标签:文件拷贝 很多 表示 描述 -- inf mdf 节点 img
前言
本篇主要是上一篇文章的补充篇,上一篇我们介绍了SQL Server服务启动过程所遇到的一些问题和解决方法,可点击查看,我们此篇主要介绍的是SQL Server启动过程中关于用户数据库加载的流程,并且根据加载过程中所遇到的一系列问题提供解决方案。
其实SQL Server作为微软的一款优秀RDBMS,它启动的过程中,本身所带的那些系统库发生问题的情况相对还是很少的,我们在平常使用中,出问题的大部分集中于我们自己建立的用户数据库。
而且,相对于侧重面而言,其实我们更关注的是我们自己建立的用户数据库,假如系统数据库出现问题,甚至实例出现问题,最坏的情况我们重搭环境,但是如果我们应用的用户数据库坏掉了,那可不是重搭环境就能解决的。这牵扯到公司利益问题,问题严重性不言而喻!
闲言少叙,我们速度进入本篇的正题。
上一篇我们介绍了SQL Server实例启动的过程,并且分析了其详细的过程,而在这一流程中,有一个步骤非常关键,就是加载恢复用户数据库的过程,我们来截取这段日志信息:
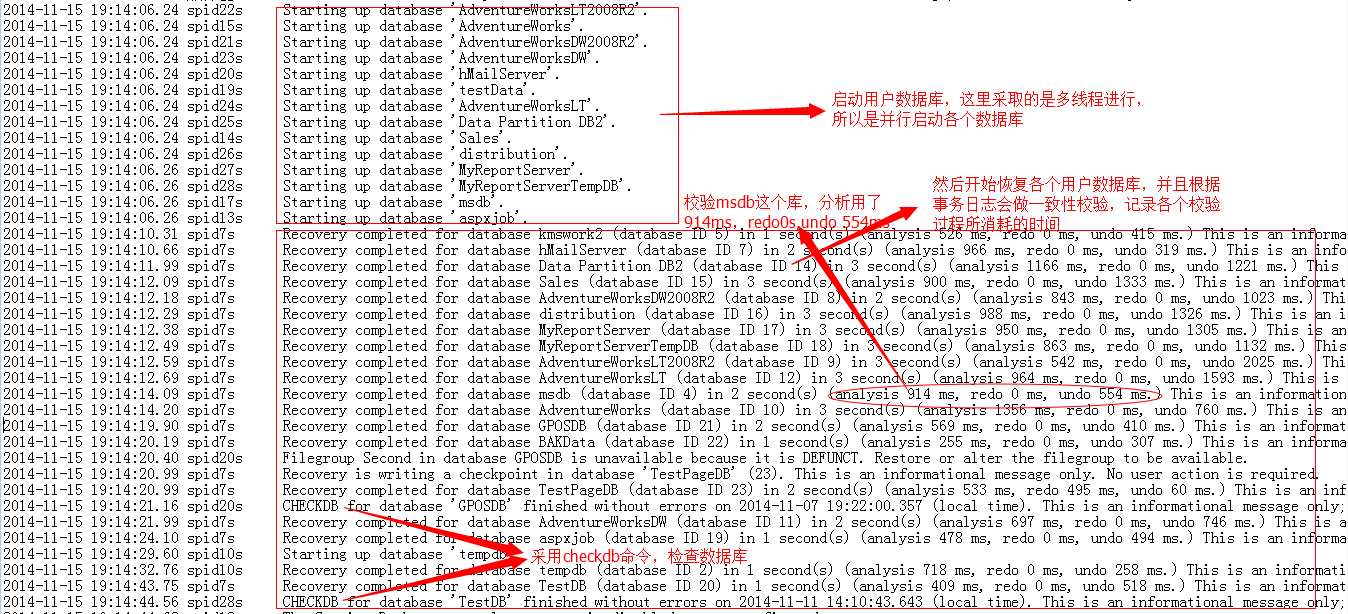
上面是一个正常启动各个用户库的流程,SQL Server会采用多线程的进行数据库启动,并且在这个过程中进行一致性校验,确保启动的数据库能够正常使用。
而这过程中会发生很多问题,在分析问题之前,我先要介绍SQL Server数据库的几个常见状态:
RECOVERING(恢复中):
这个状态表示数据在启动完成后,正在发生恢复,也就是上面日志中的 Recovery过程,和其它的关系型数据库一样,SQL Server对所有的数据库行为都是先写事务日志,然后在修改内存中的数据,然后通过后台的一个进程在适当的时候进行写入硬盘(Lazy write),所以在数据库运行过程中,磁盘中的数据并不是最新的,如果这个时候关闭了,在下一次启动过程中SQL Server就要根据事务日志中的记录,将磁盘中的旧的数据改写,改写过程为:
1、重做redo
2、回滚和撤销 undo/rollback
上面的目的就是为了保证数据库一致性。
如果上面的流程发生了问题,就会进去到下面这个状态:
RECOVERY PENDING(挂起还原):
这个过程就是将恢复数据的过程挂起,挂起的原因基本就是不能正常打开所用的数据库文件。这里先记住这个状态就行,我在后面的内容会再现这个问题,以及给出解决方案。
如果能找到文件或者能打开文件,但是文件有问题,机会出现下面这个状态:
SUSPECT(质疑):
这个状态,我相信很多用户如果在玩数据库久了的时候,会偶尔遇到,相对于其它状态,这个状态是出现最高的。
原因很简单:数据库文件坏掉了。
当经历了上面的这个几个状态都不出现问题,上面的这几个状态下,数据库都是不能使用的,会进入到下面这个状态:
ONLINE(在线):
这个状态应该是最期待的了,数据库在线,正常使用,默认都是正常的在线状态。
当然,除了上面几个数据库自己形成的数据库状态,在我们管理员处理数据库的时候也会更改状态,这里我们顺便提一下:
