标签:sqrt undle bundle 问题: 时间差 feed 集合 use output
目录
环境(Environment):可以分为完全可观测环境(Fully Observable Environment)和部分可观测环境(Partially Observable Environment)。
1)Fully Observable Environment就是agent了解了整个环境,显然是一个理想情况。
2)Partially Observable Environment是agent了解部分环境的情况(E&E的利用部分),剩下的需要靠agent去探索。
奖励(Reward/Return,R):执行该动作所接受的瞬时奖赏\(r_{t+1}\);折扣未来奖励(Discounted Future Reward)是执行该动作将来可能带来的奖励;
\[ R_t = \sum^T_{i=t} \gamma^{(i-t)} r(s_i,a_i) \]
即当前时刻的奖励等于当前时刻的即时奖励加上下一时刻的奖励乘上折扣因子γ。
如果γ等于0,意味着只看当前奖励;
如果γ等于1,意味着环境是确定的,相同的动作总会获得相同的奖励(也就是cyclic Markov processes)。
因此实际中γ往往取类似0.9这样的值
状态转移概率矩阵(Transition):状态转移概率矩阵会根据agent当前的动作给出所有可能的下一个棋盘状态以及对应的概率;
策略(Policy):Policy就是我们的算法追求的目标,可以看做一个函数,在输入state的时候,能够返回此时应该执行的action或者action的概率分布。
\[ \pi(a \mid s) = P[A_t = a \mid S_t = s] \]
1.1)确定性策略(Deterministic policy):指在某特定状态下执行某个特定动作,即$ \pi(s) = a $
1.2)随机性策略(Stochastic policy):根据概率来执行某个动作,即$ \pi(s,a_i) = p_i $;也称为greedy policy
2.1)行为策略(Behavior Policy):用来与环境互动产生数据的策略,即在训练过程中做决策
2.2)目标策略(Target Policy):学习训练完毕后拿去应用的策略
2.3)离线策略(off-policy):目标策略和行为策略分开,基本思想是利用Importance Sampling,即使用行为策略估计目标策略
2.4)在线策略(online-policy):目标策略和行为策略是同一个策略,即直接学习目标策略。
Value(价值函数):表示在输入state,action的时候能得到的Discounted future reward的(期望)值。
Value function一般有两种。
1)state-value function:\(V_{\pi}(s) = E_{\pi} [R_t \mid S_t = s]\)
2)action-value function:\(Q_{\pi}(s; a) = E_{\pi} [R_t \mid S_t = s; A_t = a]\)
Bellman方程:当前状态的价值和下一步的价值以及当前的反馈Reward有关, Bellman方程透出的含义就是价值函数的计算可以通过迭代的方式来实现。
\[ V(s) = \mathbb E[R_{t+1} + \gamma V(S_{t+1})|S_t = s] \]
\[ Q(s,a) = \mathbb E[R_{t+1} + \gamma V(S_{t+1},A_{t+1})|S_t = s,A_t = a] \]
强化学习分类
Value-based RL,值方法。显式地构造一个model来表示值函数Q,找到最优策略对应的Q函数,自然就找到了最优策略。
Policy-based RL,策略方法。显式地构造一个model来表示策略函数,然后去寻找能最大化discounted future reward的策略。
Model-based RL,基于环境模型的方法。先得到关于environment transition的model,然后再根据这个model去寻求最佳的策略。
一个马尔科夫决策过程(Markov Decision Processes,MDP)是对强化学习中环境(Environment)的形式化的描述,或者说是对于agent所处的环境的一个建模。在强化学习中,几乎所有的问题都可以形式化的表示为一个MDP。
| MDP要素 | 符号 | 描述 |
|---|---|---|
| 状态/状态空间 | S | 状态是对环境的描述,在智能体做出动作后,状态会发生变化,且演变具有马尔可夫性质。MDP所有状态的集合是状态空间。状态空间可以是离散或连续的。 |
| 动作/动作空间 | A | 动作是对智能体行为的描述,是智能体决策的结果。MDP所有可能动作的集合是动作空间。动作空间可以是离散或连续的。 |
| 策略 | $ \pi(a|s) $ | MDP的策略是按状态给出的,动作的条件概率分布,在强化学习的语境下属于随机性策略。 |
| 瞬时奖励 | R | 智能体给出动作后环境对智能体的反馈。是当前时刻状态、动作和下个时刻状态的标量函数。 |
| 累计回报 | G | 回报是奖励随时间步的积累,在引入轨迹的概念后,回报也是轨迹上所有奖励的总和。 |
在离散时间上建立的MDP被称为“离散时间马尔可夫决策过程(descrete-time MDP)”,反之则被称为“连续时间马尔可夫决策过程(continuous-time MDP)” [1] 。此外MDP存在一些变体,包括部分可观察马尔可夫决策过程、约束马尔可夫决策过程和模糊马尔可夫决策过程。
策略学习(Policy Learning),可理解为一组很详细的指示,它能告诉代理在每一步该做的动作。我们也可以把这个策略看作是函数,它只有一个输入,即代理当前状态。
策略搜索是将策略进行参数化即 \(\pi_\theta(s)\),利用线性或非线性(如神经网络)对策略进行表示,寻找最优的参数使得强化学习的目标:累积回报的期望\(E[\sum^H_{t=0} R(s_t)|\pi_\theta]\)最大。策略搜索方法中,我们直接对策略进行迭代计算,也就是迭代更新参数值,直到累积回报的期望最大,此时的参数所对应的策略为最优策略。
时间差分方法结合了蒙特卡罗的采样方法(即做试验)和动态规划方法的bootstrapping(利用后继状态的值函数估计当前值函数);数学表示如下:
$ V(S_t) \gets V(S_t) + \alpha \delta_t $
