏障和happens-before原则等内容后面再进行补充。如果文章有任何不对的地方望大家指出,感激不尽!
标签:语句 原则 ted 相同 class 一起 throws size int
原文地址:https://www.cnblogs.com/zhangweicheng/p/11638841.html