OFFLINE(离线):有在线状态就有离线状态,很简单,让数据库离线,用户不能使用
RESTORING(还原中):这个状态很简单,管理员正在还原该数据库,不解释
EMERGENCY(紧急):这个状态也是管理员用的,就是说明数据库有问题了,它正在尽量解决
以上几个状态中,发生在启动过程中,并且会发生问题就是上面的RECOVERY PENDING(挂起还原)、SUSPECT(质疑)、RECOVERING(恢复中):
我们依次来看:
RECOVERY PENDING(挂起还原):
出现这个状态通常的原因是数据库文件找不到,或者文件找到权限访问不到,我们来看该问题报错信息:
在数据库中存储方式中,分为主文件组和辅助文件组和日志文件,为了展示方便我们特意建立了个测试库,来重现该部分问题:
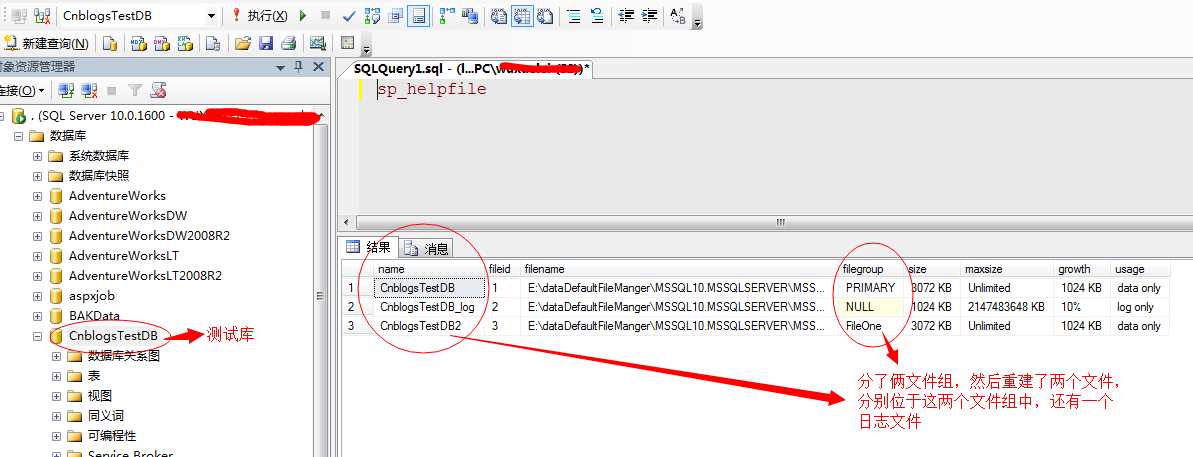
<1>主文件组问题
当不能访问主文件组文件的时候,也就是上面的CnblogsTestDB.mdf文件,会报如下错误:
我们先来看数据库:
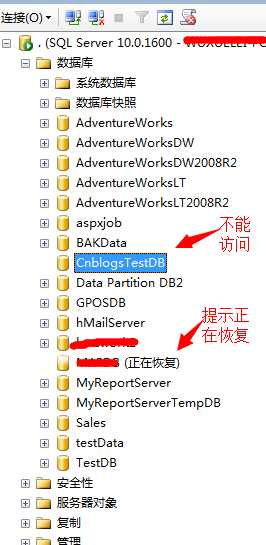
在实例启动的过程,恰巧有一个库显示了上面我们提到的一个状态:RECOVERING(恢复中),我顺便把图给截图了,当然出现这个情况很正常,有时候刷新一下就正常,其它用户库没有显示是因为库太小,恢复时间太短,我们捕捉不到。
我们来看,上面我们建立的测试库CnblogsTestDB已经不能访问了,我们来看一下Error中的错误信息:
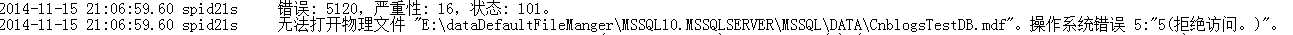
错误信息很明显,说这个该文件不能访问,并且确切的说出了这个为操作系统错误,那我们看操作系统的错误记录:
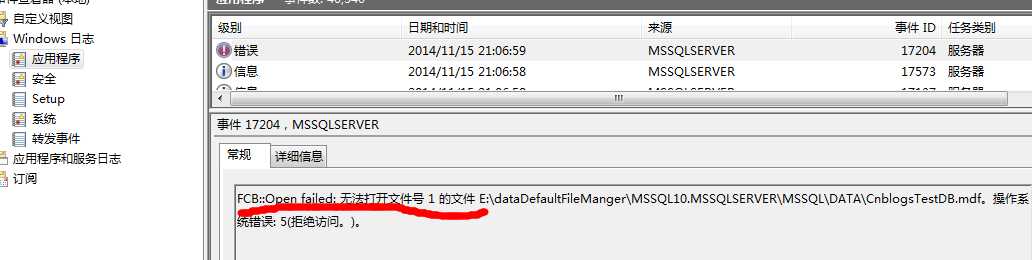
可以看到在Windows系统日志中也能看到该部分错误信息。
解决方案:
此问题的解决方法还是很简单的,一般主要是因为权限问题,只需要将数据库管理员账户组,提权到可读写权限就可以,然后重启服务:
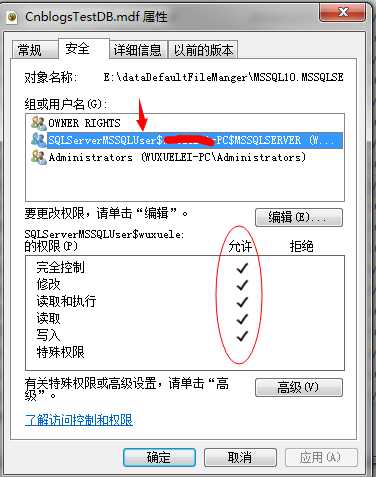
上面的情况是找到数据库文件,但是不能打开数据库文件,当然还有可能是直接找不到数据库文件,系统会报出如下错误:

会给出17204错误,报找不到文件错误
解决方案:
a、如果能找到数据文件最好了,拷贝到错误制定的路径下既可以,然后重启实例
b、不能找到文件了,那就得只能删除该库,重新新建同名库,从备份文件中还原
一般上述问题发生在物理存储出现了故障,当然不排除某些软件操作,比如杀毒软件、还有人为误删等原因。如果没有备份,这可能是一个很大的遭难,基本可以确定的完全还原的可能性不高!所以记住:备份数据库的重要性!
<2>辅助文件组问题
上面的出现问题的文件为数据库的主文件组,当我们数据库在承载到一定数据量的情况下,我么采取多个辅助文件组来容纳数据,下面我们来看一下辅助文件组的问题:

同样的提示的辅助文件组不能正常打开,或者找不到相关的辅助文件组,遇到这样的问题我们怎么解决呢?
