标签:优点 阶段 应用程序 img 端口 展现 ESS 系统 理解
Kubernetes是Google开源的一个容器编排引擎,它支持自动化部署、大规模可伸缩、应用容器化管理。伴随着云原生技术的迅速崛起,如今Kubernetes 事实上已经成为应用容器化平台的标准,越来越受到企业的青睐,在生产中也应用的也越来越广泛。
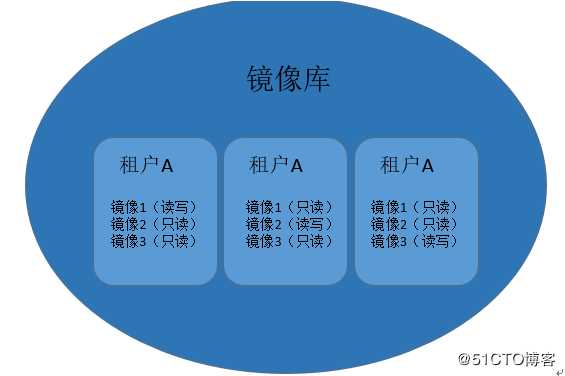
对于跨地域多数据中心的镜像管理,镜像库的远程复制管理需要注意:
1、在多数据中心或跨地域多站点的环境下,为了提高多地区镜像的下载效率,至少需要两级镜像库的设置:总镜像库和子镜像库
2、镜像库之间的准实时增量同步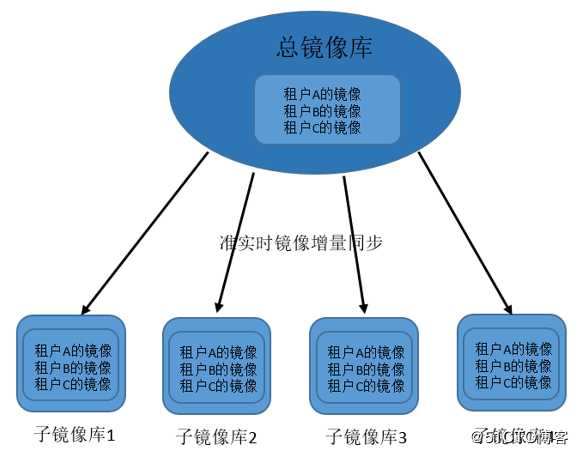
三、 Kubernetes集群管理
在生产系统中,kubernetes多集群的管理主要涉及:
1、服务运维
2、集中配置
3、扩容升级
4、资源配额
首先说说多集群的调度管理
1、Kubernetes中的调度策略可以大致分为两种,一种是全局的调度策略,另一种是运行时调度策略
2、NODE的隔离与恢复;NODE的扩容;Pod动态扩容和缩放
3、亲和性可以实现就近部署,增强网络能力实现通信上的就近路由,减少网络的损耗。反亲和性主要是出于高可靠性考虑,尽量分散实例。
4、 微服务依赖,定义启动顺序
5、跨部门应用不混部
6、api网关以及GPU节点应用独占
多集群管理中的应用弹性伸缩管理:
1、手工扩缩容:预先知道业务量的变化情况
2、基于CPU使用率的自动扩缩容:v1.1版引入控制器HPA,POD必须设置CPU资源使用率请求
3、基于自定义业务指标的自动扩缩容:v1.7版对HPA重新设计,增加了组件,被称为HPA v2
在实际应用中,HPA还有很多不完善的地方,很多厂商都用自己的监控体系来实现对业务指标的监控并实现自动扩容
Kubernetes多集群的调优:
主要有三个难点:
第一是如何分配资源,当用户选择多集群部署后,系统根据每个集群的资源用量,决定每个集群分配的容器数量,并且保证每个集群至少有一个容器。集群自动伸缩时,也会按照此比例创建和回收容器。
第二是故障迁移,集群控制器主要是为了解决多集群的自动伸缩和集群故障时的容器迁移,控制器定时检测集群的多个节点,如果多次失败后将触发集群容器迁移的操作,保障服务可靠运行。