$ \delta_t = [R_{t+1} + \gamma?V(S_{t+1} - V(S_t)] $
$ 这里
\delta_t \text{ 称为TD偏差 } \
\alpha \text{ - 学习步长 learning step size} \
\gamma \text{ - 称为折扣未来奖励 reward discount rate} \
$
另一个指导代理的方式是给定框架后让代理根据当前环境独自做出动作,而不是明确地告诉它在每个状态下该执行的动作。与策略学习不同,Q-Learning算法有两个输入,分别是状态和动作,并为每个状态动作对返回对应值。当你面临选择时,这个算法会计算出该代理采取不同动作时对应的期望值。
Q-Learning的创新点在于,它不仅估计了当前状态下采取行动的短时价值,还能得到采取指定行动后可能带来的潜在未来价值。由于未来奖励会少于当前奖励,因此Q-Learning算法还会使用折扣因子来模拟这个过程。
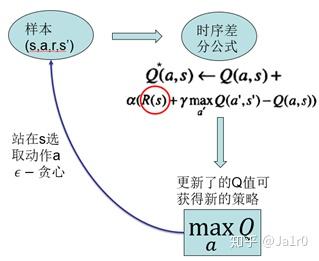

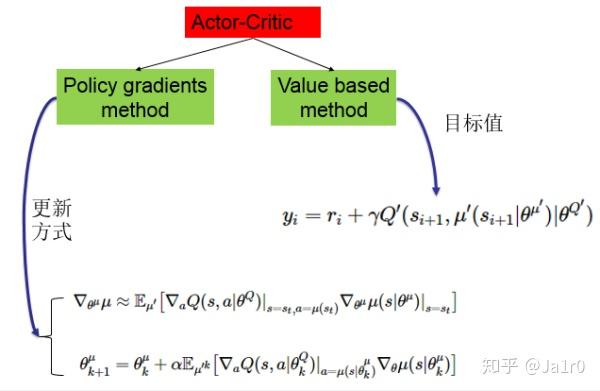
Actor-Critic方法是一种很重要的强化学习算法,其是一种时序差分方法(TD method),结合了基于值函数的方法和基于策略函数的方法。其中策略函数为行动者(Actor),给出动作;价值函数为评价者(Critic),评价行动者给出动作的好坏,并产生时序差分信号,来指导价值函数和策略函数的更新。
Acror-Critic结构如下图:
DQN是基于Q-Learning,用深度神经网络拟合其中的Q值的一种方法。DQN所做的是用一个深度神经网络进行端到端的拟合,发挥深度网络对高维数据输入的处理能力。解决如下两个问题:
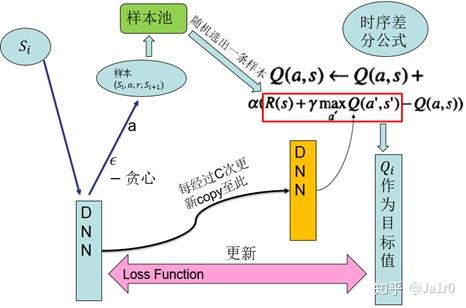
其有两个关键技术:
1、样本池(experience reply/replay buffer):将采集到的样本先放入样本池,然后从样本池中随机选出一条样本用于对网络的训练。这种处理打破了样本间的关联,使样本间相互独立。
2、固定目标值网络(fixed Q-target):计算网络目标值需用到现有的Q值,现用一个更新较慢的网络专门提供此Q值。这提高了训练的稳定性和收敛性。
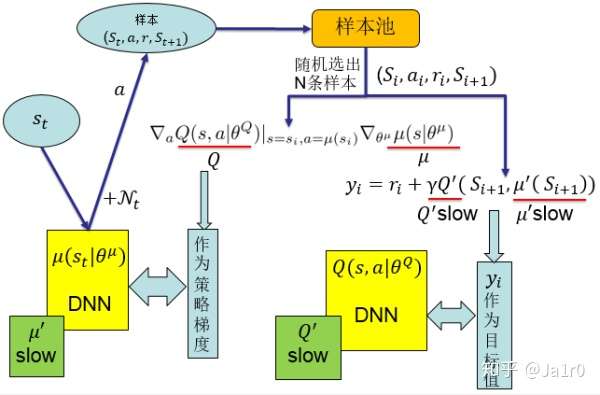
DDPG方法可以应对高维的输入,实现端对端的控制,且可以输出连续动作,使得深度强化学习方法可以应用于较为复杂的有大的动作空间和连续动作空间的情境。DDPG是基于Actor-Critic方法,在动作输出方面采用一个网络来拟合策略函数,直接输出动作,可以应对连续动作的输出及大的动作空间。

该结构包含两个网络,一个策略网络(Actor),一个价值网络(Critic)。策略网络输出动作,价值网络评判动作。两者都有自己的更新信息。策略网络通过梯度计算公式进行更新,而价值网络根据目标值进行更新。
DDPG采用了DQN的成功经验。即采用了样本池和固定目标值网络这两项技术。也就是说这两个网络分别有一个变化较慢的副本,该变化较慢的网络提供给更新信息中需要的一些值。DDPG的整体结构如下:
TF实现DDPG
import numpy as np
from collections import deque
import random
import tensorflow as tf
from math import sqrt
class Agent(object):
def __init__(self, model, replay_buffer, exploration_noise, discout_factor, verbose=False):
self.model = model
self.replay_buffer = replay_buffer
self.exploration_noise = exploration_noise
self.discout_factor = discout_factor
self.verbose = verbose
def predict_action(self, observation):
return self.model.predict_action(observation)
def select_action(self, observation, p=None):
pred_action = self.predict_action(observation)
noise = self.exploration_noise.return_noise()
if p is not None:
return pred_action * p + noise * (1 - p)
else:
return pred_action + noise
def store_transition(self, transition):
self.replay_buffer.store_transition(transition)
def init_process(self):
self.exploration_noise.init_process()
def get_transition_batch(self):
batch = self.replay_buffer.get_batch()
transpose_batch = list(zip(*batch))
s_batch = np.vstack(transpose_batch[0])
a_batch = np.vstack(transpose_batch[1])
r_batch = np.vstack(transpose_batch[2])
next_s_batch = np.vstack(transpose_batch[3])
done_batch = np.vstack(transpose_batch[4])
return s_batch, a_batch, r_batch, next_s_batch, done_batch
def preprocess_batch(self, s_batch, a_batch, r_batch, next_s_batch, done_batch):
target_actor_net_pred_action = self.model.actor.predict_action_target_net(next_s_batch)