其实SQL Server数据库辅助文件存储的主要为数据库的数据内容信息,关于本库的一些架构信息是放在主(primary)文件组中,所以我们可以先这样
解决方案:
a、我们将打不开或者不能访问的数据库文件(辅助文件)设置成离线,然后先将能够正常的数据文件上线,确保除了损坏的那部分文件的其它库信息能正常访问,我们通过以下代码更改:
ALTER DATABASE CnblogsTestDB MODIFY FILE(NAME=CnblogsTestDB2,OFFLINE)
GO
ALTER DATABASE CnblogsTestDB set ONLINE
GO
这样,我们刷新下数据库,既可以正常访问正确的数据信息:
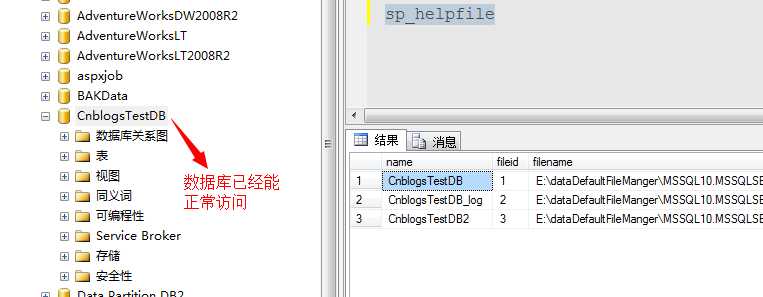
当我们处于生产环境中,生产库不能正常启动的时候,此刻的火烧眉毛的时刻,采取上面的方法先确保一部分数据能正常访问也不失为一种缓议之计。
下面的步骤就是找到该辅助文件,并且确保有正常的权限访问,更重要的是找到的辅助文件不能是损坏的,然后拷贝至错误文件中给出的路径,然后重启实例,上线该库。
b、当然大部分情况下,我们找不到该文件,或者这个文件已经损坏,那就得采取第二种方案,通过备份还原,根据以往的经验,建议采取的措施是:
先将能访问的数据库做一次备份,然后通过文件组恢复的方式,恢复上面出问题的文件组。
<3>日志文件组
其实从市面上的所有数据库而言,其本身所有的机制都是通过先写日志,然后通过一个进程后写入(lazy write)方式写入到磁盘,这种方式是为了避免IO的阻塞,因为我们都知道磁盘IO这个问题一直是所有文件读写的最大瓶颈。
所以,日志文件是数据库不可分割的一部分。当数据库在启动的过程,会通过日志中的记录做一次数据的一致性校验,文章的开端有介绍。
所以说,如果日志文件不能访问,或者说出问题,那我们的SQL Server数据库会出现什么问题呢?
我们先来看数据库模式为简单(SIMPLE)模式的,我将咱们的测试库设置成简单模式:
USE CnblogsTestDB GO ALTER DATABASE [CnblogsTestDB] SET RECOVERY SIMPLE WITH NO_WAIT GO
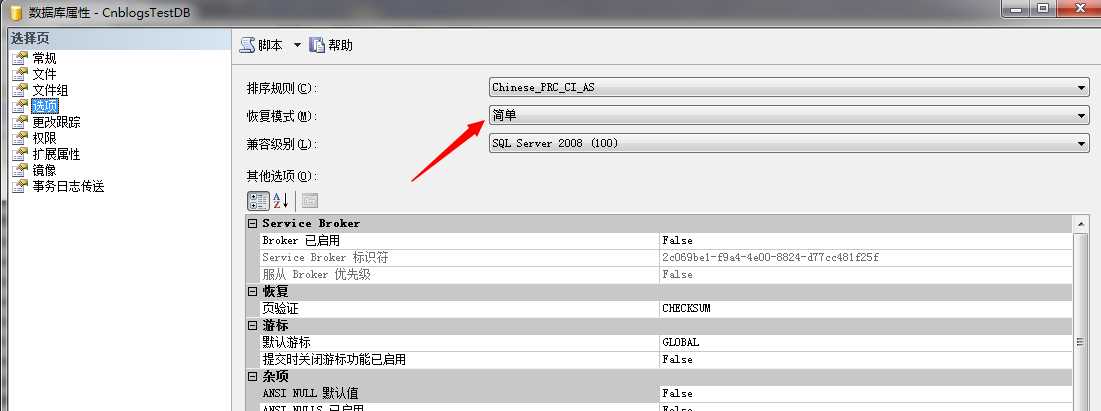
然后我们停掉实例,然后删除掉该库的日志文件,然后重新启动
可以看到处于简单模式下,如果日志文件出现错误,在启动的过程是不会发生任何问题的,这里的原因我们在启动Error日志文件中能找到答案:

经过上面的日志分析,我们可以看到,当数据库处于简单模式下,数据库在启动的过程中,如果发现任何与日志相关的信息,则会重新创建一份日志文件,保证数据库的正常访问。
如果这样那我们数据库的完整性怎么保证呢,是这样,如果数据库处于简单模式,在我们数据库关闭的时候,系统会先将该提交的所有事务都写入到磁盘中去,所有该回滚的就撤销。
上面能正常创建数据库日志文件的前提条件有两条:1、数据库为简单模式;2、数据库正常关闭,保证事务都已正常写入磁盘
下面我们在看看如果恢复模式为“完整”模式下的,数据库上次没有正常的情况,SQL Server数据库是如何处理的,
我们先将数据库改成完整恢复模式,停掉实例,然后删除日志,然后启动
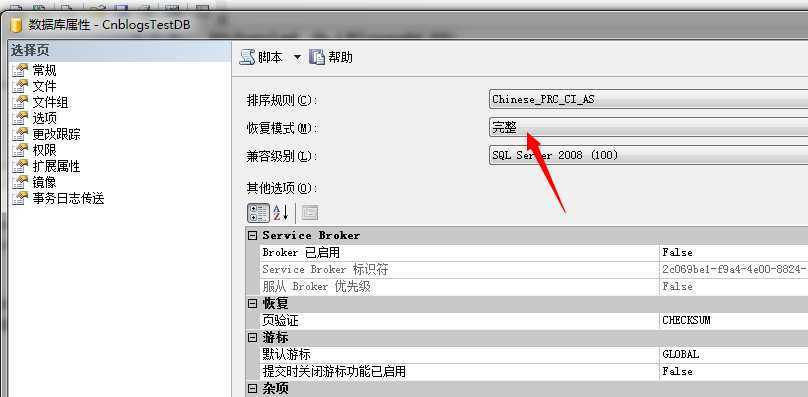