第三是网络和存储的互连,由于跨机房的网络需要互连,我们采用vxlan的网络方案实现,存储也是通过专线互连。容器的镜像仓库采用Harbor,多集群之间设置同步策略,并且在每个集群都设置各自的域名解析,分别解析到不同的镜像仓库。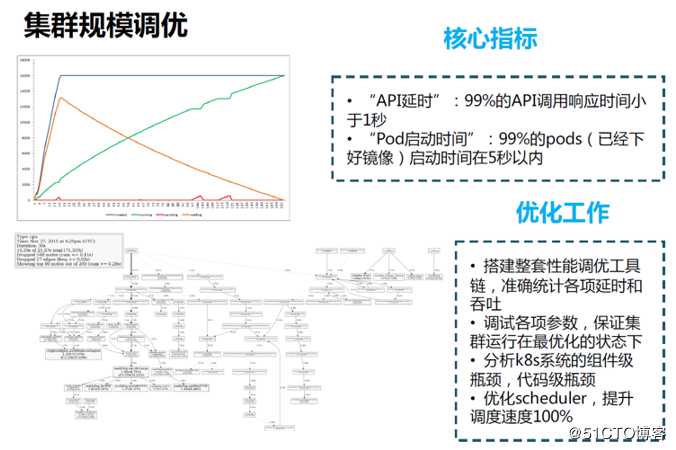
接下来说说K8S集群的Master节点高可用实现,我们知道Kubernetes集群的核心是其master node,但目前默认情况下master node只有一个,一旦master node出现问题,Kubernetes集群将陷入“瘫痪”,对集群的管理、Pod的调度等均将无法实施。所以后面出现了一主多从的架构,包括master node、etcd等都可设计高可用的架构。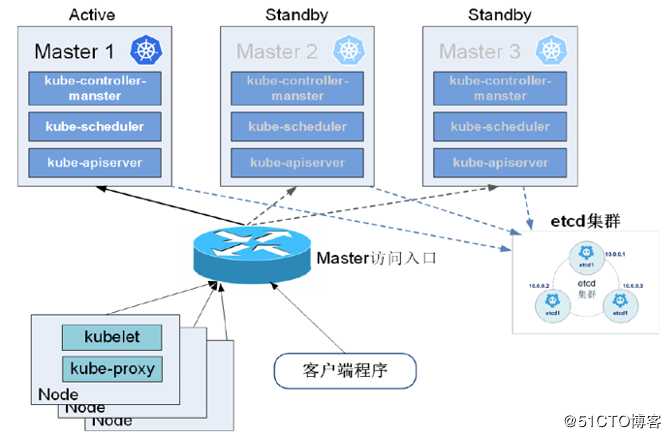
还有了解下Federation 集群联邦架构
在云计算环境中,服务的作用距离范围从近到远一般可以有:同主机(Host,Node)、跨主机同可用区(Available Zone)、跨可用区同地区(Region)、跨地区同服务商(Cloud Service Provider)、跨云平台。K8s的设计定位是单一集群在同一个地域内,因为同一个地区的网络性能才能满足K8s的调度和计算存储连接要求。而集群联邦(Federation)就是为提供跨Region跨服务商K8s集群服务而设计的,实现业务高可用。
Federation 在1.3版引入,集群联邦federation/v1beta1 API扩展基于DNS服务发现的功能。利用DNS,让POD可以跨集群、透明的解析服务。
1.6版支持级联删除联邦资源,1.8版宣称支持5000节点集群,集群联邦V2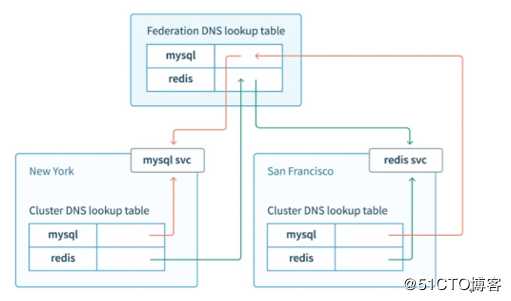
目前存在的问题:
1、网络带宽和成本的增加
2、削弱了多集群之间的隔离性
3、成熟度不足,在生产中还没有正式的应用
四、kubernetes的监控与运维
对于一个监控系统而言,常见的监控维度包括:资源监控和应用监控。资源监控是指节点、应用的资源使用情况,在容器场景中就延伸为节点的资源利用率、集群的资源利用率、Pod的资源利用率等。应用监控指的是应用内部指标的监控,例如我们会将应用在线人数进行实时统计,并通过端口进行暴露来实现应用业务级别的监控与告警。那么在Kubernetes中,监控对象会细化为哪些实体呢?
