标签:html pytho 指定 this port demo pre findall price
正则表达式无论是提取数据还是在做爬虫的时候都会经常使用,下面说下re模块的常见使用。
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
函数语法:
re.match(pattern, string, flags=0)
import re # todo re.match的用法,从字符串第一个开始匹配 content = ‘Hello 123 4567 World_this a regex demo‘ # ^todo 匹配字符串开头,$匹配字符串结尾 result = re.match(‘^Hello\s\d{3}\s\d{4}\s\w{10}.*demo$‘,content) print(result) # todo 返回匹配范围 print(result.span()) # todo 返回匹配结果 print(result.group()) # todo 泛匹配 result = re.match(‘^Hello.*demo$‘,content) print(result.group()) # todo 匹配指定目标 result = re.match(‘^Hello\s(\d+)\s(\d+)\sWorld.*demo$‘,content) print(result.group(1),result.group(2)) # todo 贪婪匹配,尽可能匹配多的字符 result = re.match(‘^He.*(\d+).*demo$‘,content) print(result.group(1)) # todo .*?非贪婪匹配,尽可能匹配少的字符 result = re.match(‘^He.*?(\d+).*demo$‘,content) print(result.group(1)) contents = ‘‘‘Hello 1234567 World_this is a regex demo‘‘‘ # todo 匹配模式,re.S匹配换行 results = re.match(‘^He.*?(\d+).*?demo$‘,contents,re.S) print(results.group(1)) # todo 转义\,匹配特殊字符需要加转义符\ content = ‘price is $5.00‘ result = re.match(‘price is \$5\.00‘,content) print(result)
