标签:blog http io os ar 使用 for sp 数据
阿里云用户:morenocjm
实践是检验真理的唯一标准,学习技术需要通过实践过程中的不断尝试,才能够快速掌握要领。OTS是构建在阿里云飞天分布式系统之上的NoSQL数据库服务,提供海量结构化数据的存储和实时访问。刚好想用手上的一台ECS做点什么,既然如此,那就通过搭建简单线上产品(alijot.com 快速记)的过程,学习下NoSQL数据库OTS吧。
-----------------------------------------------------------------------------------------------------------------------------------------------------------
•服务器配置:CPU:1核 内存:1GB 数据盘:15G 带宽:1Mbps
•产品定位:基于阿里云存储的快速记服务,PC,手机端通用
•产品功能:目前提供基础记事功能,自动定时(间隔5s)存储,避免编辑过程中的意外(后期将采用oss支持云盘,完善记录逻辑及体验)
-----------------------------------------------------------------------------------------------------------------------------------------------------------
OTS数据库设计(初步):
•OTS基本概念:
1.主键,属性,分片键:
OTS 数据模型概念包括表、行、主键和属性。主键和属性是读写操作的关键,通过传入主键作为索引值,传入属性值作为要查询的数据(属性键是可变的)。主键最多支持4个主键列,而组成主键的第一个主键列又称为分片键, 好的OTS数据表设计中,分片键可以保证是唯一且无连续(并发无序),能够很好的满足分片的特性。OTS 按照分片键的范围对表的数据进行分区,拥有相同分片键的行会被划分到同一个分片。为了防止分片过大无法切分,OTS 对单个分片键下的数据量做出了限制。单个分片键下的所有行数据大小之和不能超过 1GB。
2.吞吐量:
关于吞吐量的概念,文档有介绍,以1KB 向上取整计算,如果指定的范围内没有数据,则消耗 1 读服务能力单元,目前最大读写吞吐量都为5000。举个学生一卡通的例子:当数据以时间作为分片键时,已经毕业的学生的卡片,不会再产生消费记录。假如 CardID 是随着卡片申请时间递增的,以 CardID 作为分片键,会导致已经毕业的学生的 CardID 没有访问压力却被分配到预留读写吞吐量,造成浪费。处理方法是将已经超出维护年限的消费记录表中的数据导出,存入 OSS(Open Storage Service) 归档,或直接删除。
3.合理存储:
将原始数据顺序打乱后再进行导入。保证写入数据均匀的分配在各个分片键上。或者使用多个工作线程并行导入数据。把大的数据集合切分成很多个小集合。工作线程随机选取小集合进行数据导入。
•基于以上基本规则进行数据表设计:
首先,列出和数据库有关的需求:
1.用户注册,登录,登出,用户信息的获取
2.快速记 记录的存储及查看记录时数据读取以后的组织逻辑
3.需要保证用户查询和写入的速度
然后,进行需求分析:
1.用户相关数据有 用户名,密码,状态,权限,等级,注册时间,个人信息,记录创建时间列表。 (因为需要保证分片均匀,我采用用户名做主键,且为分片键)
2.记录的相关数据有 记录创建时间,所属用户,状态,类型,内容,自动保存的改变内容及时间。
3.取数据时,我首先要确认用户信息,然后通过当前用户的用户名,找到用户的所有记录值,日期作为主键mid值,保证唯一性,然后写入到OTS中。官方文档似乎没有找到通过属性键找数据的方法,所以我选择把记录的主键放到用户的属性键来获取数据。我还需要根据属性值排序且根据范围读取的功能,以满足用户查看某几天记录的需求,于是我看到了一个方法get_range( “OTS产品文档” 第28页的GetRange方法,SKD中的DOCTMENT也有出现):
get_range(self, table_name, direction, inclusive_start_primary_key, exclusive_end_primar y_key, columns_to_get=None, limit=None)
说明:根据范围条件获取多行数据。
``table_name``是对应的表名
``direction``表示范围的方向,字符串格式,取值包括‘FORWARD‘和‘BACKWARD‘
``inclusive_start_primary_key``表示范围的起始主键(在范围内)
``exclusive_end_primary_key``表示范围的结束主键(不在范围内)
``columns_to_get``是可选参数,表示要获取的列的名称列表,类型为list;如果不填,表示获取所有列。
``limit``是可选参数,表示最多读取多少行;如果不填,则没有
示例
inclusive_start_primary_key = {‘gid‘:1, ‘uid‘:INF_MIN}
exclusive_end_primary_key = {‘gid‘:4, ‘uid‘:INF_MAX}
columns_to_get = [‘name‘, ‘address‘, ‘mobile‘, ‘age‘]
consumed, next_start_primary_key, row_list = ots_client.get_range(
‘myTable‘, ‘FORWARD‘,
inclusive_start_primary_key, exclusive_end_primary_key,
columns_to_get, 100
)
返回值
``consumed``表示本次操作消耗的CapacityUnit,是ots2.metadata.CapacityUnit类的实例
``next_start_primary_key``表示下次get_range操作的起始点的主健列,类型为dict
``row_list``表示本次操作返回的行数据列表,格式为:[(primary_key_columns,attribute_columns), ...]