系统组件
kubernetes集群中内置的组件,包括apiserver、controller-manager、etcd等等。
静态资源实体
主要指节点的资源状态、内核事件等等
动态资源实体
主要指Kubernetes中抽象工作负载的实体,例如Deployment、DaemonSet、Pod等等。
自定义应用
主要指需要应用内部需要定制化的监控数据以及监控指标。
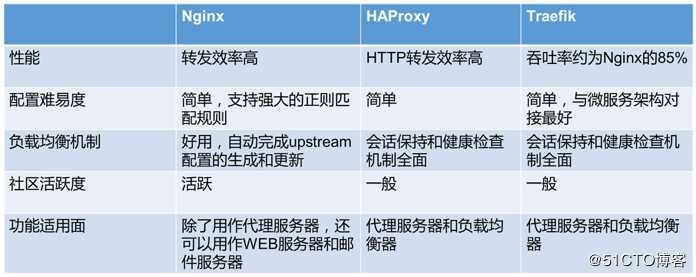
不同容器云监控方案的对比: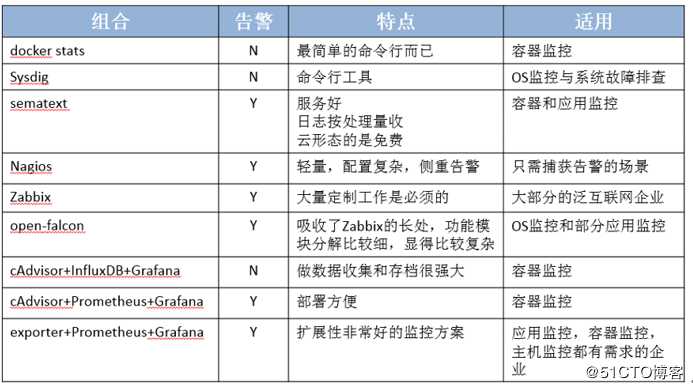
关于Prometheus监控:
主要注意两点:
? 查询api的封装
? 配置文件的下发
有了prometheus这个强大的监控开源系统之后,我们所需要投入的工作就是查询api的封装和配置文件的下发。查询api的封装没什么好说的,无非就是前端调用我们自己的server,我们的server呢通过http协议去调用prometheus的api接口查询到原始数据,然后进行组装,最后返回给前端。 配置文件的话包含三部分吧,警报的定义,alertmanager的配置,以及prometheus的配置,这里也不好展开讲,有兴趣的可以去官网看看。当然也可以使用Prometheus+Grafana来搭建监控系统,这样可视化会更丰富些,展现也比较快。
运维的思考---开发与运维的一体化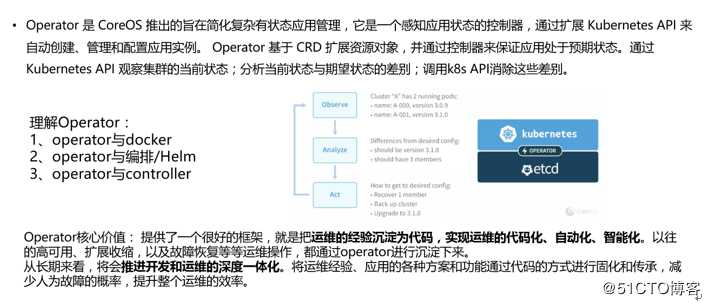
运维的思考---高可用问题
? Ocp平台:
1、负载均衡Router高可用集群: 2个节点
2、EFK高可用集群: 3个ES节点+n个F节点
3、镜像仓库高可用集群: 2个镜像仓库
? 微服务架构:
1、注册中心高可用集群(Eureka): 3个
2、配置中心高可用集群: 3个
3、网关高可用集群: 2个
4、关键微服务均是高可用集群
运维的思考---高并发问题
? Ocp平台:
1、对后端微服务(Pod)配置弹性扩容, K8的弹性伸缩扩容以及Docker容器的秒级启动可以支撑用户量的持续增长;
2、提前预留20%的资源, 当高并发情况发生时, 可以紧急扩充资源。
? 微服务架构:
标签:优点 阶段 应用程序 img 端口 展现 ESS 系统 理解
原文地址:https://blog.51cto.com/xjsunjie/2441526