标签:客户端连接 ola 索引数据 全文索引 完全 精确 mysql集群 内部数据 范围
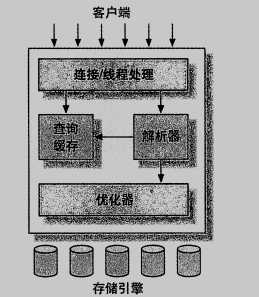
mysql 的逻辑架构分为三层:
最上层的服务大多数基于网络的客户端、服务器的工具或者服务都有类似的架构,比如连接处理,授权认证、安全等
第二层架构:mysql的核心服务功能都在这一层,包括查询解析,分析,优化,缓存以及所有的内置函数,所有跨存储引擎的功能都在这一层实现:存储过程,触发器、视图
第三层:包含存储引擎。负责数据的存储和提取,innoDB是个例外,它会解析外键定义,因为mysql服务器本身没有实现该功能
连接管理与安全性:
当客户端连接到mysql服务器是,服务器需要对其进行认证,认证基于用户名,原始主机信息和密码,一旦客户端连接成功,服务器 会继续验证该客户端是否具有执行某个特定查询的权限
优化与执行:
mysql会解析查询,并创建内部数据结构(解析树),然后对其进行各种优化,包括重写查询,决定表的读取顺序,以及选择合适的索引,用户可以通过特殊的关键字提示优化器,影响他的决策过程,也可以请求优化器解释优化过程的各个因素,使yoghurt可以知道服务器是如何进行优化决策的,并提供一个参考基准,便于用户重构查询和修改相关配置,优化查询效率
存储引擎对于优化查询时有影响的
对于select语句,在解析查询之前,服务器会先检查缓存,如果能找到对应的查询,服务器就不会再执行查询解析,优化和执行的整个过程,而是直接返回查询结果
并发控制:
只要有多个查询需要在同一时刻修改数据,都会产生并发控制的问题。
如果应用锁可以保证数据的完整性,不被破坏,但是并不支持并发处理。
两个层面的并发控制:服务器层和存储引擎层
读写锁:通过实现一个由两种类型的锁组成的锁系统来解决问题,也称作共享锁和排它锁或者读锁和写锁
读锁是共享的,互相不阻塞的,而写锁则是排他的,
锁粒度:一种提高共享资源并发性的方式就是让锁定对象更有选择性,尽量只锁定需要修改的部分数据,而不是所有资源。更理想的方式是,是对会修改的数据片进行精确的锁定,
在任何时候,在给定的资源上,锁定的数据量越少,则系统的并发程度越高,只要相互之间不发生冲突即可
所谓的锁策略,就是在锁的开销和数据的安全性之间寻求平衡,大多数商业数据库系统没有提供能多的选择,一般都是在表上施加行级锁,而mysql则提供了多种选择,每种mysql存储引擎都可以实现自己的锁策略和锁粒度
表锁:
锁开销最小的策略,会锁定整张表,写锁也比读锁优先级更高,一个写锁请求可能会被插入到读锁队列的前面
行级锁:
最大程度地支持并发处理,同时也带来最大的锁开销,行级锁只在存储引擎层实现,服务器层没有实现,所有的引擎都以自己的方式实现了锁
事务:ACID
atomicity consistency isolation durability
每种存储引擎实现的隔离级别不尽相同
四种隔离级别:innodb引擎支持所有隔离级别
read uncommitted:未提交读,事务可以读取未提交的数据,脏读(很少使用)
read committed:提交读,大多数数据库系统的默认隔离级别都是read committed,但mysql不是,这和个级别有时候也叫做不可重复读,两次执行同样的查询可能会得到不一样的结果
repeatable read:可重复读,是mysql的默认事务隔离级别,该级别保证了在同一个事务中多次读取同样的记录结果是一致的。但是无法解决另外一个幻读问题。幻读指的是当某个事务在读取某个范围内的记录时,另外一个事务又在该范围内插入了新的记录,档之前的事务再次读取该范围的记录时,会产生幻行。
innodb和xtradb存储引擎通过多版本并发控制解决了幻读的问题。
serializable:可串行化,最高的隔离级别,强制事务串行执行,避免幻读问题。也很少用。
事务日志;
