标签:base64 编码 解码
Base64不是什么新奇的算法了,不过如果你没从事过页面开发(或者说动态页面开发,尤其是邮箱服务),你都不怎么了解过,只是听起来很熟悉。
对于黑客来说,Base64与MD5算法有着同样的位置,因为电子邮箱(e-mail)正文就是base64编码的。
那么,我们就一起来深入的探讨一下这个东东吧。
对于一种算法,与其问“它是什么?”,不如问“它实现了什么?”
Base64实现了:将任意字节转为可读字符的编码。
我们知道,除了页面上的文本,计算机中的数据还有很多是不可见的。那么我们再扯一扯编码的问题吧。
通俗的说,编码就是给某个文字符号边上一个数字序号,计算机在现实这个文字符号(字符)的时候,根据这个序号到字库中查找对应的点阵或矢量数据,
在显示器上“画”出来。(关于点阵和矢量我们就不扯了,不然就真的太远了。)
起初的字符编码,没有把汉字、日文、朝鲜文和其他文字包括在内,只有26个英文字母的大小写和10个阿拉伯数字。加上一些控制字符和空格,用一个字节
就能够完全的编码了。(不要告诉我你不知道2的7次方和2的8次方是多少,一个技术人员为这样的问题困扰简直是一种耻辱。)
然而,世界上除了文字还有数据,比如图片、压缩文件、程序等等都是二进制文件,这些文件一样以字节为单位存储数据,这些字节往往不仅仅是2的7次方以内
的可显示的文字字符编码,还有可能是大于127(有符号数小于0)的字节,这些字节没办法用字符显示出来,Base64就是通过某种算法将他们显示出来。
*那么,Base64加密是安全的吗?
没有绝对安全的加密,Base64不是为了安全,而是为了显示。而且Base64是可逆的,也就是说,通过简单的解密就能得到原文。其实即便是不可逆的MD5算法,
也可以通过明文数据库找出可能的原文(睡到知道e10adc3949ba59abbe56e057f20f883e的原文就是123456)。
*那么,Base64是怎么实现的呢?
其实很简单,不过为了URL等特殊用处,Base64选择了以下64个字符作为密文显示,着64个字符都是可显示的,他们是:
ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/
如果密文有不属于他们的字符,那么不是Base64编码或者是山寨版的。
一眼看去就知道是26个字母大小写和数字,加上“+”“/”两个符号,“?*-”由于正则表达式的问题,没有选用,而空格和回车这些是不能显示的。
Base64处理的过程是,以3个字节为一组(3个字节就是24位嘛),每6位扩展成8位得到4个字节(就是32位):
11111111 11111111 11111111 -> 111111 111111 111111 111111 -> 00111111 00111111 00111111 00111111
那么,得到的每一个字节,最大也就是2的6次方。也许你说:哇,小于2的7次方,可以显示了。
其实不是,得到的这2的6次方式上面那一串字符的索引,也就是说每个字节的值只是代表它在密文表中的位置,比如
字符“a”的编码是97, 用16进制表示是0x61(VB表示为&H61),二进制:01100001,因为不足3位,补0得到 00011000 00010000 000……
前两个字节是十进制的24 和 16,那么对应那一串字符中的第24个字符和第16个字符为:YQ(索引从0开始算),那么单独“a”的Base64编码为
YQ==(不足3为的每个字符直接转为“=”),简单吧!
有了算法,解码的过程就各位聪明特达的程序员取思考思考吧,最后C/C++版的编码和解码代码贴上!
