标签:form 趋势 本地 两种 清理 数据查询 删除 控制 key

MongoDB 是一款流行的开源文档型数据库,从它的命名来看,确实是有一定野心的。
MongoDB 的原名一开始来自于 英文单词"Humongous", 中文含义是指"庞大",即命名者的意图是可以处理大规模的数据。
但笔者更喜欢称呼它为 "芒果"数据库,除了译音更加相近之外,原因还来自于这几年使用 MongoDB 的两层感觉:
第一层感受是"爽",使用这个文档数据库的特点是几乎不受什么限制,一方面Json文档式的结构更容易理解,而无Schema约束也让DDL管理更加简单,一切都可以很快速的进行。
第二层感受是"酸爽",这点相信干运维或是支撑性工作的兄弟感受会比较深刻,MongoDB 由于入门体验"太过于友好",导致一些团队认为用好这个数据库是个很简单的事情,所以开发兄弟在存量系统上埋一些坑也是正常的事情。
所谓交付一时爽,维护火葬场.. 当然了,这句话可能有些过。 但这里的潜台词是:与传统的RDBMS数据库一样,MongoDB 在使用上也需要认真的考量和看护,不然的化,会遇到更多的坑。
那么,尽管文档数据库在选型上会让一些团队望而却步,仍然不阻碍该数据库所获得的一些支持,比如 DB-Engine 上的排名:
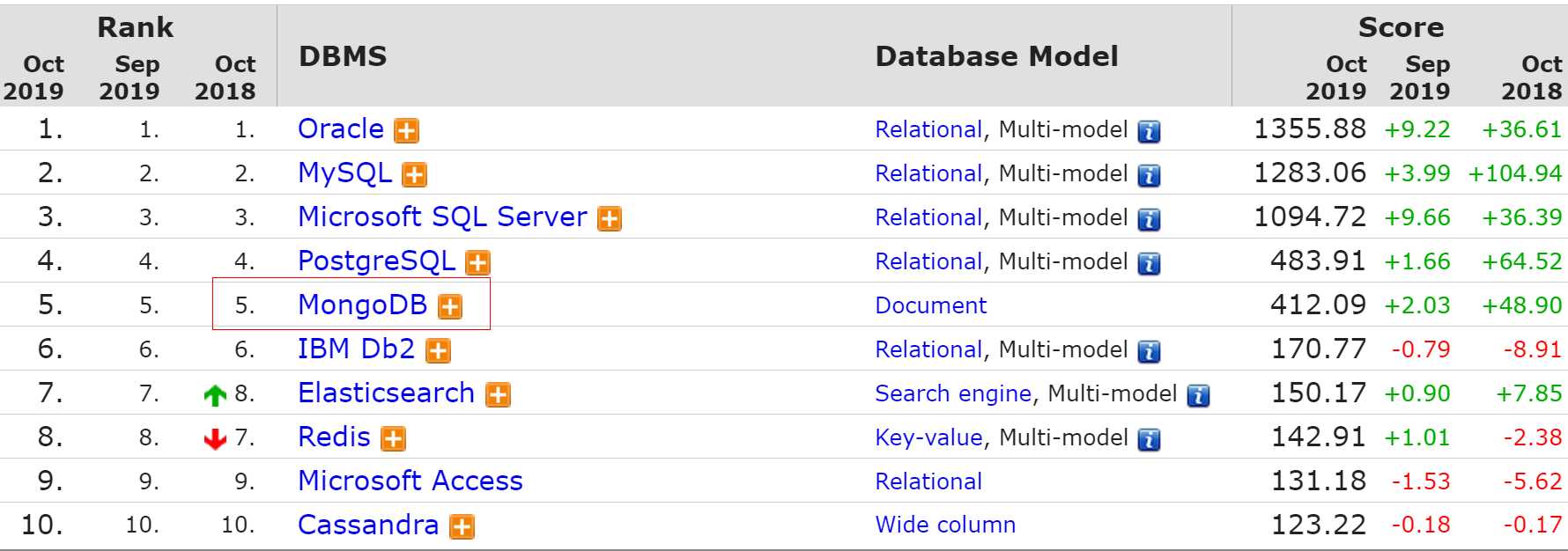
图-DBEngine排名
在全部的排名中,MongoDB 长期排在第5位(文档数据库排名第1位),同时也是最受欢迎的 NoSQL 数据库。
另外,MongoDB 的社区一直比较活跃,加上商业上的驱动(MongoDB于2017年在纳斯达克上市),这些因素都推动了该开源数据库的发展。
如果对于 MongoDB的发展史感兴趣,可以参考下没有一个技术天生完美,MongoDB 十年发展全纪录这篇文章。
MongoDB 数据库的一些特性:
假定你是初次了解 MongoDB,下面的内容将能帮助你对该数据库技术的全貌产生一定的了解。
数据结构对于一个软件来说是至关重要的,MongoDB 在概念模型上参考了 SQL数据库,但并非完全相同。
关于这点,也有人说,MongoDB 是 NoSQL中最像SQL的数据库..
