标签:blog com rabl -- 系列化 span tput 工具 获取
Hadoop将很多Writable类归入org.apache.hadoop.io包中,在这些类中,比较重要的有Java基本类、Text、Writable集合、ObjectWritable等,重点介绍Java基本类
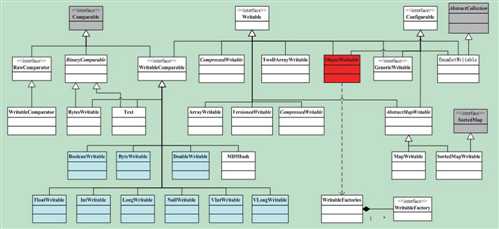
目前Java基本类型对应的Writable封装如下表所示。所有这些Writable类都继承自WritableComparable。也就是说,它们是可比较的。同时,它们都有get()和set()方法,用于获得和设置封装的值。
Java基本类型对应的Writable封装
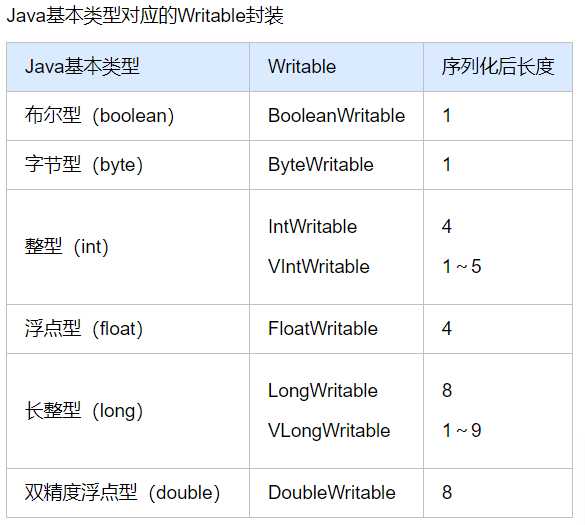
在表中,对整型(int和long)进行编码的时候,有固定长度格式(IntWritable和LongWritable)和可变长度格式(VIntWritable和VLongWritable)两种选择。固定长度格式的整型,序列化后的数据是定长的,而可变长度格式则使用一种比较灵活的编码方式,对于数值比较小的整型,它们往往比较节省空间。同时,由于VIntWritable和VLongWritable的编码规则是一样的,所以VIntWritable的输出可以用VLongWritable读入。下面以VIntWritable为例,说明Writable的Java基本类封装实现。代码如下:
public class VIntWritable implements WritableComparable { private int value; …… // 设置VIntWritable的值 public void set(int value) { this.value = value; } // 获取VIntWritable的值 public int get() { return value; } public void readFields(DataInput in) throws IOException { value = WritableUtils.readVInt(in); } public void write(DataOutput out) throws IOException { WritableUtils.writeVInt(out, value); } …… }
首先,每个Java基本类型的Writable封装,其类的内部都包含一个对应基本类型的成员变量value,get()和set()方法就是用来对该变量进行取值/赋值操作的。而Writable接口要求的readFields()和write()方法,VIntWritable则是通过调用Writable工具类中提供的readVInt()和writeVInt()读/写数据。方法readVInt()和writeVInt()的实现也只是简单调用了readVLong()和writeVLong(),所以,通过writeVInt()写的数据自然可以通过readVLong()读入。
writeVLong ()方法实现了对整型数值的变长编码,它的编码规则如下:
如果输入的整数大于或等于–112同时小于或等于127,那么编码需要1字节;否则,序列化结果的第一个字节,保存了输入整数的符号和后续编码的字节数。符号和后续字节数依据下面的编码规则(又一个规则):
如果是正数,则编码值范围落在–113和–120间(闭区间),后续字节数可以通过–(v+112)计算。
如果是负数,则编码值范围落在–121和–128间(闭区间),后续字节数可以通过–(v+120)计算。
后续编码将高位在前,写入输入的整数(除去前面全0字节)。代码如下:
public final class WritableUtils { public stati cvoid writeVInt(DataOutput stream, int i) throws IOException { writeVLong(stream, i); } /** * @param stream保存系列化结果输出流 * @param i 被序列化的整数 * @throws java.io.IOException */ public static void writeVLong(DataOutput stream, long i) throws…… { //处于[-112, 127]的整数 if (i >= -112 && i <= 127) { stream.writeByte((byte)i); return; } //计算情况2的第一个字节 int len = -112; if (i < 0) { i ^= -1L; len = -120; } long tmp = i; while (tmp != 0) { tmp = tmp >> 8; len--; } stream.writeByte((byte)len); len = (len < -120) ? -(len + 120) : -(len + 112); //输出后续字节 for (int idx = len; idx != 0; idx--) { int shiftbits = (idx - 1) * 8; long mask = 0xFFL << shiftbits; stream.writeByte((byte)((i & mask) >> shiftbits)); } } }
原文链接:https://www.cnblogs.com/wuyudong/p/hadoop-writable.html
标签:blog com rabl -- 系列化 span tput 工具 获取
原文地址:https://www.cnblogs.com/isme-zjh/p/11676930.html