标签:模式 show 垃圾回收 sequence ima 执行 mamicode 结果 机制
计算机只能识别二进制;
1、二进制由0和1组成的数字,eg:00001111
2、计算机是基于电工作的,电的特性即高低电平。
高电平对应数字1,低电平对应数字0
则人类的字符到计算机中的数字,必须经历一个过程:
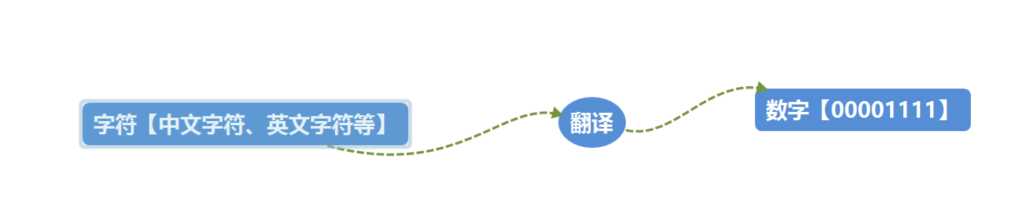
翻译的过程中必须参照一个特定的标准,该标准称之为字符编码表,该表上存放的就是字符和数字一一对应的关系
字符编码中的编码指的是翻译或者转换的意思,即将人能理解的字符翻译成计算机能识别的数字
1、大小写英文字母、数字和一些符号(记录128个英文字符对应的编码)--》 用8个位表示文字,最高位一定为0,低7位表示数值(0-127共128个) 2、一个英文字符对应1Bytes,1Bytes=8bit; 8bit最多包含256个数字,可以对应256个字符,足够表示所有英文字符
1、只有英文字符、符号、中文字符与数字的一一对应关系 2、一个英文字符对应1Bytes 一个中文字符对应2Bytes
1、(记录65536个文字(包含英文128个ascii编码))
2、用16个位组成的(0-65535共65536个)0x0000-0xffff
1、unicode缺点: ASCII编码的A用Unicode编码, A的Unicode编码是00000000 01000001。 用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。 2、UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节

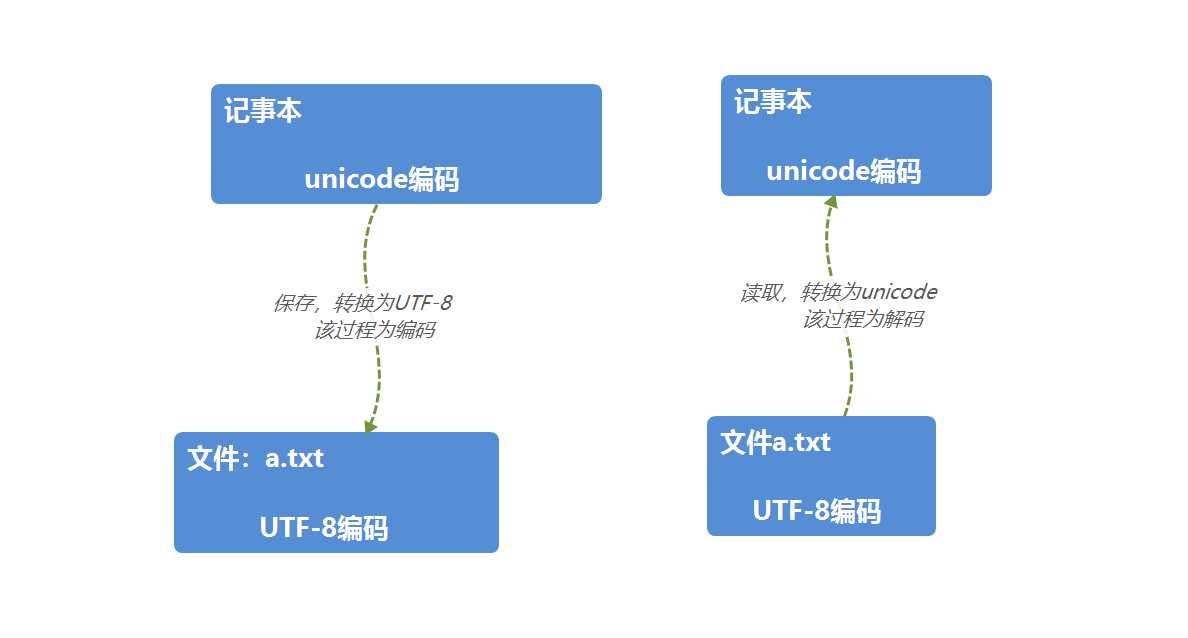
1、字符转换成内存中的unicode,以及由unicode转换成其他编码的过程,都称为编码encode
2、由内存中的unicode转换成字符,以及由其他编码转换成unicode过程,都成为编码decode
计算机系统通用的字符编码工作方式: 在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。 用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件
打开文件的模式有
”+“ 表示同时读写文件 r+ 、w+、x+、a+
”b“表示以字节的方式操作rb 、rb+、wb 、wb+、xb 、xb+、ab、ab+
1、pycharm 创建a.txt文件,设置编码为utf-8
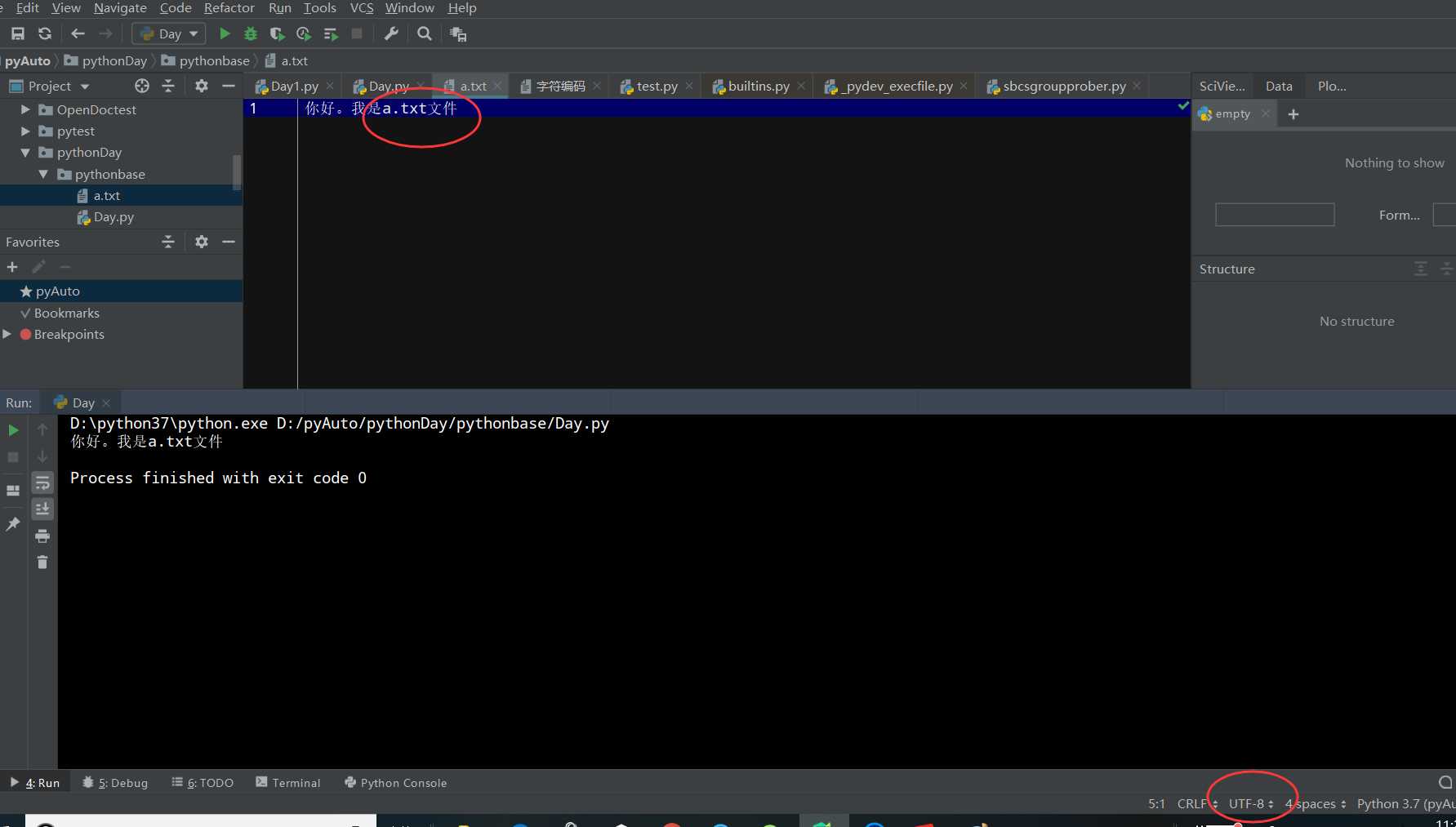
2、创建 Day.py文件 【该文件和a.txt文件在相同的文件目录下】
#f=open(‘a.txt‘,‘r‘) #默认打开模式r #没有指定编码,则会报错 UnicodeDecodeError: ‘gbk‘ codec can‘t decode byte 0x80 in position 28: illegal multibyte sequence #因为open()会读取系统默认的编码方式;本系统的默认编码方式为gbk;而a.txt的编码是utf-8 # 打开文件 f = open(‘a.txt‘,‘r‘,encoding=‘utf-8‘) #调用文件对象下的读方式, data=f.read() print(data) #向操作系统发起关闭文件的请求,回收系统资源 f.close()