? 帮助提高事务的效率,使用事务日志,存储引擎在修改表的数据时只需要修改其内存拷贝,再把该修改行为记录到持久在硬盘上的事务日志中,而不用每次都将修改的数据本身持久到磁盘,事务日志采用的追加的方式,因此写日志的操作时磁盘上一小块区域内的顺序I/O操作,而不像随机I/O需要在磁盘的多个地方移动磁头,所以采用事务日志的方式相对来说快的多
? 修改数据需要写两次磁盘
mysql中的事务
两种事务型的存储引擎:innodb和NDB Cluster
SET AUTOCOMMIT = 0 ;设置禁用自动提交模式,修改AUTOCOMMIT对本身就是非事务型的表,不会有任何影响。
有些命令在执行之前会强制执行commit提交当前的活动事务。
SET TRANSACTION ISOLATION LEVEL read committed;设置隔离级别。可以在配置文件中设置整个数据库的隔离级别,也可以只改变当前会话的隔离级别
在事务中混合使用存储引擎
mysql服务器层不管理事务,事务是由下层的存储引擎实现的,所以在同一个事务中,使用多种存储引擎是不可靠的
MVCC:多版本并发控制
innodb的mvcc:通过在每行记录后面保存两个隐藏的列来实现的,一个列保存了行的创建时间,一个保存行的过期时间(删除时间),存储的并不是实际的时间值,而是系统版本号。每开始一个新的事务,系统版本号都会自动递增。
不同的存储引擎保存数据和索引的方式是不同的,但表的定义则是在mysql服务层统一处理的
SHOW TABLE STATUS LIKE ‘user‘;显示相关表信息
innodb是mysql的默认事务型引擎,被设计用来处理大量的短期事务,短期事务大部分情况是正常提交的,很少会被回滚,
innodb基于聚簇索引建立,innodb的索引结构和mysql的其他存储引擎有很大的不同,聚簇索引对主键查询有很高的性能,不过它的二级索引中必须包含主键列,若表上的索引较多的话,主键应当尽可能小。存储格式是平台独立的,可移植。崩溃后可安全恢复
myisam存储引擎;崩溃后无法恢复。支持数据修复,支持全文索引,基于分词创建的索引,对整张表加锁,写锁具有排他性,读锁共享,不能很好的支持高并发
Memory引擎:基于内存,所以不保存数据 ,支持hash索引,是表级锁,并发写入性能较低, 应用场景:用于保存数据分析中产生 的中间数据,用于查找或者映射表,MySQL在执行查询的过程中需要使用临时表来保存中间结果,内部使用的临时表就是memory表。
NDB cluster引擎:
mysql服务器、NDB集群存储引擎,以及分布式的,share-nothing的,容灾的,高可用的NDB数据库的组合,被称为mysql集群。
第三方存储引擎:
OLTP:XtraDB是基于innodb引擎的一个改进版本,可以作为innodb的一个完全的替代产品。
另外还有一些和innodb非常类似的OLTP类存储引擎,比如都支持acid事务和mvcc,其中一个就是pbxt。对固态存储ssd提供了适当的支持。
tokudb引擎使用了一种新的叫做分形树的索引数据结构,该结构是缓存无关的,因此即使其大小超过内存性能也不会下降,是一种大数据存储引擎,因为拥有很高的压缩比,可以在很大的数据量上创建大量索引 。
面向列的存储引擎:
mysql默认是面向行的,服务器的查询也是以行为单位处理的,
infobright是最有名的面向列的存储引擎,在非常的数据量(数十TB)时,该引擎工作良好。视为数据分析和数据仓库应用设计的。数据高度压缩,按照块进行排序,每个块都对应一组元数据。访问元数据即可决定是否跳过该块,该引擎不支持缩影。
标签:客户端连接 ola 索引数据 全文索引 完全 精确 mysql集群 内部数据 范围
原文地址:https://www.cnblogs.com/-huoxingrenlei-26/p/11666518.html