如下表所示:
| SQL概念 | MongoDB概念 |
|---|---|
| database | database |
| table | collection |
| row | document |
| column | field |
另外,SQL 还有一些其他的概念,对应关系如下:
| SQL概念 | MongoDB概念 |
|---|---|
| primary key | _id |
| foreign key | reference |
| view | view |
| index | index |
| join | $lookup |
| transaction | trasaction |
| group by | aggregation |
MongoDB 文档可以使用 Javascript 对象表示,从格式上讲,是基于 JSON 的。
一个典型的文档如下:
{
"_id": 1,
"name" : { "first" : "John", "last" : "Backus" },
"contribs" : [ "Fortran", "ALGOL", "Backus-Naur Form", "FP" ],
"awards" : [
{
"award" : "W.W. McDowell Award",
"year" : 1967,
"by" : "IEEE Computer Society"
}, {
"award" : "Draper Prize",
"year" : 1993,
"by" : "National Academy of Engineering"
}
]
}曾经,JSON 的出现及流行让 Web 2.0 的数据传输变得非常简单,所以使用 JSON 语法是非常容易让开发者接受的。
但是 JSON 也有自己的短板,比如无法支持像日期这样的特定数据类型,因此 MongoDB 实际上使用的是一种扩展式的JSON,叫 BSON(Binary JSON)。
BSON 所支持的数据类型包括:
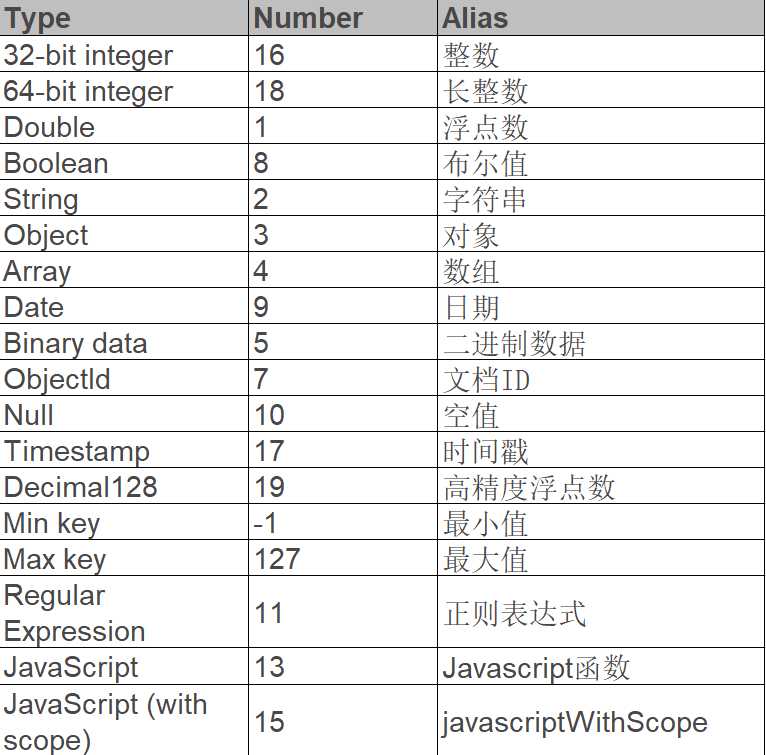
图-BSON类型
在单机时代,大多数应用可以使用数据库自增式ID 来作为主键。 传统的 RDBMS 也都支持这种方式,比如 mysql 可以通过声明 auto_increment来实现自增的主键。 但一旦数据实现了分布式存储,这种方式就不再适用了,原因就在于无法保证多个节点上的主键不出现重复。
为了实现分布式数据ID的唯一性保证,应用开发者提出了自己的方案,而大多数方案中都会将ID分段生成,如著名的 snowflake 算法中就同时使用了时间戳、机器号、进程号以及随机数来保证唯一性。
MongoDB 采用 ObjectId 来表示主键的类型,数据库中每个文档都拥有一个_id 字段表示主键。
_id 的生成规则如下:
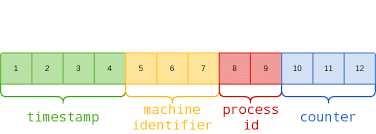
图-ObjecteID
其中包括:
值得一提的是 _id 的生成实质上是由客户端(Driver)生成的,这样可以获得更好的随机性,同时降低服务端的负载。
当然服务端也会检测写入的文档是否包含_id 字段,如果没有就生成一个。
除了文档模型本身,对于数据的操作命令也是基于JSON/BSON 格式的语法。
比如插入文档的操作:
db.book.insert(
{
title: "My first blog post",
published: new Date(),