target_critic_net_pred_q = self.model.critic.predict_q_target_net(next_s_batch, target_actor_net_pred_action)
y_batch = r_batch + self.discout_factor * target_critic_net_pred_q * (1 - done_batch)
return s_batch, a_batch, y_batch
def train_model(self):
s_batch, a_batch, r_batch, next_s_batch, done_batch = self.get_transition_batch()
self.model.update(*self.preprocess_batch(s_batch, a_batch, r_batch, next_s_batch, done_batch))
class Replay_Buffer(object):
def __init__(self, buffer_size=10e6, batch_size=1):
self.buffer_size = buffer_size
self.batch_size = batch_size
self.memory = deque(maxlen=buffer_size)
def __call__(self):
return self.memory
def store_transition(self, transition):
self.memory.append(transition)
def store_transitions(self, transitions):
self.memory.extend(transitions)
def get_batch(self, batch_size=None):
b_s = batch_size or self.batch_size
cur_men_size = len(self.memory)
if cur_men_size < b_s:
return random.sample(list(self.memory), cur_men_size)
else:
return random.sample(list(self.memory), b_s)
def memory_state(self):
return {"buffer_size": self.buffer_size,
"current_size": len(self.memory),
"full": len(self.memory) == self.buffer_size}
def empty_transition(self):
self.memory.clear()
class DDPG_Actor(object):
def __init__(self, state_dim, action_dim, optimizer=None, learning_rate=0.001, tau=0.001, scope="", sess=None):
self.scope = scope
self.sess = sess
self.state_dim = state_dim
self.action_dim = action_dim
self.learning_rate = learning_rate
self.l2_reg = 0.01
self.optimizer = optimizer or tf.train.AdamOptimizer(self.learning_rate)
self.tau = tau
self.h1_dim = 400
self.h2_dim = 300
# self.h3_dim = 200
self.activation = tf.nn.relu
self.kernel_initializer = tf.contrib.layers.variance_scaling_initializer()
# fan-out uniform initializer which is different from original paper
self.kernel_initializer_1 = tf.random_uniform_initializer(minval=-1 / sqrt(self.h1_dim),
maxval=1 / sqrt(self.h1_dim))
self.kernel_initializer_2 = tf.random_uniform_initializer(minval=-1 / sqrt(self.h2_dim),
maxval=1 / sqrt(self.h2_dim))
self.kernel_initializer_3 = tf.random_uniform_initializer(minval=-3e-3, maxval=3e-3)
self.kernel_regularizer = tf.contrib.layers.l2_regularizer(self.l2_reg)
with tf.name_scope("actor_input"):
self.input_state = tf.placeholder(tf.float32, shape=[None, self.state_dim], name="states")
with tf.name_scope("actor_label"):
self.actions_grad = tf.placeholder(tf.float32, shape=[None, self.action_dim], name="actions_grad")
self.source_var_scope = "ddpg/" + "actor_net"
with tf.variable_scope(self.source_var_scope):
self.action_output = self.__create_actor_network()
self.target_var_scope = "ddpg/" + "actor_target_net"
with tf.variable_scope(self.target_var_scope):
self.target_net_actions_output = self.__create_target_network()
with tf.name_scope("compute_policy_gradients"):