然后我们启动,可以看到这个时候,数据库不能正常访问的,该错误的Error的日志信息为:

windows平台下也为我们记录了该错误的日志信息:
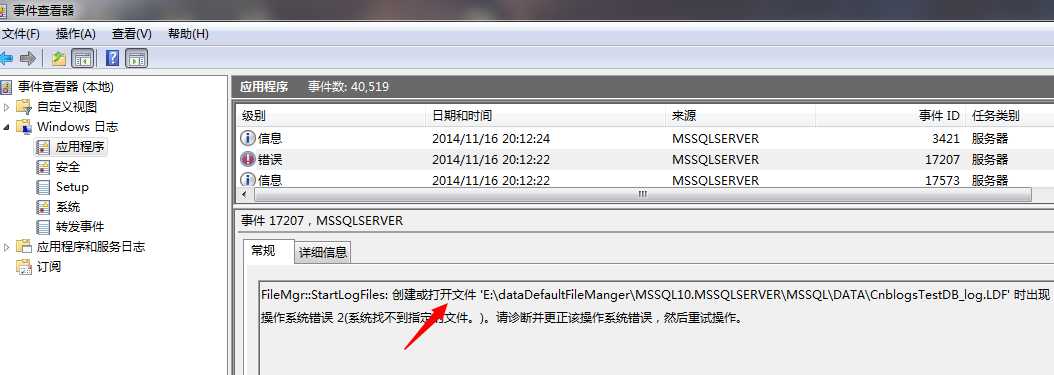
其实出现上面的错误,很正常,因为有些数据库的事务性操作已经记录到事务日志中,还未写入磁盘数据页中,这时候发生了宕机,或者非正常关闭,这个对SQL Server数据库是能应付的,但是,而在启动的过程找不到相关的事务日志尽心回滚和写入操作,所以该库的数据时非一致性的,所以SQL Server是不让我们使用该库,出现此种错误,我们的解决方式有如下几种:
解决方案:
a、如果有备份,最好最快的方式就是恢复数据库备份或者找到了该日志文件拷贝到错误路径下(推荐)
b、如果没有备份,我们只能通过使用CHECKDB命令修复数据库(不推荐)
上述解决方案中CHECKDB命令,是一种万不得已的方式,而且,我可以明确的告诉你这命令使用的时候会可能造成数据丢失,并且在大数据库中,运行周期很长!
当然在万不得已的情况下,我们还的采取,过程如下:
我们先将数据库设置成EMERGENCY(紧急)模式,并且为单用户(SINGLE_USER)模式
USE CnblogsTestDB GO ALTER DATABASE CnblogsTestDB SET EMERGENCY GO ALTER DATABASE CnblogsTestDB SET SINGLE_USER GO
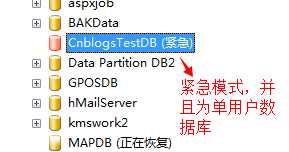
经过我们上面的设置,将库设置成了“紧急”模式,并且只为单用户方式访问,便于我们进行数据修复
然后我们执行CHECKDB命令,进行数据库的修复
DBCC CHECKDB(CnblogsTestDB,REPAIR_ALLOW_DATA_LOSS) GO
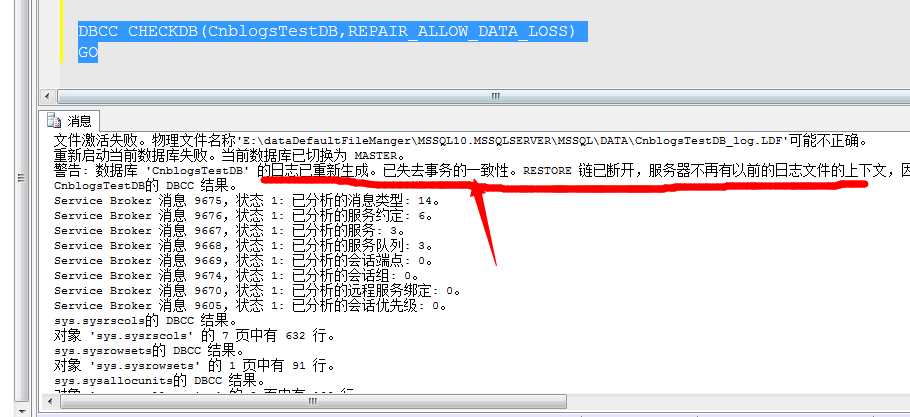
经过该命令的修复,数据库会为系统新建一个日志,但是不能保证事务的一致性,也就是说会因此而丢失数据,所以非常不推荐的一种方式!
并且,在这过程中,如果是大数据库的话,该修复过程会很漫长,当然我不能给出一个漫长参考值,因为这过程还有会出现其它的错误需要修复。
所以酌情考量。
当然,在恢复完成之后,不要忘记将数据库改回多用户模式
USE [master] GO ALTER DATABASE [CnblogsTestDB] SET MULTI_USER WITH ROLLBACK IMMEDIATE GO
至此,这个有问题的库就能够正常访问了。
----------------------------------------------------------霸气的分割线-----------------------------------------------------------------------
在经历了上面的文件级别错误后,在数据库启动的过程,还经常出现的是数据页级别的错误,相对于上面的文件错误级别,在数据页中造成的错误粒度更小,并且基本不会反映到数据库级别,也就是说在出现数据页级别的错误时候,该数据时可以正常访问的,只是在访问有错误的数据页的时候才会报错,在我们遇到这种错误的时候该如何解决呢?