tags: [ "NoSQL", "MongoDB" ],
type: "Work",
author : "James",
viewCount: 25,
commentCount: 2
}
)
执行文档查找:
db.book.find({author : "James"})更新文档的命令:
db.book.update(
{"_id" : ObjectId("5c61301c15338f68639e6802")},
{"$inc": {"viewCount": 3} }
)删除文档的命令:
db.book.remove({"_id":
ObjectId("5c612b2f15338f68639e67d5")})在传统的SQL语法中,可以限定返回的字段,MongoDB可以使用Projection来表示:
db.book.find({"author": "James"},
{"_id": 1, "title": 1, "author": 1})实现简单的分页查询:
db.book.find({})
.sort({"viewCount" : -1})
.skip(10).limit(5)这种基于BSON/JSON 的语法格式并不复杂,它的表达能力或许要比SQL更加强大。
与 MongoDB 做法类似的还有 ElasticSearch,后者是搜索数据库的佼佼者。
关于文档操作与 SQL方式完整的对比,官方的文档描述得比较详细:
https://docs.mongodb.com/manual/reference/sql-comparison/
那么,一个有趣的问题是 MongoDB 能不能用 SQL进行查询?
当然是可以!
但需要注意这些功能并不是 MongoDB 原生自带的,而需要借由第三方工具平台实现:
无疑,索引是一个数据库的关键能力,MongoDB 支持非常丰富的索引类型。
利用这些索引,可以实现快速的数据查找,而索引的类型和特性则是针对不同的应用场景设计的。
索引的技术实现依赖于底层的存储引擎,在当前的版本中 MongoDB 使用 wiredTiger 作为默认的引擎。
在索引的实现上使用了 B+树的结构,这与其他的传统数据库并没有什么不同。
所以这是个好消息,大部分基于SQL数据库的一些索引调优技巧在 MongoDB 上仍然是可行的。
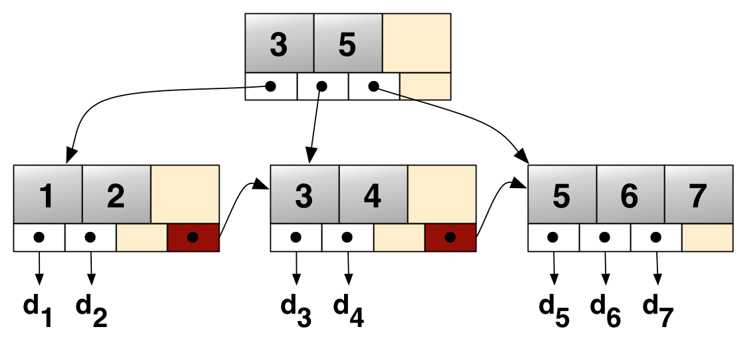
图-B+树
使用 ensureIndexes 可以为集合声明一个普通的索引:
db.book.ensureIndex({author: 1})author后面的数字 1 代表升序,如果是降序则是 -1
实现复合式(compound)的索引,如下:
db.book.ensureIndex({type: 1, published: 1})只有对于复合式索引时,索引键的顺序才变得有意义
如果索引的字段是数组类型,该索引就自动成为数组(multikey)索引:
db.book.ensureIndex({tags: 1})MongoDB 可以在复合索引上包含数组的字段,但最多只能包含一个
在声明索引时,还可以通过一些参数化选项来为索引赋予一定的特性,包括:
除了普通索引之外,MongoDB 支持的类型还包括:
使用 explain() 命令可以用于查询计划分析,进一步评估索引的效果。
如下:
> db.test.explain().find( { a : 5 } )
{
"queryPlanner" : {
...