self.__create_loss()
self.train_op_scope = "actor_train_op"
with tf.variable_scope(self.train_op_scope):
self.__create_train_op()
with tf.name_scope("actor_target_update_train_op"):
self.__create_update_target_net_op()
self.__create_get_layer_weight_op_source()
self.__create_get_layer_weight_op_target()
def __create_actor_network(self):
h1 = tf.layers.dense(self.input_state,
units=self.h1_dim,
activation=self.activation,
kernel_initializer=self.kernel_initializer_1,
# kernel_initializer=self.kernel_initializer,
kernel_regularizer=self.kernel_regularizer,
name="hidden_1")
h2 = tf.layers.dense(h1,
units=self.h2_dim,
activation=self.activation,
kernel_initializer=self.kernel_initializer_2,
# kernel_initializer=self.kernel_initializer,
kernel_regularizer=self.kernel_regularizer,
name="hidden_2")
# h3 = tf.layers.dense(h2,
# units=self.h3_dim,
# activation=self.activation,
# kernel_initializer=self.kernel_initializer,
# kernel_regularizer=self.kernel_regularizer,
# name="hidden_3")
action_output = tf.layers.dense(h2,
units=self.action_dim,
activation=tf.nn.tanh,
# activation=tf.nn.tanh,
kernel_initializer=self.kernel_initializer_3,
# kernel_initializer=self.kernel_initializer,
kernel_regularizer=self.kernel_regularizer,
use_bias=False,
name="action_outputs")
return action_output
def __create_target_network(self):
# get source variales and initialize
source_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=self.source_var_scope)
self.sess.run(tf.variables_initializer(source_vars))
# create target network and initialize it by source network
action_output = self.__create_actor_network()
target_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=self.target_var_scope)
target_init_op_list = [target_vars[i].assign(source_vars[i]) for i in range(len(source_vars))]
self.sess.run(target_init_op_list)
return action_output
def __create_loss(self):
source_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=self.source_var_scope)
self.policy_gradient = tf.gradients(self.action_output, source_vars, -self.actions_grad)
self.grads_and_vars = zip(self.policy_gradient, source_vars)
def __create_train_op(self):
self.train_policy_op = self.optimizer.apply_gradients(self.grads_and_vars,
global_step=tf.contrib.framework.get_global_step())
train_op_vars = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES,
scope=self.scope + "/" + self.train_op_scope) # to do: remove prefix
train_op_vars.extend(tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope=self.train_op_scope))
self.sess.run(tf.variables_initializer(train_op_vars))
def __create_update_target_net_op(self):
source_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=self.source_var_scope)
target_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=self.target_var_scope)