re.search 扫描整个字符串并返回第一个成功的匹配。
函数语法:
re.search(pattern, string, flags=0)
‘‘‘绝世唐门小说链接匹配‘‘‘ import re import requests resp = requests.get(‘http://www.jueshitangmen.info‘).text print(resp) # todo 获取.css结尾的链接 pattern = ‘<link.*?href="(http:.*?.css)"\s\/>‘ css = re.search(pattern,resp,re.S) print(css.group(1))
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。
‘‘‘绝世唐门链接匹配‘‘‘ import re import requests resp = requests.get(‘http://www.jueshitangmen.info‘).text print(resp) # todo 获取所有以.html结尾的链接 pattern = ‘<li>.*?\shref="(http:.*?.html)"\srel‘ html_link = re.findall(pattern,resp,re.S) print(html_link) for i in html_link: print(i)
单个字符串匹配:
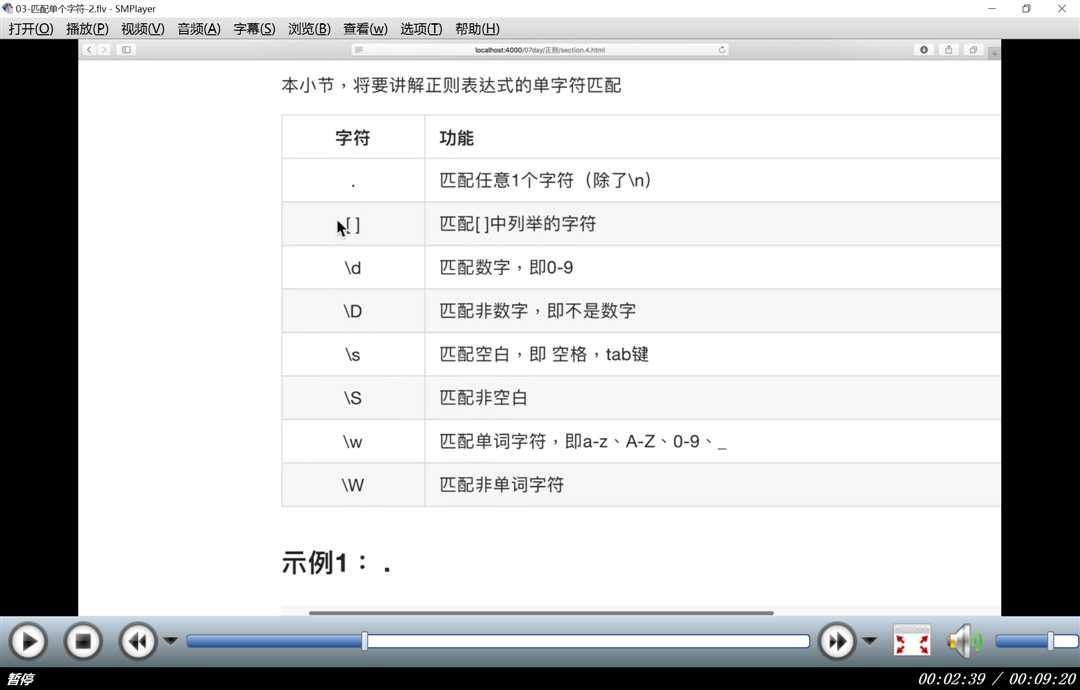
多个字符串匹配:
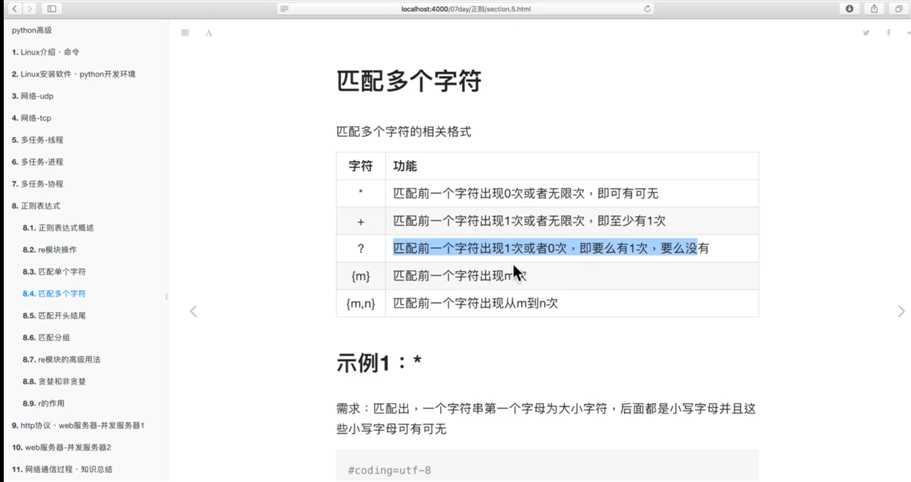
匹配分组:
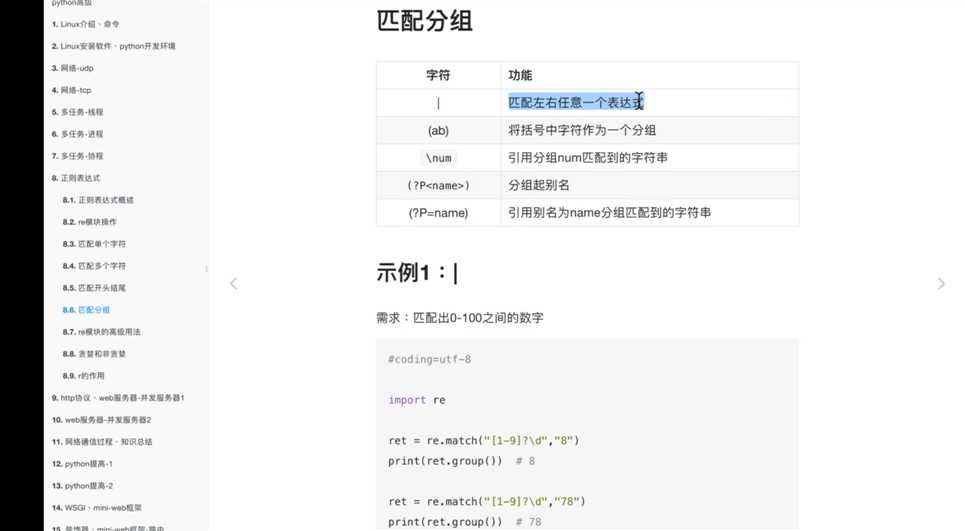
常见匹配模式:

标签:html pytho 指定 this port demo pre findall price
原文地址:https://www.cnblogs.com/xiamaojjie/p/11666783.html