标签:not 两种 ext 特定 ima 长度 运行时 开始 应该
冒泡排序是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。在一般面试中也是最容易碰到的排序算法。
参考代码如下
pojo类
1 public class pojo { 2 public int[] s; 3 public pojo(){} 4 //产生n个随机整数 5 public pojo(int n){ 6 s=new int[n]; 7 for(int i=0;i<n;i++) 8 s[i]=new Random().nextInt(n); 9 } 10 //产生n个有序整数,falg为true为顺序,false为逆序 11 public pojo(int n,boolean falg){ 12 s=new int[n]; 13 if(falg){ 14 for(int i=0;i<n;i++) 15 s[i]=i; 16 }else{ 17 for(int i=0;i<n;i++) 18 s[i]=n-i; 19 } 20 } 21 //返回前n个数总和 22 public long average(int n){ 23 long sum=0; 24 for(int i=0;i<n;i++) 25 sum+=s[i]; 26 return sum; 27 } 28 }
maopao类
1 public class maopao { 2 public static void sort(int[] s){ 3 for(int i=0;i<s.length;i++){ 4 for(int j=0;j<s.length-1-i;j++){ 5 if(s[j]>s[j+1]){ 6 s[j]=s[j]+s[j+1]; 7 s[j+1]=s[j]-s[j+1]; 8 s[j]=s[j]-s[j+1]; 9 } 10 } 11 } 12 } 13 public static void main(String[] args) { 14 pojo a=new pojo(10000); 15 int []s=a.s; 16 System.out.println(Arrays.toString(s)); 17 long startTime=System.nanoTime(); //获取开始时间 18 sort(s); 19 long endTime=System.nanoTime(); //获取结束时间 20 System.out.println(Arrays.toString(s)); 21 System.out.println("冒泡排序程序运行时间:"+(endTime-startTime)+"ns"+"\t"+"数组长度为:"+s.length); 22 } 23 }
运行结果
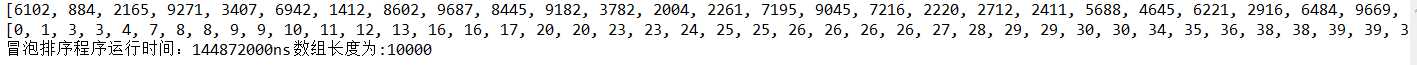
注意代码中"s[j]=s[j]+s[j+1];s[j+1]=s[j]-s[j+1];s[j]=s[j]-s[j+1];",这段代码意思为s[j]与s[j+1]的值交换
思考一下,当需要排序的数据是排好的或者接近排好的,这样的话在循环结束前就已经排好了,但是排序还是会循环判断下去,这样会多做不少无用功,那有什么办法让循环停止呢?
我们发现在一次冒泡循环中,如果当前元素与下一个元素不用交换、下一个元素与下下个元素不用交换、下下个元素...那么当前元素一直到最后一个元素一定是排好的,而循环遍历到当前元素时,第一个元素到当前元素已经是排好的了,所有整体就第一个元素到最后一个元素都排好了,可以直接结束了。
参考代码如下
1 public class maopao1 { 2 public static void sort(int[] s){ 3 for(int i=0;i<s.length;i++){ 4 boolean flag=false; 5 for(int j=0;j<s.length-1-i;j++){ 6 if(s[j]>s[j+1]){ 7 s[j]=s[j]+s[j+1]; 8 s[j+1]=s[j]-s[j+1]; 9 s[j]=s[j]-s[j+1]; 10 flag=true; 11 } 12 } 13 if(!flag) 14 break; 15 } 16 } 17 public static void main(String[] args) { 18 pojo a=new pojo(10000); 19 int []s=a.s; 20 System.out.println(Arrays.toString(s)); 21 long startTime=System.nanoTime(); //获取开始时间 22 sort(s); 23 long endTime=System.nanoTime(); //获取结束时间 24 System.out.println(Arrays.toString(s)); 25 System.out.println("优化冒泡排序程序运行时间:"+(endTime-startTime)+"ns"+"\t"+"数组长度为:"+s.length); 26 } 27 }
运行结果
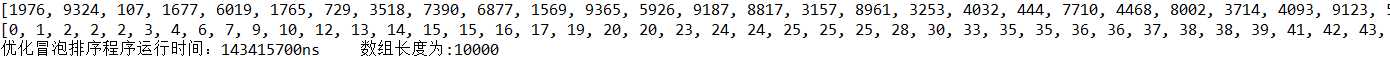
我在这里增加了一个flag变量来做标记,当满足条件后直接跳出循环。
发现没有,运行时间上基本没什么变化,但是注意我上面说了,当需要排序的数据是排好的或者接近排好的,优化效果就非常明显了。
改变上面maopao1类的代码
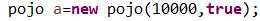
这个表示获取从小到大的1-10000排列的数组,我们的目标也是从小打大排序。
结果如下
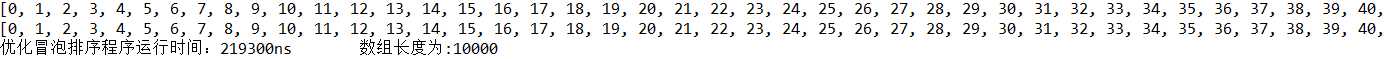
我在这里讲一种新的排序,它叫鸡尾酒排序,或者叫快乐小时排序,当然它不止这两种叫法。他是冒泡排序的一种变形,是基于冒泡排序的。
他的原理是:先找到最小的数字,把他放到第一位,然后找到最大的数字放到最后一位。然后再找到第二小的数字放到第二位,再找到第二大的数字放到倒数第二位。以此类推,直到完成排序。也就是双向的冒泡。
参考代码如下
1 public class maopao2 { 2 public static void sort(int[] s){ 3 int left=0,right=s.length-1; 4 while(left<right){ 5 //同优化冒泡排序 6 boolean flag=false; 7 //从右向左冒泡,找最小的 8 for(int i=right;i>left;i--) 9 if(s[i]<s[i-1]){ 10 s[i]=s[i]+s[i-1]; 11 s[i-1]=s[i]-s[i-1]; 12 s[i]=s[i]-s[i-1]; 13 flag=true; 14 } 15 left++; 16 //从左向右冒泡,找最大的 17 for(int i=left;i<right;i++) 18 if(s[i]>s[i+1]){ 19 s[i]=s[i]+s[i+1]; 20 s[i+1]=s[i]-s[i+1]; 21 s[i]=s[i]-s[i+1]; 22 flag=true; 23 } 24 right--; 25 if(!flag) 26 break; 27 } 28 } 29 public static void main(String[] args) { 30 pojo a=new pojo(10000); 31 int []s=a.s; 32 System.out.println(Arrays.toString(s)); 33 long startTime=System.nanoTime(); //获取开始时间 34 sort(s); 35 long endTime=System.nanoTime(); //获取结束时间 36 System.out.println(Arrays.toString(s)); 37 System.out.println("鸡尾酒排序程序运行时间:"+(endTime-startTime)+"ns"+"\t"+"数组长度为:"+s.length); 38 } 39 }
运行结果

虽然运行时间没有多大改变,但是在某些特定的环境下是要优于冒泡排序的。
改变maopao2类代码:
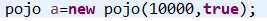
运行结果:

改变maopao2类代码:
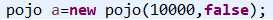
运行结果:

标签:not 两种 ext 特定 ima 长度 运行时 开始 应该
原文地址:https://www.cnblogs.com/chengpu/p/algorithm3.html