-
-
-
-
-
#include <stdio.h> //注意哦,VC中""是当前路径,<>是系统路径
-
#include <windows.h>
-
-
const char BASE_CODE[] = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";
-
-
-
int fnBase64Encode(char *lpString, char *lpBuffer, int sLen)
-
{ register int vLen = 0;
-
while(sLen > 0)
-
{ *lpBuffer++ = BASE_CODE[(lpString[0] >> 2 ) & 0x3F];
-
if(sLen > 2)
-
{ *lpBuffer++ = BASE_CODE[((lpString[0] & 3) << 4) | (lpString[1] >> 4)];
-
*lpBuffer++ = BASE_CODE[((lpString[1] & 0xF) << 2) | (lpString[2] >> 6)];
-
*lpBuffer++ = BASE_CODE[lpString[2] & 0x3F];
-
}else
-
{ switch(sLen)
-
{ case 1:
-
*lpBuffer ++ = BASE_CODE[(lpString[0] & 3) << 4 ];
-
*lpBuffer ++ = ‘=‘;
-
*lpBuffer ++ = ‘=‘;
-
break;
-
case 2:
-
*lpBuffer ++ = BASE_CODE[((lpString[0] & 3) << 4) | (lpString[1] >> 4)];
-
*lpBuffer ++ = BASE_CODE[((lpString[1] & 0x0F) << 2) | (lpString[2] >> 6)];
-
*lpBuffer ++ = ‘=‘;
-
break;
-
}
-
}
-
lpString += 3;
-
sLen -= 3;
-
vLen +=4;
-
}
-
*lpBuffer = 0;
-
return vLen;
-
}
-
-
-
inline char GetCharIndex(char c)
-
{ if((c >= ‘A‘) && (c <= ‘Z‘))
-
{ return c - ‘A‘;
-
}else if((c >= ‘a‘) && (c <= ‘z‘))
-
{ return c - ‘a‘ + 26;
-
}else if((c >= ‘0‘) && (c <= ‘9‘))
-
{ return c - ‘0‘ + 52;
-
}else if(c == ‘+‘)
-
{ return 62;
-
}else if(c == ‘/‘)
-
{ return 63;
-
}else if(c == ‘=‘)
-
{ return 0;
-
}
-
return 0;
-
}
-
-
-
int fnBase64Decode(char *lpString, char *lpSrc, int sLen)
-
{ static char lpCode[4];
-
register int vLen = 0;
-
if(sLen % 4)
-
{ lpString[0] = ‘\0‘;
-
return -1;
-
}
-
while(sLen > 2)
-
{ lpCode[0] = GetCharIndex(lpSrc[0]);
-
lpCode[1] = GetCharIndex(lpSrc[1]);
-
lpCode[2] = GetCharIndex(lpSrc[2]);
-
lpCode[3] = GetCharIndex(lpSrc[3]);
-
-
*lpString++ = (lpCode[0] << 2) | (lpCode[1] >> 4);
-
*lpString++ = (lpCode[1] << 4) | (lpCode[2] >> 2);
-
*lpString++ = (lpCode[2] << 6) | (lpCode[3]);
-
-
lpSrc += 4;
-
sLen -= 4;
-
vLen += 3;
-
}
-
return vLen;
-
}
-
-
void main()
-
{ char s[] = "a", str[32];
-
int l = strlen(s);
-
int i = fnBase64Encode(s, str, l);
-
printf("fnBase64Encode(\"%s\", str, %d) = \"%s\";\n", s, l, str);
-
l = fnBase64Decode(s, str, i);
-
printf("fnBase64Decode(\"%s\", s, %d) = \"%s\";\n", str, i, s);
-
}
编译为控制台应用程序,运行如图:
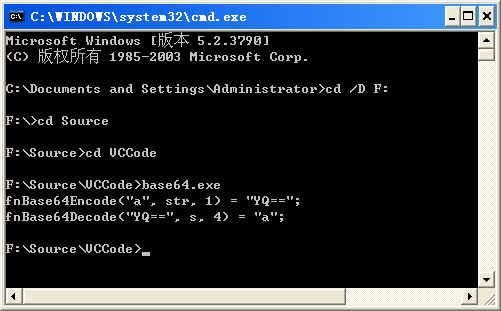
原文地址:http://blog.csdn.net/prsniper/article/details/7097643
Base64编码解码算法
标签:base64 编码 解码
原文地址:http://blog.csdn.net/nyist327/article/details/40542291