下面我们依次来分析,首先我们来制作一个经典的824错误,以下部分内容牵扯到数据库部分基础,限于篇幅,我们不做详细介绍:
<1>首先我们在我们的测试库中新建一个表,我们将该表新建成一行为一个数据页的方式,也就是说一行数据库在数据库中就能承载一个数据页

USE CnblogsTestDB
GO
CREATE TABLE [dbo].[TestPage]
(
[a] [int] NULL,
[b] [nvarchar](3900) NULL
) ON [PRIMARY]
脚本很简单,一张表,两列,一列int类型,一列nvarchar(3900),一行数据的存储空间为:3900*2(nvarchar(3900))字节+4(int)+96字节(页头)+36字节(行偏移)=7932字节,我们知道一个数据页存储的信息为8K=8192字节,包括其它消耗所以该表一行数据如果填充完,一行数据将近乎占据一个数据页。
我们来添加三行数据,然后查看页信息:
--插入三条数据 insert [TestPage] values(1,REPLICATE(‘A‘,3900)) insert [TestPage] values(2,REPLICATE(‘B‘,3900)) insert [TestPage] values(3,REPLICATE(‘C‘,3900)) go --查看页信息 dbcc traceon(3604) --查看库中页集合 dbcc extentinfo(CnblogsTestDB,[TestPage])
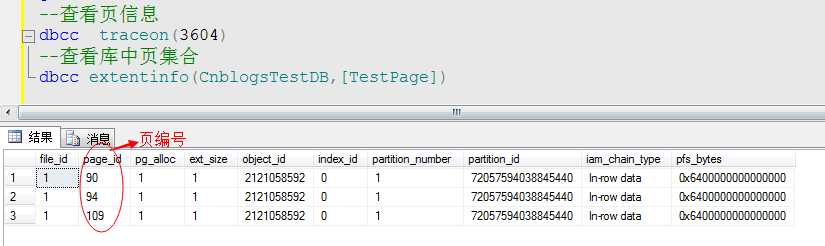
可以看到,该表中现在有三个数据页,我们来看看数据页应该也是近乎沾满的。
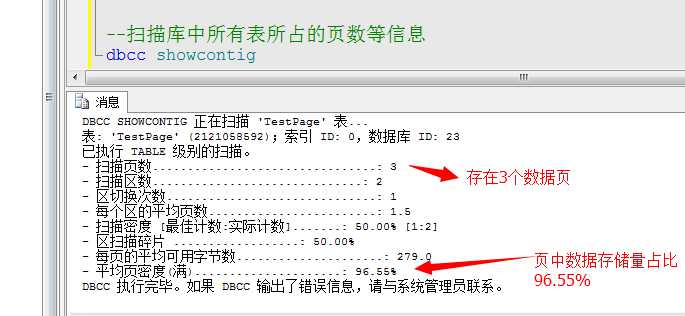
上图显示了,通过扫描表信息,共含有3个数据页,每个数据页中的数据量存储占比到了96.55%,也就是说基本上是填充满了。
当然,我们还可以通过DBCC PAGE命令,来查看每个页中的具体内容,我们简单的看一个页面编号为90的数据页:
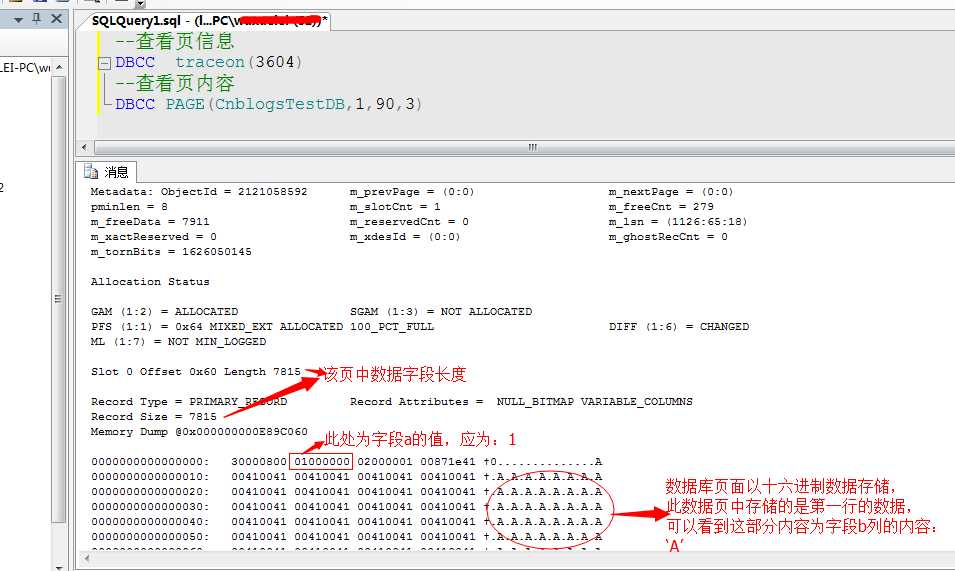
通过上面的命令可以看到,该数据页中存储的为表中的第一行的数据,并且在数据库存储文件中是以十六进制方式编码存储。