(在这里踩了个坑,毕竟是第一次接触NoSQL,嘿嘿。。。不同表分片键可以相同,而且分片键才是取数据的关键,当然,如果主键中有多个属性,那么查询的时候就必须把所有的主属性都传入,否则会报错哦。我就是以时间作为分片键,原以为两个值同时构成取数据的制约,结果导致根据时间取出的数据是所有用户的数据,囧,所有重新设计了数据库)
最后,初步设定表结构(似乎很简单,原谅我是新手):
1 user | joter | pwd,status,power,range,date,info,modatestart,modatelast
用户表:用户名,密码,状态,权限,等级,注册时间,个人信息,记录创建时间列表
2 modify | joter,modate | status,type,title,content
记录表:用户名(分片),记录创建时间,状态,类型,标题,内容
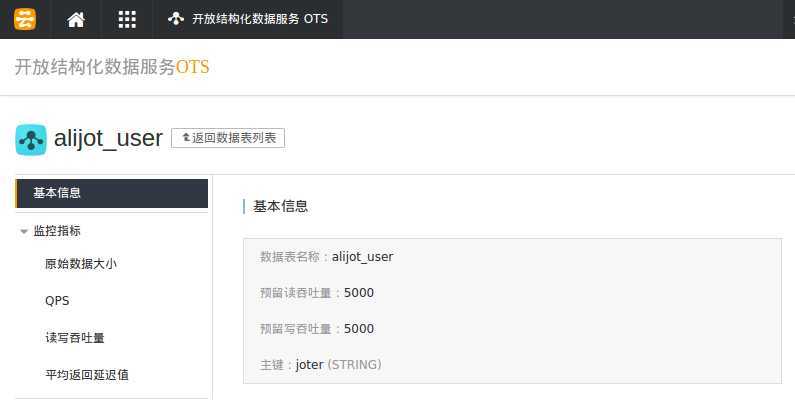
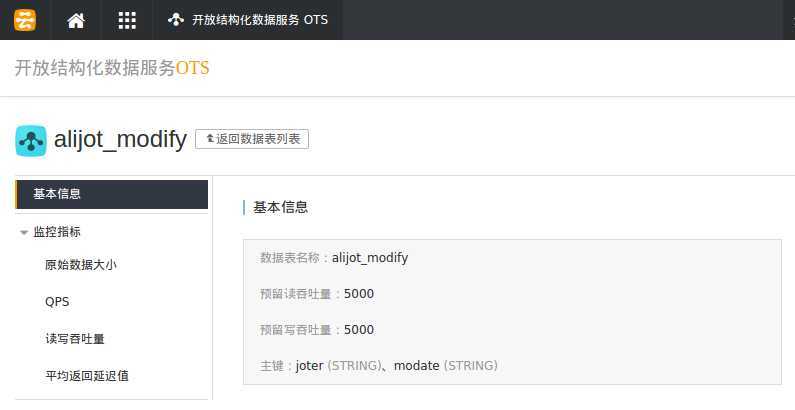
可以看到,创建表时只用跟上吞吐量和主键,体现了属性值的可变性。
•有关OTS数据库操作的具体实现:
首先需要下载SDK并且安装,我使用了Python SDK,下载地址在OTS介绍页面(文章末尾给出地址),需要python2.7,个人使用的服务器系统是ubuntu,如果选择centos需要自行升级python版本。
在调用代码之前需要加入以下导包代码:
from ots2 import *ENDPOINT = ‘http://isdot.cn-hangzhou.ots.aliyuncs.com/‘
ACCESSID = ‘TjfCaKv5YTjf8aBavUaKvD‘ACCESSKEY = ‘w5nB9tfrSuBd5xzd5UFrdtQocxhAH3IOV‘
INSTANCENAME = ‘isdot‘ots_client = OTSClient(ENDPOINT, ACCESSID, ACCESSKEY, INSTANCENAME)
#以上代码中KEY无效,不必尝试;ACCESSID和ACCESSKEY大概就是这样长短的两个值,需要你在面板里获取
0.创建,删除表的工作可以很方便的在web端操作
1.注册
通过主键joter随意获取任意值 如pwd,判断是否存在用户:
primary_key = {‘joter‘:name} # 主键
columns_to_get = [‘pwd‘] # 属性
consumed, primary_key_columns, attribute_columns = ots_client.get_row(‘alijot_user‘, primary_key, columns_to_get)
#变量 consumed代表返回的状态信息,如:存储消耗的写CapacityUnit值的变量应该是这样的 consumed.write
#primary_key_columns 代表取得的主键值,在批量获取数据的时候用的到
#attribute_columns 代表取得的熟悉值,通过attribute_columns.get(‘power‘)获取具体值
#方法 get_row为通过主键获取单行
将用户信息插入数据库的操作:
primary_key = {‘joter‘:name}
attribute_columns = {‘pwd‘:pwd, ‘power‘:12}
condition = Condition(‘EXPECT_NOT_EXIST‘) #判断的调节,当不存在
consumed = ots_client.put_row(‘alijot_user‘, condition, primary_key, attribute_columns)
#put_row方法是单行插入
2.登录
primary_key = {‘joter‘:name}
columns_to_get = [‘pwd‘, ‘power‘]
consumed, primary_key_columns, attribute_columns = ots_client.get_row(‘alijot_user‘, primary_key, columns_to_get)
#判断attribute_columns 是否为空来得到用户名是否正确以及通过判断pwd==attribute_columns.get(‘pwd‘)确定密码是否正确
3.读取用户信息
name = self.get_secure_cookie("test") #获取cookie值
primary_key = {‘joter‘:name}
columns_to_get = [‘pwd‘, ‘power‘]
consumed, primary_key_columns, attribute_columns = ots_client.get_row(‘alijot_user‘, primary_key, columns_to_get)
print u‘成功读取数据,消耗的读CapacityUnit为:%s‘ % consumed.read #输出读写存储量log
print u‘name信息:%s‘ % attribute_columns.get(‘name‘)
self.render(‘user.html‘,power=attribute_columns.get(‘power‘),name=name) #通过tornado的render传值到html页面进行渲染
