标签:str html 详细 tab cup 能力 白名单 用户 分配
一个新的推荐算法最终上线,需要完成上面所说的3个实验:
(1)首先,需要通过离线实验证明它在很多离线指标上优于现有的算法;
(2)然后,需要通过用户调查(或内部人工评测)确定它的用户满意度不低于现有的算法;
(3)最后,通过在线等AB测试确定它在我们关心的指标上优于现有的算法。
(1)AB test 的好处是显而易见的,可以公平获得不同算法实际在线时的性能指标;
(2)AB test 和用户调查一样,同样需要考虑到分布的随机,尽量要将与最终指标有相关性的因素都列出来,总而言之就是切分流量是AB test 的关键;
(3)AB test 的一个重要缺点就是实验周期长,这样才能得到可靠的结果,因此AB test 不应该测试所有的算法,而是只测试在离线实验和用户调查中表现很好的算法;
(4)如果有用户标签库的话,会极大的帮助在线实验。
| 功能 | 描述 |
|---|---|
| 分流 | 支持召回排序等指定方式分流,比如尾号哈希,或分层哈希 |
| 白名单 | 实验开始前预置一些用户白名单到实验组 |
| 实验管理 | 支持实验创建,实验列表,实验修改等 |
| 指标管理 | 指标计算定义 |
| 效果图表 | diff,AAdiff;以及对应图表 |
| 可信度分析 | 根据实验组的置信区间(95%置信区间)和p值(当p值小于等于0.05时,实验结果是显著的)判定实验是否可信 |
这里对应到推荐的指标集一般包括点击率(ctr),关注率,观看时长,MAU/DAU等;
而线下一般采用(特征/召回)覆盖率,AUC,gAUC,相关性&准确率(人工评测)等指标;
其中特征覆盖率\(coverage = \frac{N_1}{N} ; 其中N_1是特征i中非空个数,N是总样本数; 对应到召回覆盖率,N_1是有召回结果的用户数(或召回的内容数),N是总用户数(或可推荐的内容数)\)
不得不提的是在项亮的《推荐系统实践》中推荐系统的覆盖率是度量一个推荐系统挖掘长尾商品的能力(曝光内容分散程度,越集中头部效应/马太效应越严重):
\[ Coverage = \frac{|\cup_{u \in U} R(u)|}{|I|} ;其中U是用户集合,I是物品集合,R(u)是为用户u推荐的N个物品的集合\]
在度量推荐系统覆盖率更科学的一个指标是基尼系数(Gini Index),因为其考虑了每个物品被推荐次数是否平均,系数越大,表示越不均等,系数越小,表示越均等。gini系数最开始是被用来量度贫富悬殊程度,具体推导见附录洛伦茨曲线和基尼系数:
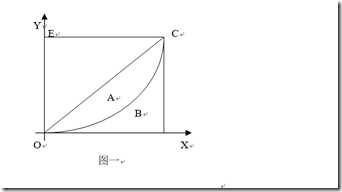
1905年,统计学家洛伦茨提出了洛伦茨曲线,如图一。将社会总人口按收入由低到高的顺序平均分为10个等级组,每个等级组均占10%的人口,再计算每个组的收入占总收入的比重。然后以人口累计百分比为横轴,以收入累计百分比为纵轴,绘出一条反映居民收入分配差距状况的曲线,即为洛伦茨曲线。
\[ Gini = \frac{1}{n-1} \sum^n_{j=1} (2j-n-1)p(j) ;其中p(j)是从小到大排序的物品列表中第j个物品被推荐的比例,也即p(j)=\frac{物品j被推荐次数}{\sum^n_{j=1}物品j被推荐次数} \]
AUC(Area under curve)是机器学习常用的二分类评测手段,直接含义是ROC曲线下的面积;进一步说其实就是随机抽出一对样本(一个正样本,一个负样本),然后用训练得到的分类器来对这两个样本进行预测,预测得到正样本的概率大于负样本概率的概率。
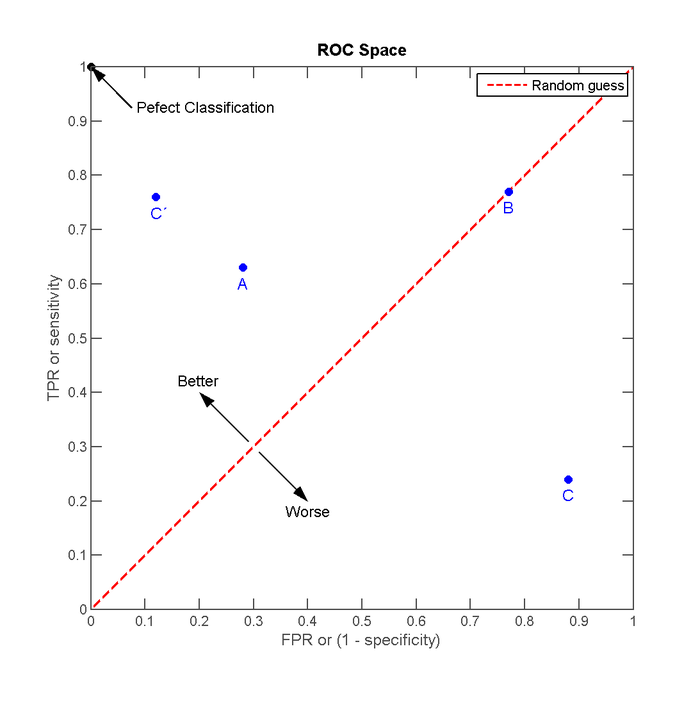
ROC曲线的横轴为假正率(False Positive Rate,FPR);纵轴为“真正率”(True Positive Rate,TPR)
\[ TPR = \frac{fp}{p} ; FPR = \frac{tp}{n} ; fp是实际为负预测为正的样本个数;tp是实际为正预测也为正的个数;n是真实负样本总数;p是真实正样本总数 \]
\[ AUC = \frac{ \sum_{i \in postitiveClass} rank_i - \frac{M(1+M)}{2}}{M+N} ;其中rank_i实代表了样本i预测概率超过的样本的数目(最高的概率的rank为n,第二高的为n-1);M是正样本个数,N是负样本个数\]
AUC反映的是整体样本间的一个排序能力,而实际用户的结果是个性化的,我们更关注的是同一个用户对不同物品间的排序能力,gAUC(group auc)实际是计算每个用户的auc,然后加权平均,最后得到group auc,这样就能减少不同用户间的排序结果不太好比较这一影响。
\[ gAUC = \frac{\sum_{(u,p)} w_{(u,p)} * AUC_{(u,p)}}{\sum_{(u,p)} w_{(u,p)}} \]
实际处理时权重一般可以设为每个用户view的次数,或click的次数,而且一般计算时,会过滤掉单个用户全是正样本或负样本的情况。
但是实际上一般还是主要看auc这个指标,但是当发现auc不能很好的反映模型的好坏(比如auc增加了很多,实际效果却变差了),这时候可以看一下gauc这个指标。
这方面一般由数据平台的产品进行支持,简单的也可以自己写SQL跑数据;在此就不详细展开了。
这方面一般依托监控报警平台和数据平台;业务方也可以自己写脚本监控;在此就不详细展开了。
数据指标和真实的用户体验存在差异,Bad case的反馈是优化推荐系统的一大途径
标签:str html 详细 tab cup 能力 白名单 用户 分配
原文地址:https://www.cnblogs.com/arachis/p/REC_DEV_data_index.html