当然,如果感觉此方式不直观,可以利用一个小工具进行数据页的查看,这里我推荐使用Internal Views(此工具在桦仔的博文中有详细介绍),可更直观的展示数据存储页信息:
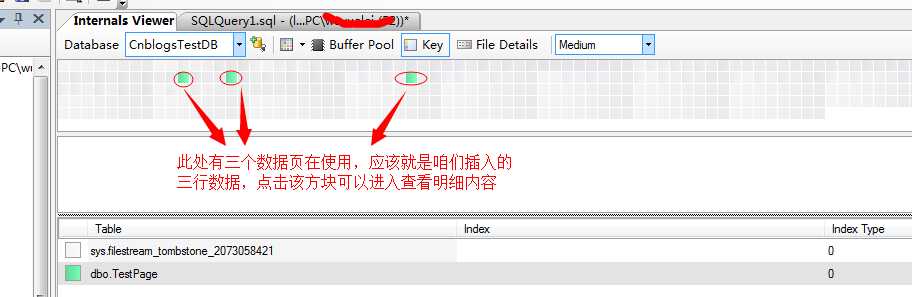
这里我们可以点击我上面上面查看的第一行的数据内容页进行查看
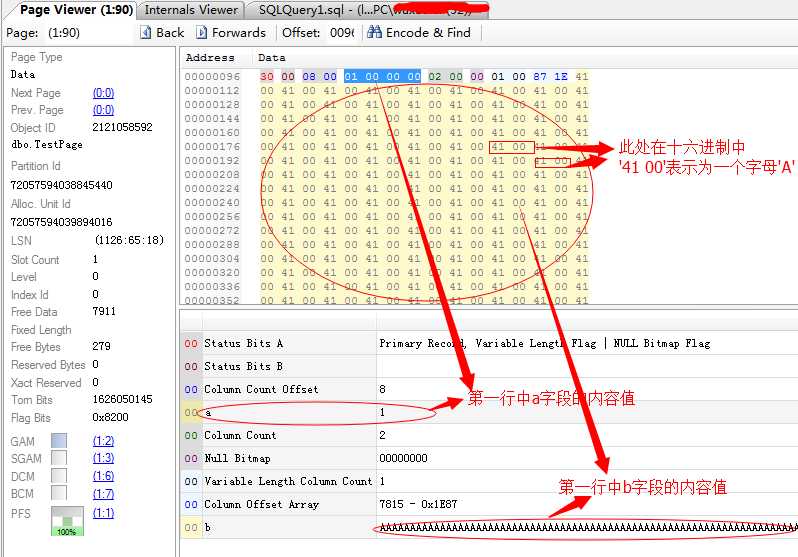
经过上面的分析步骤,其实我的目的是想重现在SQL Server启动过程中,或者在线上的数据库经常遇到的经典错误824错误
上述过程是原理篇,因为我们必须知道数据存储的底层原理,才能理解好这个错误的原因,以及找到正确的处理方法。
下一步,我们来重现这个错误的原因,我们知道在我新建的测试表中含有两个字段:a和b,并且a为int类型、b为nvarchar类型
然后我们介绍了底层的存储机制,我现在将第一列a字段的整形数据内容存储改成字符串类型,依次来损坏掉该数据页内容
我先将服务停掉,然后用文件编辑工具,修改此数据页内容,该数据页内容为十六进制内容,当然在我搞坏这部分数据页之前我先做一个完整备份
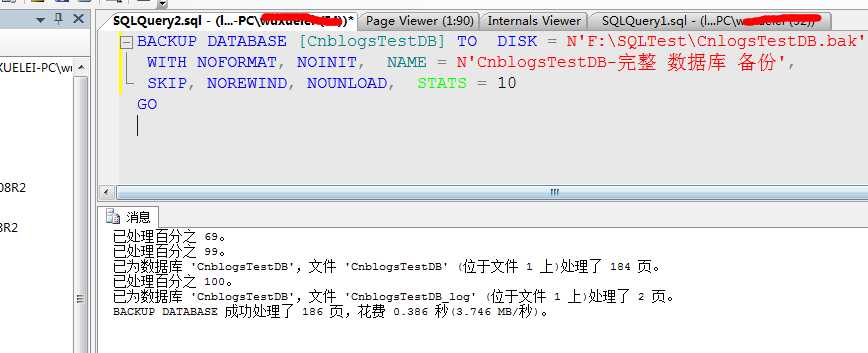
然后修改该数据页信息,这里我使用UltraEdit文本编辑工具,打开文件,找到该数据页内容
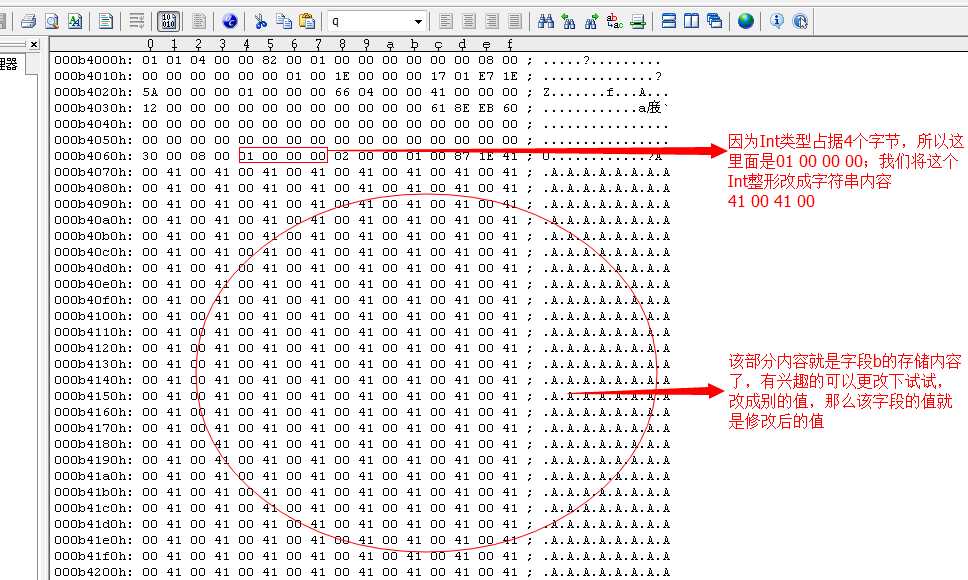
我们将上面的源数据更该一下,来把这个数据页损坏掉
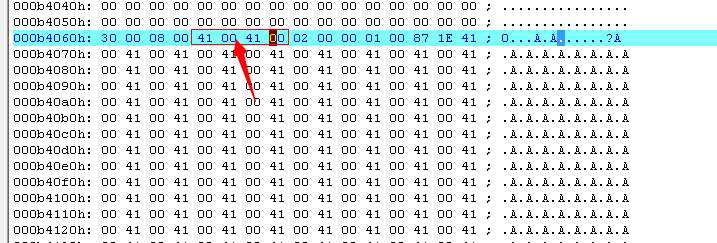
我们保存,然后重新启动该数据库看看
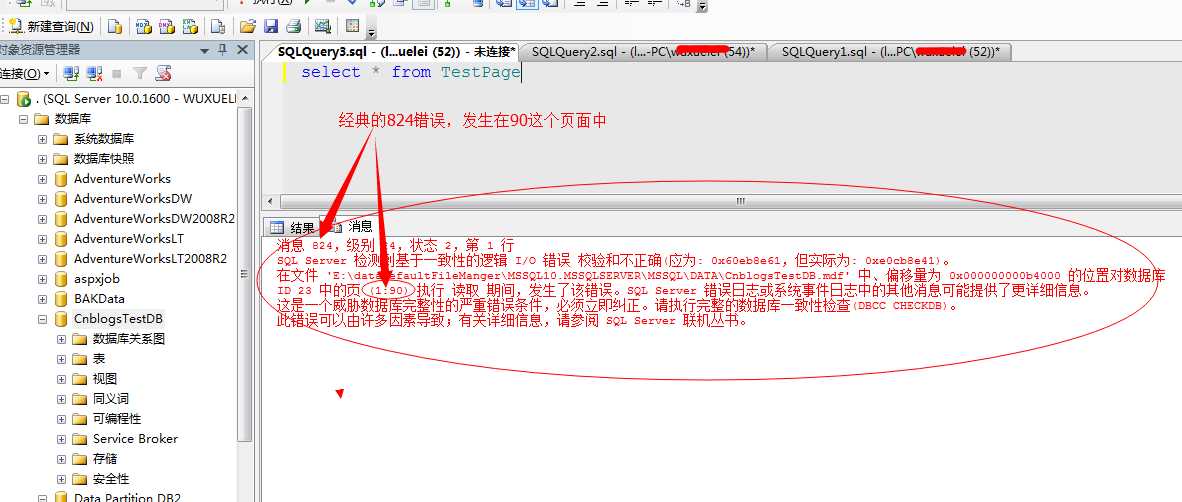
这就是我们平常比较常见的824错误的过程,而此过程有可能是磁盘坏道造成,或者误修改文件等诸多原因,但是此问题还是比较常见的
当然,这种数据页面的损坏可能造成的影响不是库级别的,也就说不会造成数据库不能访问,其它表是能正常访问的,但是只是在操作此损坏的数据页的时候才会报错,但有时候这几个数据页的损坏对业务产生的影响有可能就是致命的,所以我们要解决掉。
郑重提示:上面过程也可以正确的更改数据页中的数据,但是如果没有确切的把握,基本上能把数据库搞瘫痪掉,我是为了重现问题才修改底层元数据,所以在自己的生产库中千万不要乱搞!