open() 方法用于打开一个文件,并返回文件对象,在对文件进行处理过程都需要使用到这个函数,如果该文件无法被打开,会抛出 OSError。
注意:使用 open() 方法一定要保证关闭文件对象,即调用 close() 方法。
open() 函数常用形式是接收两个参数:文件名(file)和模式(mode)。
open(file, mode=‘r‘, buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
mode 参数有:t、x、b、+、U(python 3 不支持)、r、rb、w、wb、w+、wb+、a、ab、a+、ab+
#测试点 mode 缺失;则默认只读模式r # 打开文件 f = open(‘a.txt‘,encoding=‘utf-8‘) #调用文件对象下的读方式, data=f.read() print(data) #向操作系统发起关闭文件的请求,回收系统资源 f.close() """ 执行结果 你好。我是a.txt文件 """
判断是否是读模式,mode包含读模式, 则返回True;
#mode=r f = open(‘a.txt‘,encoding=‘utf-8‘) print(f.readable()) #输出 True f.close() #mode=r+ 读写 f = open(‘a.txt‘,‘r+‘,encoding=‘utf-8‘) print(f.readable()) #输出 True f.close() #mode=w 写 f = open(‘a.txt‘,‘w‘,encoding=‘utf-8‘) print(f.readable()) #输出 True f.close() #mode=w+ f = open(‘a.txt‘,‘w+‘,encoding=‘utf-8‘) print(f.readable()) #输出 True f.close() #mode=+ f = open(‘a.txt‘,‘a+‘,encoding=‘utf-8‘) print(f.readable()) #输出 True f.close() """ 执行结果 True True True False True True
file.readline() 读取整行,包括 "\n" 字符
file.readlines() 读取所有行并返回列表,若给定sizeint>0,返回总和大约为sizeint字节的行, 实际读取值可能比 sizeint 较大, 因为需要填充缓冲区。
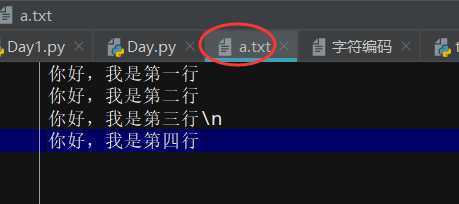
#file.readline() 一次读一行 f = open(‘a.txt‘,encoding=‘utf-8‘) print("第1行:",f.readline()) print("第2行:",f.readline()) print("第3行:",f.readline()) print("第4行:",f.readline()) print("第5行,超过a.txt文件的行数:",f.readline()) print("第6行,超过a.txt文件的行数:",f.readline()) f.close() """ 执行结果 第1行: 你好,我是第一行 第2行: 你好,我是第二行 第3行: 你好,我是第三行\n 第4行: 你好,我是第四行 第5行,超过a.txt文件的行数: 第6行,超过a.txt文件的行数: """ #file.readline() 一次读一行 ;显示结果去掉空行 f = open(‘a.txt‘,encoding=‘utf-8‘) print(‘读取第1行:‘,f.readline(),end=‘‘) print(‘读取第2行:‘,f.readline(),end=‘‘) print(‘读取第3行:‘,f.readline(),end=‘‘) print(‘读取第4行:‘,f.readline(),end=‘‘) f.close() """ 执行结果【去除空行】 读取第1行: 你好,我是第一行 读取第2行: 你好,我是第二行 读取第3行: 你好,我是第三行\n 读取第4行: 你好,我是第四行 """ #先用file.read()读取,再用file.readline() #文件光标的问题 f = open(‘a.txt‘,encoding=‘utf-8‘) data=f.read() print(data) #f.read() ,则光标已移到到文件末尾 print(‘读取第1行:‘,f.readline(),end=‘‘) #再次读取的时候,光标还是显示在文件末尾,读取为空 f.close() """ 执行结果: 你好,我是第一行 你好,我是第二行 你好,我是第三行\n 你好,我是第四行 读取第1行: """ #file.readlines() 读取全部 f = open(‘a.txt‘,encoding=‘utf-8‘) print(f.readlines()) f.close() """ 执行结果 好,我是第一行\n‘, ‘你好,我是第二行\n‘, ‘你好,我是第三行\\n\n‘, ‘你好,我是第四行‘] """
文件内容只能字符串,只能写入字符串;其他类型会报错
w 打开一个文件只用于写入。 1、如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。【即文件指针跑到文件开头】 2、如果该文件不存在,创建新文件。
例1、f.write() 将字符串写入文件,返回的是写入的字符长度。
f = open(‘a.txt‘,‘w‘,encoding=‘utf-8‘) f.write(‘我是一行‘) f.write(‘我是第二行‘) f.close()
执行结果如下
我是一行我是第二行
例2、f.write() 换行输入
f = open(‘a.txt‘,‘w‘,encoding=‘utf-8‘) f.write(‘我是一行\n‘) f.write(‘我是第二行\n‘) f.write(‘我是第3行\n444\n555555\t666666‘) f.close()
执行结果如下
我是一行 我是第二行 我是第3行 444 555555 666666
例3、file.fwritable()
#mode=w file.fwritable() 为True f = open(‘a.txt‘,‘w‘,encoding=‘utf-8‘) print(f.writable()) f.close() """ 执行结果 True """ #mode= r file.fwritable() 为False f = open(‘a.txt‘,‘r‘,encoding=‘utf-8‘) print(f.writable()) f.close() """ 执行结果 False """
例4、file.writelines() 向文件写入一个序列字符串列表,如果需要换行则要自己加入每行的换行符
f = open(‘a.txt‘,‘w‘,encoding=‘utf-8‘) f.write(‘我是一行\n‘) f.write(‘我是第二行\n‘) f.write(‘我是第3行\n444\n555555\t666666‘) f.writelines([‘77777777‘,‘8888888888\n‘,‘你哈哈哈哈哈哈哈哈\n‘]) f.close()