update_target_net_op_list = [target_vars[i].assign(self.tau * source_vars[i] + (1 - self.tau) * target_vars[i])
for i in range(len(source_vars))]
# source_net_dict = {var.name[len(self.source_var_scope):]: var for var in source_vars}
# target_net_dict = {var.name[len(self.target_var_scope):]: var for var in target_vars}
# keys = source_net_dict.keys()
# update_target_net_op_list = [target_net_dict[key].assign((1-self.tau)*target_net_dict[key]+self.tau*source_net_dict[key]) # for key in keys]
# for s_v, t_v in zip(source_vars, target_vars):
# update_target_net_op_list.append(t_v.assign(self.tau*s_v - (1-self.tau)*t_v))
self.update_target_net_op = tf.group(*update_target_net_op_list)
def predict_action_source_net(self, feed_state, sess=None):
sess = sess or self.sess
return sess.run(self.action_output, {self.input_state: feed_state})
def predict_action_target_net(self, feed_state, sess=None):
sess = sess or self.sess
return sess.run(self.target_net_actions_output, {self.input_state: feed_state})
def update_source_actor_net(self, feed_state, actions_grad, sess=None):
sess = sess or self.sess
batch_size = len(actions_grad)
return sess.run([self.train_policy_op],
{self.input_state: feed_state,
self.actions_grad: actions_grad / batch_size})
def update_target_actor_net(self, sess=None):
sess = sess or self.sess
return sess.run(self.update_target_net_op)
def __create_get_layer_weight_op_source(self):
with tf.variable_scope(self.source_var_scope, reuse=True):
self.h1_weight_source = tf.get_variable("hidden_1/kernel")
self.h1_bias_source = tf.get_variable("hidden_1/bias")
def run_layer_weight_source(self, sess=None):
sess = sess or self.sess
return sess.run([self.h1_weight_source, self.h1_bias_source])
def __create_get_layer_weight_op_target(self):
with tf.variable_scope(self.target_var_scope, reuse=True):
self.h1_weight_target = tf.get_variable("hidden_1/kernel")
self.h1_bias_target = tf.get_variable("hidden_1/bias")
def run_layer_weight_target(self, sess=None):
sess = sess or self.sess
return sess.run([self.h1_weight_target, self.h1_bias_target])
class DDPG_Critic(object):
def __init__(self, state_dim, action_dim, optimizer=None, learning_rate=0.001, tau=0.001, scope="", sess=None):
self.scope = scope
self.sess = sess
self.state_dim = state_dim
self.action_dim = action_dim
self.learning_rate = learning_rate
self.l2_reg = 0.01
self.optimizer = optimizer or tf.train.AdamOptimizer(self.learning_rate)
self.tau = tau
self.h1_dim = 400
self.h2_dim = 100
self.h3_dim = 300
self.activation = tf.nn.relu
self.kernel_initializer = tf.contrib.layers.variance_scaling_initializer()
# fan-out uniform initializer which is different from original paper
self.kernel_initializer_1 = tf.random_uniform_initializer(minval=-1 / sqrt(self.h1_dim),
maxval=1 / sqrt(self.h1_dim))
self.kernel_initializer_2 = tf.random_uniform_initializer(minval=-1 / sqrt(self.h2_dim),