在数据库启动的过程中,会发生一致性校验,所以该错误应该会记录到Error的错误日志文件中,我们来看:

windows平台下的错误日志:
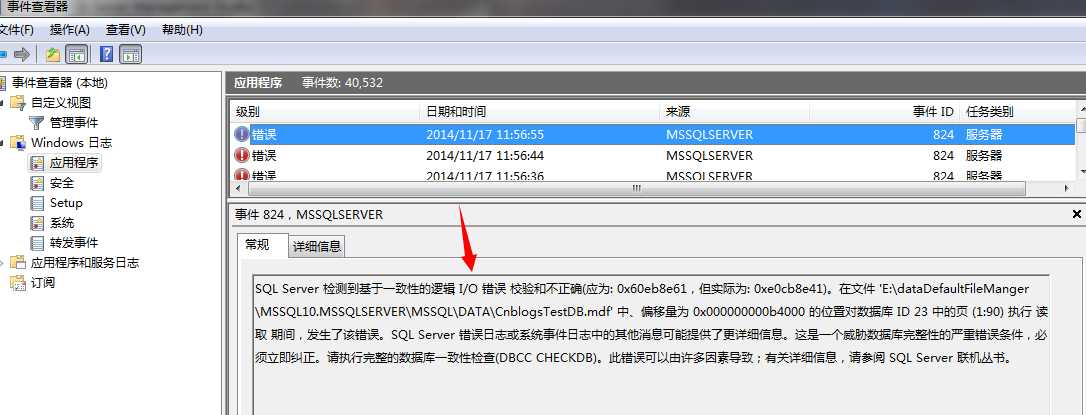
当然,在启动的过程中该问题有可能发生很多,比如磁盘坏道等原因,一系列的数据页可能就没法访问了。所以SQL Server会将这些损坏的页面记录到msdb系统库中,这我们在这个库中查找到损坏的页面集合:
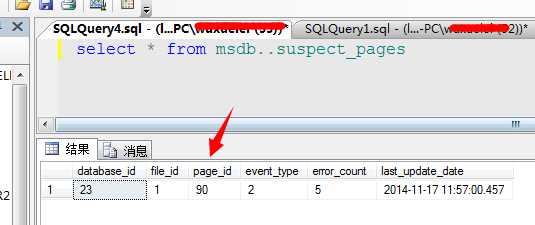
至此,我们已经重现了经典的824错误,那我们该如何解决此问题呢?
解决方法:
a、如果此问题出现的页面为数据承载页,也就说该页存储的为内容数据或者为聚集索引的叶子节点数据,并且存在镜像,版本在SQL Server2005以上,那么这个错误基本可以忽略,SQL Server能够自动帮你修复此错误。
b、如果此问题出现在没有镜像的环境中,那就要区分是损坏页面是否为聚集索引叶子节点数据,如果是,那就简单了,直接重建索引就好了,如果不是,那此种方案还是不能解决,判断方法如下:
利用DBCC PAGE命令查看当前数据页内容,根据ObjectId跟踪该页位于哪个对象上,Metdata:IndexID的值判断是否为索引树中的节点值,如果大于0则表示为索引值,此时,重建该索引既可以。比如:
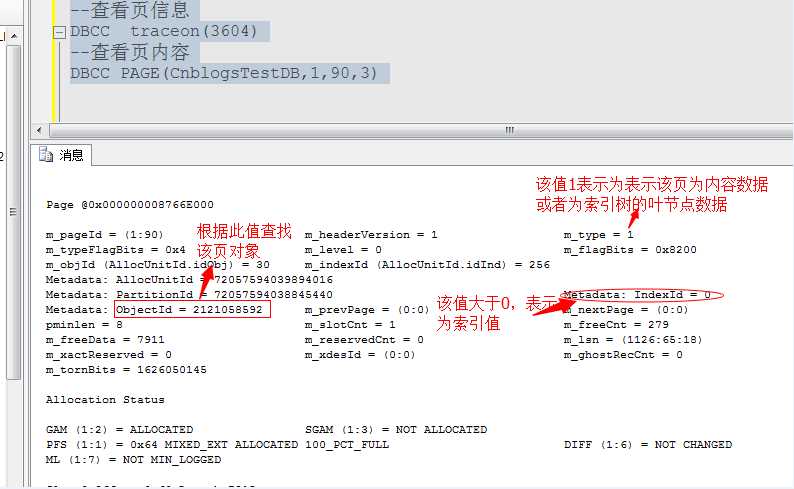
我们根据该页的ObjectID,从数据库中查找该页所属对象。
c、如果上述方案都不能满足,那只有采取此种方案,我们可以利用数据库备份进行还原,当然为了最大限度的避免数据库离线,我们最好采取数据页还原的方式,此种方式最为简单,还原速度也最快,能够最大限度的缩短数据库离线时间,并且保证数据完整性。
这里提示下:在SQL Server2012版本一下,SSMS不提供图像化数据页还原方式,在SQL Sever以后的版本中,有图像化界面操作。
所以,我们只能通过如下脚本进行还原:
RESTORE DATABASE CnblogsTestDB PAGE=‘1:90‘ FROM DISK = N‘F:\SQLTest\CnlogsTestDB.bak‘ WITH NORECOVERY
当然有事务日志、更新备份的,需要依次恢复这过程的所有的备份,不要忘记备份尾部日志。
但是此方法也有局限性:
如果损坏的数据页为
1、分配页:GAM、SGAM和PFS页
2、所有数据文件的启动页
如果发生损坏的是以上两种,则无法通过该备份恢复页方式进行恢复。如果这种情况下,建议考虑找合适的时间段进行全库的恢复操作。(推荐)
d、上述情况是在存在有备份的情况下,如果没有数据库备份,那我们只能选择最后的一招了,那就是DBCC CHECKDB命令,同样和上面一样,此种方式可能会造成数据丢失,所以不建议采用,如果能容忍数据丢失,采用的过程参照文中的上半部分。(不推荐)
至此,我们已经完成了一个SQL Server启动过程或者平常最经常遇到的一个经典错误824错误,我们来总结下:
824错误原因:大部分是由于磁盘存储导致的数据页损坏,导致的SQL Server在读取的时候发生了错误。
导致错误场景:磁盘坏道、突然断电等情况下经常会出现此错误。