"winningPlan" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"a" : 5
},
"indexName" : "a_1",
"isMultiKey" : false,
"direction" : "forward",
"indexBounds" : {"a" : ["[5.0, 5.0]"]}
}
}},
...
}
从结果 winningPlan 中可以看出执行计划是否高效,比如:
关于 explain 的结果说明,可以进一步参考文档:
https://docs.mongodb.com/manual/reference/explain-results/index.html
在大数据领域常常提到的4V特征中,Volume(数据量大)是首当其冲被提及的。
由于单机垂直扩展能力的局限,水平扩展的方式则显得更加的靠谱。 MongoDB 自带了这种能力,可以将数据存储到多个机器上以提供更大的容量和负载能力。
此外,同时为了保证数据的高可用,MongoDB 采用副本集的方式来实现数据复制。
一个典型的MongoDB集群架构会同时采用分片+副本集的方式,如下图:
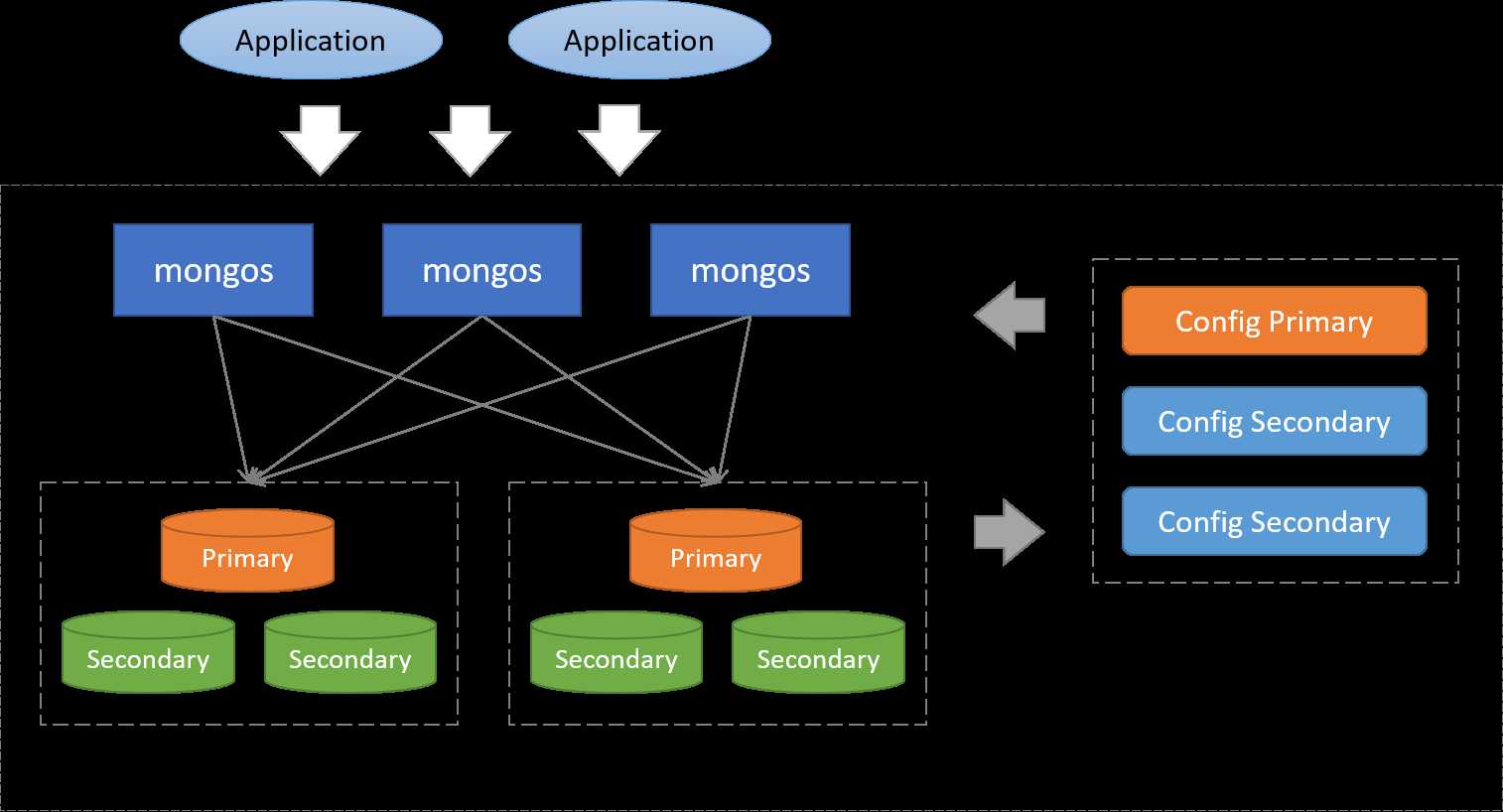
图-MongoDB 分片集群(Shard Cluster)
架构说明
数据分片(Shards)
分片用于存储真正的集群数据,可以是一个单独的 Mongod实例,也可以是一个副本集。 生产环境下Shard一般是一个 Replica Set,以防止该数据片的单点故障。
对于分片集合(sharded collection)来说,每个分片上都存储了集合的一部分数据(按照分片键切分),如果集合没有分片,那么该集合的数据都存储在数据库的 Primary Shard中。