maxval=1 / sqrt(self.h2_dim))
self.kernel_initializer_3 = tf.random_uniform_initializer(minval=-1 / sqrt(self.h3_dim),
maxval=1 / sqrt(self.h3_dim))
self.kernel_initializer_4 = tf.random_uniform_initializer(minval=-3e-3, maxval=3e-3)
self.kernel_regularizer = tf.contrib.layers.l2_regularizer(self.l2_reg)
with tf.name_scope("critic_input"):
self.input_state = tf.placeholder(tf.float32, shape=[None, self.state_dim], name="states")
self.input_action = tf.placeholder(tf.float32, shape=[None, self.action_dim], name="actions")
with tf.name_scope("critic_label"):
self.y = tf.placeholder(tf.float32, shape=[None, 1], name="y")
self.source_var_scope = "ddpg/" + "critic_net"
with tf.variable_scope(self.source_var_scope):
self.q_output = self.__create_critic_network()
self.target_var_scope = "ddpg/" + "critic_target_net"
with tf.variable_scope(self.target_var_scope):
self.target_net_q_output = self.__create_target_network()
with tf.name_scope("compute_critic_loss"):
self.__create_loss()
self.train_op_scope = "critic_train_op"
with tf.variable_scope(self.train_op_scope):
self.__create_train_op()
with tf.name_scope("critic_target_update_train_op"):
self.__create_update_target_net_op()
with tf.name_scope("get_action_grad_op"):
self.__create_get_action_grad_op()
self.__create_get_layer_weight_op_source()
self.__create_get_layer_weight_op_target()
def __create_critic_network(self):
h1 = tf.layers.dense(self.input_state,
units=self.h1_dim,
activation=self.activation,
kernel_initializer=self.kernel_initializer_1,
# kernel_initializer=self.kernel_initializer,
kernel_regularizer=self.kernel_regularizer,
name="hidden_1")
# h1_with_action = tf.concat([h1, self.input_action], 1, name="hidden_1_with_action")
h2 = tf.layers.dense(self.input_action,
units=self.h2_dim,
activation=self.activation,
kernel_initializer=self.kernel_initializer_2,
# kernel_initializer=self.kernel_initializer,
kernel_regularizer=self.kernel_regularizer,
name="hidden_2")
h_concat = tf.concat([h1, h2], 1, name="h_concat")
h3 = tf.layers.dense(h_concat,
units=self.h3_dim,
activation=self.activation,
kernel_initializer=self.kernel_initializer_3,
# kernel_initializer=self.kernel_initializer,
kernel_regularizer=self.kernel_regularizer,
name="hidden_3")
# h2_with_action = tf.concat([h2, self.input_action], 1, name="hidden_3_with_action")
q_output = tf.layers.dense(h3,
units=1,
# activation=tf.nn.sigmoid,
activation=None,
kernel_initializer=self.kernel_initializer_4,
# kernel_initializer=self.kernel_initializer,
kernel_regularizer=self.kernel_regularizer,
name="q_output")
return q_output
def __create_target_network(self):
# get source variales and initialize
source_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=self.source_var_scope)
self.sess.run(tf.variables_initializer(source_vars))