----------------------------------------------------------霸气的分割线-----------------------------------------------------------------------
和824错误相关的还有一种是823错误,我们来介绍下该错误信息
由于场景所限,我就不重现该错误了,在这里我详细的介绍下这两种错误的原因和原理,就可以了,如果遇到了,解决的方式基本都是一致的,可参照上面的824错误解决方法。
SQL Server在每次写入页面的时候,会根据页面里的数据算出一个校验值,一同存储到页面中去。当下次读取页面的时候,再根据这次读到的页面数据,算出一个新的校验值。如果写入和读出的数据一模一样,那么两个校验值就是相等的。如果两个校验值不相等,就意味着上次SQL Server写入的数据和这次读取出来的一定不同,现在读取出来的数据就有问题了。
823错误就代表着SQL Server在向操作系统申请某个页面读写的时候遇到了Windows读取或写入请求失败。所以该问题的原因大部分是源自于操作系统层面,更确切的说是物理文件损坏而导致此错误,比如设备驱动程序导致等。
824错误则是在读取数据页面时候,发现数据页面有问题,比如读取出来的校验值不对等。
当上面描述的823和824错误出现大面积的时候,或者直接部分数据文件完全坏掉的情况下,在SQL Server启动过程中就会出现数据库SUSPECT“质疑”状态。
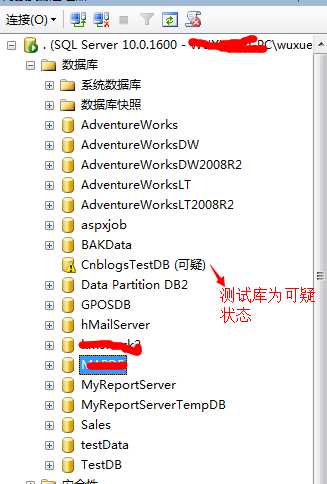
经过我的多次数据页的破坏和摧残,我已经顺利的将我们的这个测试库给搞成了质疑状态,我们来看SUSPECT(质疑)的状态库:
这里我直接DBCC CHECKDB命令尝试着恢复下看看
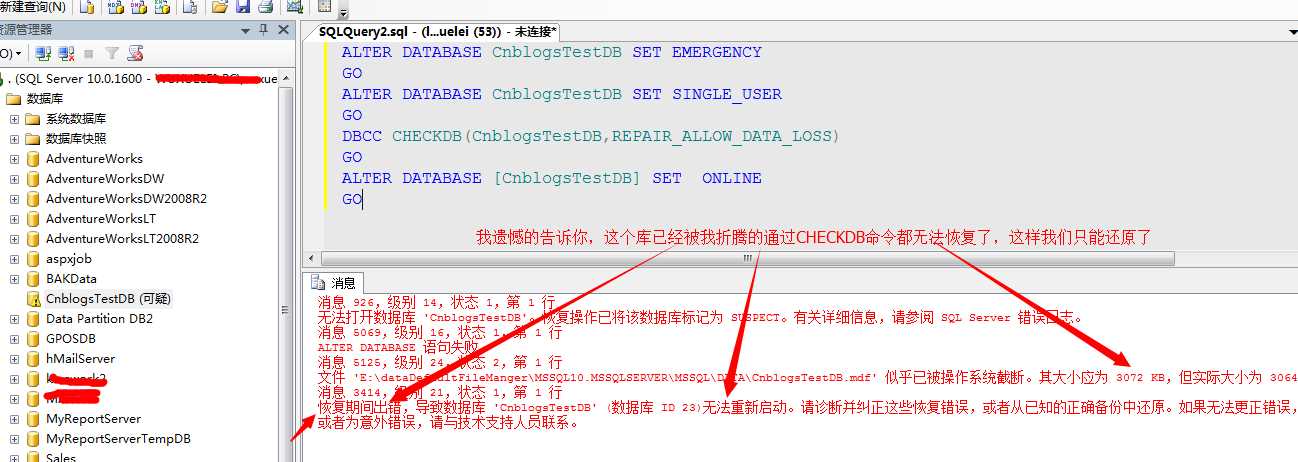
所以到此,我们要做的就是避免上述错误的发生。如果在生产库中发生了我上面的情况,然后没有数据库备份,那么剩下来你要做的事情:我估计就是准备简历了.....
结语
本篇文章到此结束了......文章主要还是分析SQL Server启动过程中,加载用户数据库的时候,所遇到的一系列问题,文中部分内容需要有一定数据库基础知识才能读懂,篇幅有限,我们没有做深入的讲解分析,比如上面的几个重要的命令DBCC PAGE....DBCC CHECKDB..等等,随便一个都能写出一系列的内容,我们侧重的还是问题的解决,和问题原因分析,后续文章中会介绍这一系列的命令作用,以及正确的使用技巧。
....此篇耗时四天完成....文中部分数据库错误都是我耗费精力一步一步调整出来,目的是真实的展现错误明细,其实问题解决容易,问题重现的过程复杂。
如果经常使用SQL Server,其实这些问题都是我们会经常遇到的,所以我们要记住相应的解决方案,做的有备无患!
当然个人能力有限,部分不当之处,还望指出不吝赐教。
转:https://www.cnblogs.com/zhijianliutang/p/4100103.html
SQL Server 数据库启动过程(用户数据库加载过程的疑难杂症)
标签:文件拷贝 很多 表示 描述 -- inf mdf 节点 img
原文地址:https://www.cnblogs.com/VicLiu/p/11653120.html