配置服务器(Config Servers)
保存集群的元数据(metadata),包含各个Shard的路由规则,配置服务器由一个副本集(ReplicaSet)组成。
查询路由(Query Routers)
Mongos是 Sharded Cluster 的访问入口,其本身并不持久化数据 。Mongos启动后,会从 Config Server 加载元数据,开始提供服务,并将用户的请求正确路由到对应的Shard。
Sharding 集群可以部署多个 Mongos 以分担客户端请求的压力。
下面的几个细节,对于理解和应用 MongoDB 的分片机制比较重要,所以有必要提及一下:
1. 数据如何切分
首先,基于分片切分后的数据块称为 chunk,一个分片后的集合会包含多个 chunk,每个 chunk 位于哪个分片(Shard) 则记录在 Config Server(配置服务器)上。
Mongos 在操作分片集合时,会自动根据分片键找到对应的 chunk,并向该 chunk 所在的分片发起操作请求。
数据是根据分片策略来进行切分的,而分片策略则由 分片键(ShardKey)+分片算法(ShardStrategy)组成。
MongoDB 支持两种分片算法:
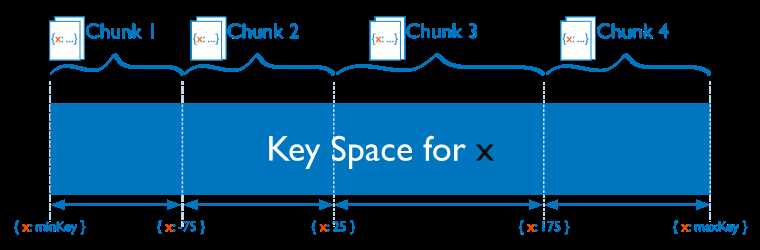
如上图所示,假设集合根据x字段来分片,x的取值范围为[minKey, maxKey](x为整型,这里的minKey、maxKey为整型的最小值和最大值),将整个取值范围划分为多个chunk,每个chunk(默认配置为64MB)包含其中一小段的数据:
如Chunk1包含x的取值在[minKey, -75)的所有文档,而Chunk2包含x取值在[-75, 25)之间的所有文档...