# create target network and initialize it by source network
q_output = self.__create_critic_network()
target_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=self.target_var_scope)
target_init_op_list = [target_vars[i].assign(source_vars[i]) for i in range(len(source_vars))]
self.sess.run(target_init_op_list)
return q_output
def __create_loss(self):
self.loss = tf.losses.mean_squared_error(self.y, self.q_output)
def __create_train_op(self):
self.train_q_op = self.optimizer.minimize(self.loss)
train_op_vars = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES,
scope=self.scope + "/" + self.train_op_scope) # to do: remove prefix
train_op_vars.extend(tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope=self.train_op_scope))
self.sess.run(tf.variables_initializer(train_op_vars))
def __create_update_target_net_op(self):
source_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=self.source_var_scope)
target_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=self.target_var_scope)
update_target_net_op_list = [target_vars[i].assign(self.tau * source_vars[i] + (1 - self.tau) * target_vars[i])
for i in range(len(source_vars))]
# source_net_dict = {var.name[len(self.source_var_scope):]: var for var in source_vars}
# target_net_dict = {var.name[len(self.target_var_scope):]: var for var in target_vars}
# keys = source_net_dict.keys()
# update_target_net_op_list = [target_net_dict[key].assign((1-self.tau)*target_net_dict[key]+self.tau*source_net_dict[key]) # for key in keys]
# for s_v, t_v in zip(source_vars, target_vars):
# update_target_net_op_list.append(t_v.assign(self.tau*s_v - (1-self.tau)*t_v))
self.update_target_net_op = tf.group(*update_target_net_op_list)
def __create_get_action_grad_op(self):
self.get_action_grad_op = tf.gradients(self.q_output, self.input_action)
def predict_q_source_net(self, feed_state, feed_action, sess=None):
sess = sess or self.sess
return sess.run(self.q_output, {self.input_state: feed_state,
self.input_action: feed_action})
def predict_q_target_net(self, feed_state, feed_action, sess=None):
sess = sess or self.sess
return sess.run(self.target_net_q_output, {self.input_state: feed_state,
self.input_action: feed_action})
def update_source_critic_net(self, feed_state, feed_action, feed_y, sess=None):
sess = sess or self.sess
return sess.run([self.train_q_op],
{self.input_state: feed_state,
self.input_action: feed_action,
self.y: feed_y})
def update_target_critic_net(self, sess=None):
sess = sess or self.sess
return sess.run(self.update_target_net_op)
def get_action_grads(self, feed_state, feed_action, sess=None):
sess = sess or self.sess
return (sess.run(self.get_action_grad_op, {self.input_state: feed_state,
self.input_action: feed_action}))[0]
def __create_get_layer_weight_op_source(self):
with tf.variable_scope(self.source_var_scope, reuse=True):
