标签:net ref 大脑 取反 提前 设计 基于 维度 图像
发表在2017年CVPR。
这篇论文旨在说明:反馈学习比单纯的前向学习更有效,并且给出了一些理由,并予以实验证明。本文通过ConvLSTM予以实现,同时考察了课程学习方法对coarse-to-fine分类原理(同时也是反馈学习框架的优势)的应用。
现在看着蛮平庸的。虽然想法很直接,也很容易想到,但本文的实验充分,有理有据,还是不错的。
对于图像分类问题,我们通常采用前向CNN网络。但作者认为我们还可以采取反馈的方式代替前向模式,有以下几点优势:
可以实现提前判决,这在查询时特别有效。
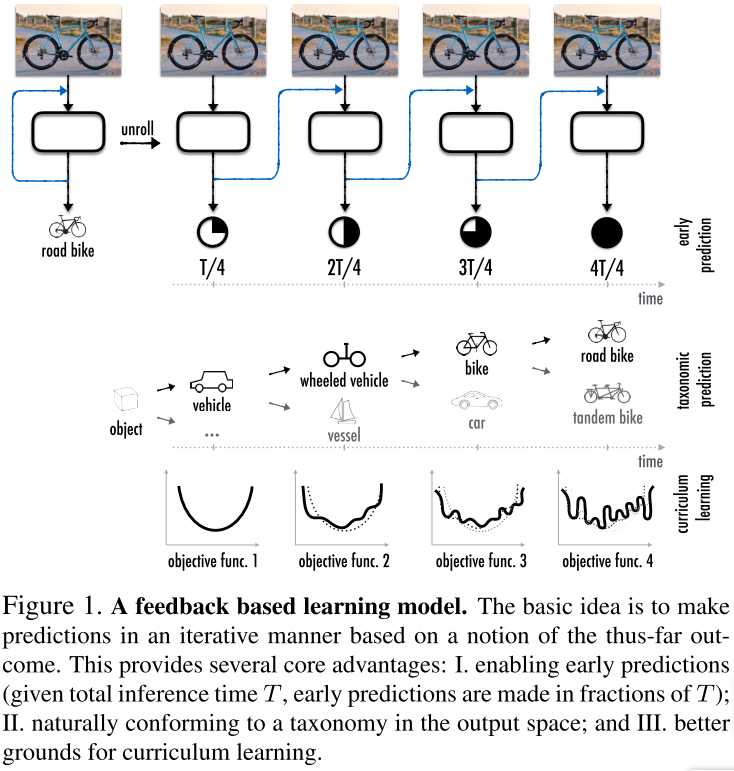
符合标签化的分类原理,从大类到小类(coarse to fine)逐步判断,如图1。
为Curriculum Learning提供了基础。
作者通过ConvLSTM实现了这种思想,其性能超越了前向网络。注意,本文提出的反馈,指的是在隐藏空间中的反馈。这样就不需要针对特定任务,设计误差-输入转换。
反馈是循环因果系统的产物[13] =>
反馈是一种在控制论和物理学中被广泛使用的强大手段[一堆文献]。大脑也是[一堆文献],表明了反馈在视觉中有重要意义 =>
因此,本文就提出了基于反馈的学习方法,相较传统前向方法具有上述优点。
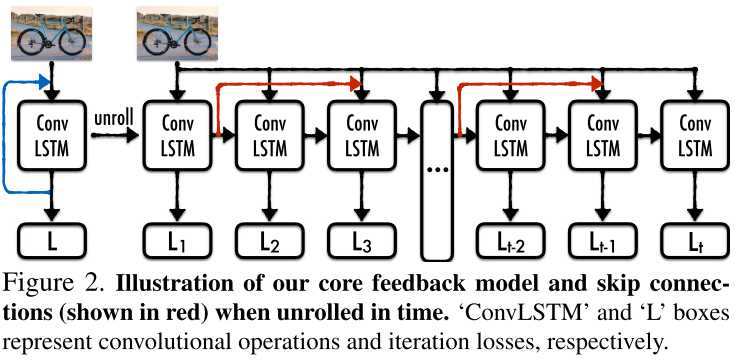
本文中,ConvLSTM单元是权值共享的。其中还有红线代表短连接。
注意,ConvLSTM有两个维度:时间t和深度d。具体gate和推导操作见3.1节。核心:中间层状态同时由当前输入和上一层隐藏层状态决定。3.2节介绍了图2中ConvLSTM单元的具体结构。
进一步,作者还通过短连接,将若干时刻前的隐藏层状态与当前输入求和,得到新的输入。这种短连接是有效的,见表1给出的溶解实验结果。
方法的精髓在于:作者在每一个时间步都计算一次loss。最终的loss是这些loss的加权组合。这样,我们就避免网络成为一个前向推导网络,而是成为一个具有coarse-to-fine特点的推导网络。更进一步,我们还可以结合课程学习的方法,见下一节。
很简单。作者设计了一个动态变化的loss。在训练早期,loss将重点惩罚大类错误,后期再重点惩罚小类错误。就像一个孩子,我们让TA循序渐进地学习,从分大类开始,再到细致分类。
并没有对early exit设置判决方法。相反,作者是让网络完整地进行推导,然后看看在每一层的准确率是多少。
作者将反馈网络与前向网络相比,观察到:反馈网络在相同层级上准确率更高。
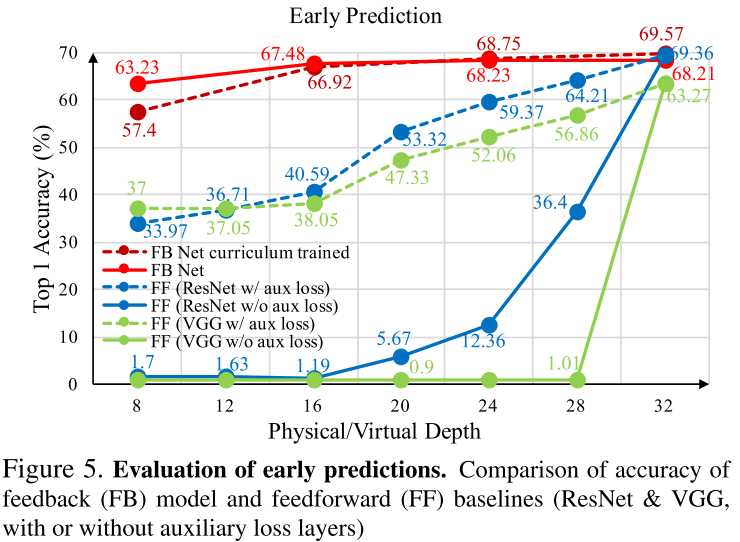
此外还有一个实验:有一些样本在大类是正确的,但小类是错误的。通过增加网络深度,作者看看网络是否能逐渐得到正确的小类。具体见论文。结论是反馈结构更具有这种能力。
标签:net ref 大脑 取反 提前 设计 基于 维度 图像
原文地址:https://www.cnblogs.com/RyanXing/p/11664323.html