范围分片能很好的满足范围查询的需求,比如想查询x的值在[-30, 10]之间的所有文档,这时 Mongos 直接能将请求路由到 Chunk2,就能查询出所有符合条件的文档。 范围分片的缺点在于,如果 ShardKey 有明显递增(或者递减)趋势,则新插入的文档多会分布到同一个chunk,无法扩展写的能力,比如使用_id作为 ShardKey,而MongoDB自动生成的id高位是时间戳,是持续递增的。
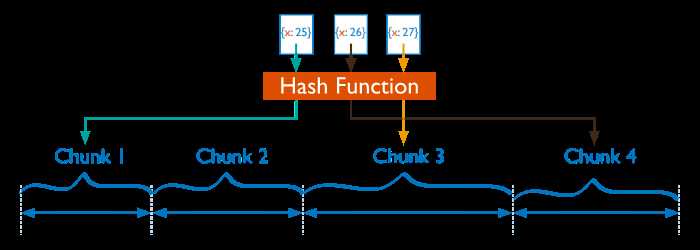
Hash分片是根据用户的 ShardKey 先计算出hash值(64bit整型),再根据hash值按照范围分片的策略将文档分布到不同的 chunk。
由于 hash值的计算是随机的,因此 Hash 分片具有很好的离散性,可以将数据随机分发到不同的 chunk 上。 Hash 分片可以充分的扩展写能力,弥补了范围分片的不足,但不能高效的服务范围查询,所有的范围查询要查询多个 chunk 才能找出满足条件的文档。
2. 如何保证均衡
如前面的说明中,数据是分布在不同的 chunk上的,而 chunk 则会分配到不同的分片上,那么如何保证分片上的 数据(chunk) 是均衡的呢?
在真实的场景中,会存在下面两种情况:
A. 全预分配,chunk 的数量和 shard 都是预先定义好的,比如 10个shard,存储1000个chunk,那么每个shard 分别拥有100个chunk。
此时集群已经是均衡的状态(这里假定)
B. 非预分配,这种情况则比较复杂,一般当一个 chunk 太大时会产生分裂(split),不断分裂的结果会导致不均衡;或者动态扩容增加分片时,也会出现不均衡的状态。 这种不均衡的状态由集群均衡器进行检测,一旦发现了不均衡则执行 chunk数据的搬迁达到均衡。
MongoDB 的数据均衡器运行于 Primary Config Server(配置服务器的主节点)上,而该节点也同时会控制 Chunk 数据的搬迁流程。
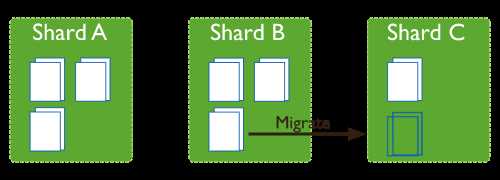
图-数据自动均衡
对于数据的不均衡是根据两个分片上的 Chunk 个数差异来判定的,阈值对应表如下:
| Number of Chunks | Migration Threshold |
|---|---|
| Fewer than 20 | 2 |
| 20-79 | 4 |
| 80 and greater | 8 |
MongoDB 的数据迁移对集群性能存在一定影响,这点无法避免,目前的规避手段只能是将均衡窗口对齐到业务闲时段。
3. 应用高可用
应用节点可以通过同时连接多个 Mongos 来实现高可用,如下:
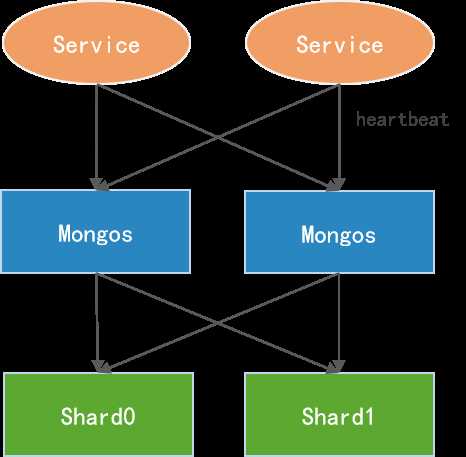
图- mongos 高可用
当然,连接高可用的功能是由 Driver 实现的。
副本集又是另一个话题,实质上除了前面架构图所体现的,副本集可以作为 Shard Cluster 中的一个Shard(片)之外,对于规模较小的业务来说,也可以使用一个单副本集的方式进行部署。
MongoDB 的副本集采取了一主多从的结构,即一个Primary Node + N* Secondary Node的方式,数据从主节点写入,并复制到多个备节点。
典型的架构如下:
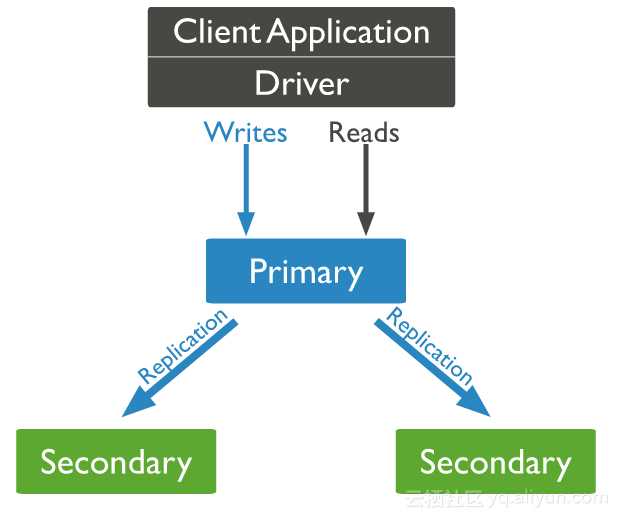
利用副本集,我们可以实现::
请注意,读写分离只能增加集群"读"的能力,对于写负载非常高的情况却无能为力。
对此需求,使用分片集群并增加分片,或者提升数据库节点的磁盘IO、CPU能力可以取得一定效果。
选举
MongoDB 副本集通过 Raft 算法来完成主节点的选举,这个环节在初始化的时候会自动完成,如下面的命令:
config = {
_id : "my_replica_set",
members : [
{_id : 0, host : "rs1.example.net:27017"},
{_id : 1, host : "rs2.example.net:27017"},
{_id : 2, host : "rs3.example.net:27017"},
]
}
rs.initiate(config)initiate 命令用于实现副本集的初始化,在选举完成后,通过 isMaster()命令就可以看到选举的结果:
> db.isMaster()
{
"hosts" : [
"192.168.100.1:27030",
"192.168.100.2:27030",
"192.168.100.3:27030"
],
"setName" : "myReplSet",
"setVersion" : 1,
"ismaster" : true,
"secondary" : false,
"primary" : "192.168.100.1:27030",
"me" : "192.168.100.1:27030",
"electionId" : ObjectId("7fffffff0000000000000001"),
"ok" : 1
}受 Raft算法的影响,主节点的选举需要满足"大多数"原则,可以参考下表:
| 投票成员数 | 大多数 |
|---|---|
| 1 | 1 |
| 2 | 2 |
| 3 | 2 |
| 4 | 3 |
| 5 | 3 |
因此,为了避免出现平票的情况,副本集的部署一般采用是基数个节点,比如3个,正所谓三人行必有我师..