self.h1_weight_source = tf.get_variable("hidden_1/kernel")
self.h1_bias_source = tf.get_variable("hidden_1/bias")
def run_layer_weight_source(self, sess=None):
sess = sess or self.sess
return sess.run([self.h1_weight_source, self.h1_bias_source])
def __create_get_layer_weight_op_target(self):
with tf.variable_scope(self.target_var_scope, reuse=True):
self.h1_weight_target = tf.get_variable("hidden_1/kernel")
self.h1_bias_target = tf.get_variable("hidden_1/bias")
def run_layer_weight_target(self, sess=None):
sess = sess or self.sess
return sess.run([self.h1_weight_target, self.h1_bias_target])
class Model(object):
def __init__(self,
state_dim,
action_dim,
optimizer=None,
actor_learning_rate=1e-4,
critic_learning_rate=1e-3,
tau=0.001,
sess=None):
self.state_dim = state_dim
self.action_dim = action_dim
self.actor_learning_rate = actor_learning_rate
self.critic_learning_rate = critic_learning_rate
self.tau = tau
# tf.reset_default_graph()
self.sess = sess or tf.Session()
self.global_step = tf.Variable(0, name="global_step", trainable=False)
global_step_vars = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope="global_step")
self.sess.run(tf.variables_initializer(global_step_vars))
self.actor_scope = "actor_net"
with tf.name_scope(self.actor_scope):
self.actor = DDPG_Actor(self.state_dim,
self.action_dim,
learning_rate=self.actor_learning_rate,
tau=self.tau,
scope=self.actor_scope,
sess=self.sess)
self.critic_scope = "critic_net"
with tf.name_scope(self.critic_scope):
self.critic = DDPG_Critic(self.state_dim,
self.action_dim,
learning_rate=self.critic_learning_rate,
tau=self.tau,
scope=self.critic_scope,
sess=self.sess)
def update(self, state_batch, action_batch, y_batch, sess=None):
sess = sess or self.sess
self.critic.update_source_critic_net(state_batch, action_batch, y_batch, sess)
action_batch_for_grad = self.actor.predict_action_source_net(state_batch, sess)
action_grad_batch = self.critic.get_action_grads(state_batch, action_batch_for_grad, sess)
self.actor.update_source_actor_net(state_batch, action_grad_batch, sess)
self.critic.update_target_critic_net(sess)
self.actor.update_target_actor_net(sess)
def predict_action(self, observation, sess=None):
sess = sess or self.sess
return self.actor.predict_action_source_net(observation, sess)| 强化学习(MDP)概念 | 对应推荐系统中的概念 |
|---|---|
| 智能体(Agent) | 推荐系统 |
| 环境(Environment) | 用户 |
| 状态(State) | 状态来自于Agent对Environment的观察,在推荐场景下即用户的意图和所处场景;具体可以使用Dense和Embedding特征表达用户所处的时间、地点、场景,以及更长时间周期内用户行为习惯的挖掘。 |
| 动作(Action) | 建议先建模奖励后再建模动作;解决业务问题不同对应的动作也不同,比较常见的是多目标排序时的模型融合比例,或者推荐系统中各个召回的流量分发占比等。 |
| 奖励(Reward) | 根据用户反馈给予Agent相应的奖励,为业务目标直接负责。比较常见的是点击率,转化率或者停留时长等。 |
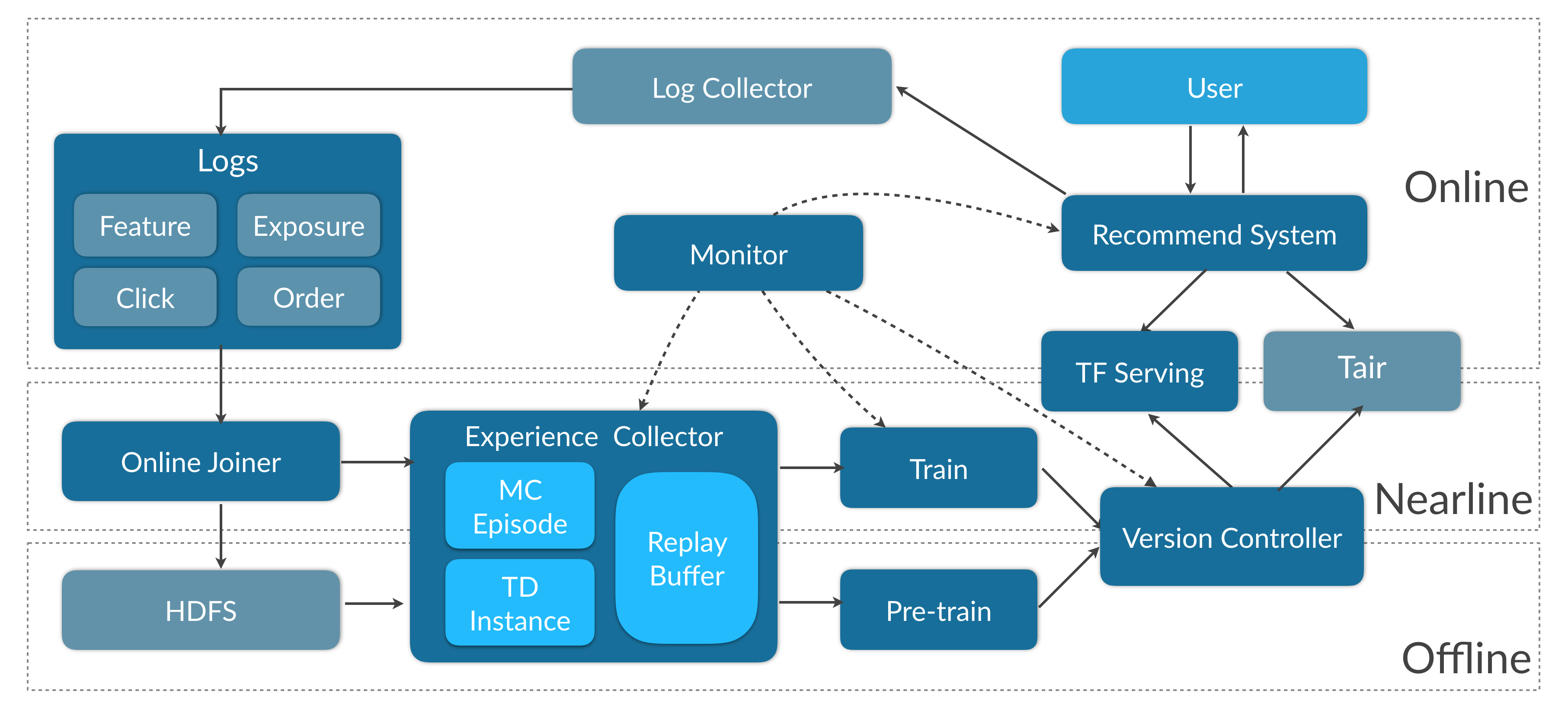
实时强化学习框架设计
标签:sqrt undle bundle 问题: 时间差 feed 集合 use output
原文地址:https://www.cnblogs.com/arachis/p/DRL.html