4.快速记
name = self.get_secure_cookie("test")
title = self.get_argument("title", None)
content = self.get_argument("content", None) #得到POST提交过来的数据
modate = time.strftime(‘%g%m%d-%T‘,time.localtime(time.time())) #获取当前时间作为主键
primary_key = {‘modate‘:modate,‘joter‘:name} #主键值
attribute_columns = {‘status‘:0,‘type‘:‘text‘,‘title‘:title,‘content‘:content} #传入的属性值,可变
condition = Condition(‘EXPECT_NOT_EXIST‘) #判断的条件
consumed = ots_client.put_row(‘alijot_user‘, condition, primary_key, attribute_columns) #执行插入一条记录
5.读取记录
columns_to_get = [‘title‘, ‘content‘] #主键
inclusive_start_primary_key = {‘joter‘:name, ‘modate‘:INF_MIN } #开始条件
exclusive_end_primary_key = {‘joter‘:name, ‘modate‘:INF_MAX } #结束条件
columns_to_get = [‘title‘, ‘content‘,‘modate‘] # 如果需要获得文档中描述的返回列表,可以留空,或把主属性也传入
consumed, next_start_primary_key, row_list = ots_client.get_range( #这里就是按照范围查询了
‘alijot_modify‘, ‘FORWARD‘, #控制查询的方向,倒序显示:改成BACKWARD,颠倒开始和结束条件INF_MIN/INF_MAX
inclusive_start_primary_key, exclusive_end_primary_key,
columns_to_get, 100 #100是限制的条数,不填为全部获取
)
self.render("modify.html", row_list = row_list) #传给前端去渲染
6.删除记录
未完
至此,很简陋的功能就完成了
•总结:
尝试过程中,遇到了几个小问题,应该属于初学者都会犯的错误。在解决了这几个问题后项目的基本功能走通后,瞬间有了种收获颇丰的赶脚,嘿嘿。而关于吞吐量的分配,后期需要仔细考虑,至于上传图片,前端JS效果,找回密码,用户设置,第三方登录 等功能还有待开发。
近期自己实习所在的公司正在赶着上线产品以及上线维护,所以个人时间不多。我觉得既然技术还不到家,心思还是得放在工作上的,不过后期我还会不断完善,希望未来某天这个项目原型能够真正成长起来。
-----------------------------------------------------------------------------------------------------------------------------------------------------------
•OTS资料整理:
OTS介绍页面:http://www.aliyun.com/product/ots/?spm=5176.383715.3.5.F6qwY2&utm_content=m_199
进入 OTS介绍页面,在最下方的可以找到 “产品帮助” 分类,可看到“OTS产品文档”。个人认为只用看 “资料中心” 分类下的资料以及SDK中的DOCUMENT即可快速上手。
-----------------------------------------------------------------------------------------------------------------------------------------------------------
alijot.com 快速记 尚处于测试开发阶段,各种功能有待完善,欢迎大家试玩,公网地址是 115.28.47.91:8888
欢迎大家给我投上宝贵的一票 (选票可修改,可多选) 以下是我的测评文章的投票地址:
编号26 http://bbs.aliyun.com/read/179696.html
编号39 http://bbs.aliyun.com/read/180418.html
原文地址:http://bbs.aliyun.com/read/180418.html
参加活动:http://promotion.aliyun.com/act/aliyun/freebeta/
【阿里云产品公测】OTS使用之简单线上产品实践基于PythonSDK
标签:blog http io os ar 使用 for sp 数据
原文地址:http://www.cnblogs.com/aliyunblogs/p/4056730.html