执行结果如下
我是一行 我是第二行 我是第3行 444 555555 666666777777778888888888 你哈哈哈哈哈哈哈哈
a 打开一个文件用于追加。 1、如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。 2、如果该文件不存在,创建新文件进行写入。
例1:

我是一行 我是第二行 我是第3行 444 555555 666666777777778888888888 你哈哈哈哈哈哈哈哈
f = open(‘a.txt‘,‘a‘,encoding=‘utf-8‘) f.write(‘写到文件末尾‘) f.close()
我是一行 我是第二行 我是第3行 444 555555 666666777777778888888888 你哈哈哈哈哈哈哈哈 写到文件末尾
例2:r+ 文件指针将会放在文件的开头
我是第一行
我是第二行
我是第三行
f = open(‘a.txt‘,‘r+‘,encoding=‘utf-8‘) #data=f.read() #print(data) f.write(‘写到文件末尾\n‘) #会覆盖第一行内容 f.close()
写到文件末尾
是第二行
我是第三行
例3:去掉文件的最后两行的内容
f = open(‘a.txt‘,‘r+‘,encoding=‘UTF-8‘) data=f.readlines() #读取文件内容 返回字符串列表 print(data) f.close() del_f = open(‘a.txt‘,‘w‘,encoding=‘UTF-8‘) myslice=slice(0,-2) #切片,去掉最后两行 print(data[myslice]) for item in data[myslice]: del_f.write(item) #重新写入 f.close()
操作完毕文件后,一定要记得关闭文件 file.close()
#执行完子程序代码块后,会自动执行f.close() with open(‘a.txt‘,‘a‘,encoding=‘utf-8‘) as f: f.write(‘--------‘) #从a.txt文件复制内容后,创建一个新的aa.txt文件并写入a.txt文件内容,并去掉最后两行内容 #with 打开多个文件,用逗号隔开即可 with open(‘a.txt‘,‘r‘,encoding=‘utf-8‘) as f,open(‘aa.txt‘,‘w‘,encoding=‘utf-8‘) as def_f: data = f.readlines() myslice = slice(0, -2) for item in data[myslice]: def_f.write(item)
打开文件包含两部分资源:应用程序的变量f和操作系统打开的文件,在操作完毕一个文件时,必须把与该文件的这两部分资源全部回收,回收方法为:
f.close() #回收操作系统打开的文件资源 del f #回收应用程序级的变量
注意 1、del f 一定要发送在f.close()之后,否则就会导致操作系统打开的文件无法关闭,白白占用资源 2、python自动的垃圾回收机制,则无需考虑del f 3、但是要记住 关闭文件 f.close
注意 1、b模式下不能指定编码,指定后会报错ValueError: binary mode doesn‘t take an encoding argument 2、读写文件都是以bytes/二进制为单位的 3、可以针对所有文件 4、不能单独使用,必须与r/w/a结合使用 5、纯文本文件方面,b模式需要手动编码与解码 6、针对非文本文件(图片、视频、音频等)。只能使用b模式
