标签:user 表达式 txt str nbsp text save rgs headers
**因为糗事百科的URL改变,正则表达式也发生了改变,导致了网上许多的代码不能使用,所以写下了这一篇博客,希望对大家有所帮助,谢谢!**
废话不多说,直接上代码。
为了方便提取数据,我用的是beautifulsoup库和requests
``## 具体代码如下
```
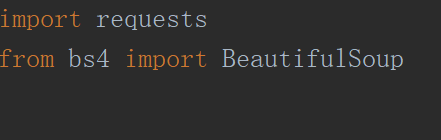
import requests
from bs4 import BeautifulSoup
def download_page(url):
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0"}
r = requests.get(url, headers=headers)
return r.text
def get_content(html):
soup = BeautifulSoup(html, ‘html.parser‘)
con = soup.find(id=‘main‘)
con_list = con.find_all(‘div‘, class_="cat_llb")
for i in con_list:
author = i.find(‘h3‘).string # 获取名字
content = i.find(‘div‘, id="endtext").get_text() # 获取内容
save_txt(author, content)
def save_txt(*args):
for i in args:
with open(‘qiubai.txt‘, ‘a‘, encoding=‘utf-8‘) as f:
f.write(i+‘\n‘+‘\n‘)
# def save_txt(str):
# for i in str:
#
# with open(‘qiubai.txt‘, ‘a‘, encoding=‘utf-8‘) as f:
# f.write(str + ‘\n‘)
# f.write(i)
def main():
# 可以构造如下 url,
for i in range(1, 20):
url = ‘http://www.lovehhy.net/Joke/Detail/QSBK/{}‘.format(i)
html = download_page(url)
get_content(html)
if __name__ == ‘__main__‘:
main()
```
哦 ,对了,新网站的地址是http://www.lovehhy.net/Joke/Detail/QSBK/
有什么不懂得欢迎留言
标签:user 表达式 txt str nbsp text save rgs headers
原文地址:https://www.cnblogs.com/chx123/p/11692125.html