心跳
在高可用的实现机制中,心跳(heartbeat)是非常关键的,判断一个节点是否宕机就取决于这个节点的心跳是否还是正常的。
副本集中的每个节点上都会定时向其他节点发送心跳,以此来感知其他节点的变化,比如是否失效、或者角色发生了变化。
利用心跳,MongoDB 副本集实现了自动故障转移的功能,如下图:
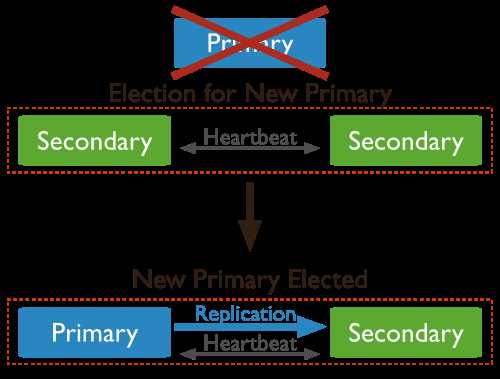
默认情况下,节点会每2秒向其他节点发出心跳,这其中包括了主节点。 如果备节点在10秒内没有收到主节点的响应就会主动发起选举。
此时新一轮选举开始,新的主节点会产生并接管原来主节点的业务。 整个过程对于上层是透明的,应用并不需要感知,因为 Mongos 会自动发现这些变化。
如果应用仅仅使用了单个副本集,那么就会由 Driver 层来自动完成处理。
复制
主节点和备节点的数据是通过日志(oplog)复制来实现的,这很类似于 mysql 的 binlog。
在每一个副本集的节点中,都会存在一个名为local.oplog.rs的特殊集合。 当 Primary 上的写操作完成后,会向该集合中写入一条oplog,
而 Secondary 则持续从 Primary 拉取新的 oplog 并在本地进行回放以达到同步的目的。
下面,看看一条 oplog 的具体形式:
{
"ts" : Timestamp(1446011584, 2),
"h" : NumberLong("1687359108795812092"),
"v" : 2,
"op" : "i",
"ns" : "test.nosql",
"o" : { "_id" : ObjectId("563062c0b085733f34ab4129"), "name" : "mongodb", "score" : "100" }
}其中的一些关键字段有:
MongoDB 对于 oplog 的设计是比较仔细的,比如:
有兴趣的读者,可以参考官方文档:
https://docs.mongodb.com/manual/core/replica-set-oplog/index.html
一直以来,"不支持事务" 是 MongoDB 一直被诟病的问题,当然也可以说这是 NoSQL 数据库的一种权衡(放弃事务,追求高性能、高可扩展)
但实质上,MongoDB 很早就有事务的概念,但是这个事务只能是针对单文档的,即单个文档的操作是有原子性保证的。
在4.0 版本之后,MongoDB 开始支持多文档的事务:
在事务的隔离性上,MongoDB 支持快照(snapshot)的隔离级别,可以避免脏读、不可重复读和幻读。
尽管有了真正意义上的事务功能,但多文档事务对于性能有一定的影响,应用应该在充分评估后再做选用。
一致性是一个复杂的话题,而一致性更多从应用角度上提出的,比如:
向系统写入一条数据,应该能够马上读到写入的这个数据。在分布式架构的CAP理论以及许多延续的观点中提到,由于网络分区的存在,要求系统在一致性和可用性之间做出选择,而不能两者兼得。
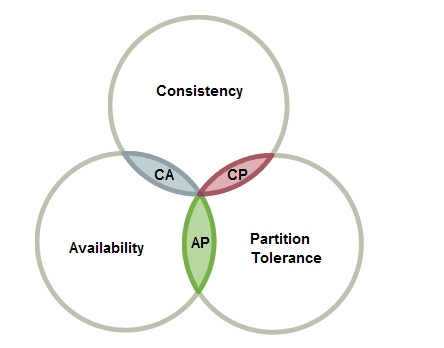
图 -CAP理论
在 MongoDB 中,这个选择是可以由开发者来定的。 MongoDB 允许客户端为其操作设定一定的级别或者偏好,包括:
使用不同的设定将会产生对于C(一致性)、A(可用性)的不同的抉择,比如:
关于这种权衡的讨论会一直存在,而 MongoDB 除了提供多样化的选择之外,其主要是通过复制、基于心跳的自动failover等机制来降低系统发生故障时产生的影响,从而提升整体的可用性。
本文主要揭示了 MongoDB 多个方面的细节,同时在使用体验上也借助 SQL 的概念做了一些对比。
从笔者的角度看,MongoDB 的发展性是很强的,其灵活快速的开发模式、天生自带分布式等能力弥补了传统型SQL数据库的缺陷。当然,目前的 NewSQL 本质上也貌似在以"模仿的方式"弥补这些缺陷。
希望本文的内容对你能有些参考。
标签:form 趋势 本地 两种 清理 数据查询 删除 控制 key
原文地址:https://www.cnblogs.com/littleatp/p/11675233.html