sss111
你好
哈哈哈
例1:b模式下读取a.txt文件
#b:读写都是以二进制为单位 with open(‘a.txt‘,‘rb‘) as f: data = f.read() print(type(data)) #输出的 <class ‘bytes‘> print(data)
执行结果如下
<class ‘bytes‘> b‘sss111\r\n\xe4\xbd\xa0\xe5\xa5\xbd\r\n\xe5\x93\x88\xe5\x93\x88\xe5\x93\x88‘
例2:要打印正常的显示字符
#字符串-- encode --->bytes #bytes----decode---->字符串 with open(‘a.txt‘,‘rb‘) as f: data = f.read() print(type(data)) #输出的 <class ‘bytes‘> print(data.decode(‘utf-8‘))
执行结果如下
<class ‘bytes‘> sss111 你好 哈哈哈
例3:写入中文字符报错的例子
#b 写入中文字符,没有进行编码会导致报错 with open(‘a.txt‘,‘wb‘) as f: ms = ‘hello‘ f.write(ms) #TypeError: a bytes-like object is required, not ‘str‘ 则会报错
例4:可以将中文字符正常写入
with open(‘a.txt‘,‘wb‘) as f: ms = ‘ddddd‘ res=ms.encode(‘utf-8‘) #将字符串转换成bytes类型 字符串-- encode --->bytes f.write(res) #在b模式下写入的只能时bytes类型
t(默认的):文本模式 1、t 模式均不能单独使用,需要与r、w、a之一结合使用 2、读写文件都是以字符串为单位 3、只能针对文本文件 4、必须指定encoding参数
with open(‘a.txt‘,‘rt‘,encoding=‘utf-8‘) as f: # data = f.read() # print(type(data)) #<class ‘str‘> # print(data) res = f.readlines() print(res) #错误的例子,写入必须是字符串 with open(‘aa.txt‘,‘wt‘,encoding=‘utf-8‘) as f: res =[‘ssssss呼呼呼呼\n‘, ‘文件末尾\n‘, ‘----------------\n‘, ‘花花花花\n‘, ‘撒打算按时‘] #f.write(res) #res 是一个列表 写入 报错TypeError: write() argument must be str, not list with open(‘aa.txt‘,‘wt‘,encoding=‘utf-8‘) as f: res = ‘你好‘ f.write(res) #注意:t模式只能用于操作文本文件,无论读写,都应该以字符串为单位,而存取硬盘本质都是二进制的形式。而指定t模式。内部帮我们做了编码与解码
标签:模式 show 垃圾回收 sequence ima 执行 mamicode 结果 机制
原文地址:https://www.cnblogs.com/sugh/p/11699427.html
