标签:version 转移 owa 模式 trace 利用 sage 允许 异常抛出
JAVA中异常的层次
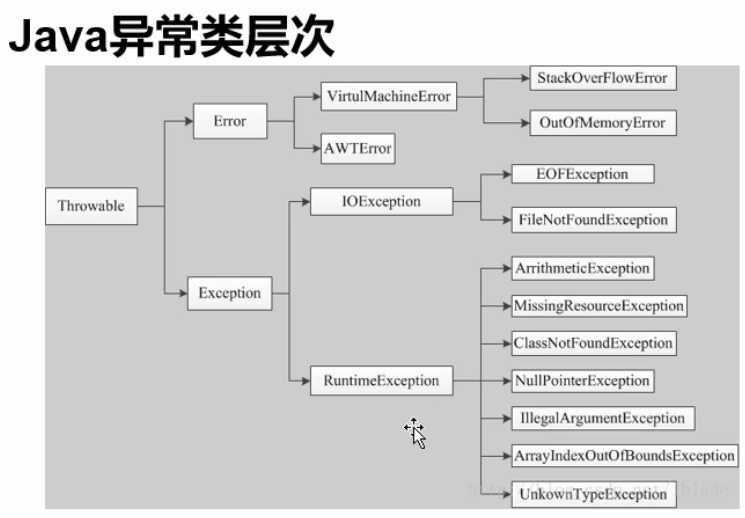
上图可以简单展示一下异常类实现结构图,当然上图不是所有的异常,用户自己也可以自定义异常实现。上图已经足够帮我们解释和理解异常实现了:
1.所有的异常都是从Throwable继承而来的,是所有异常的共同祖先。
2.Throwable有两个子类,Error和Exception。其中Error是错误,对于所有的编译时期的错误以及系统错误都是通过Error抛出的。这些错误表示故障发生于虚拟机自身、或者发生在虚拟机试图执行应用时,如Java虚拟机运行错误(Virtual MachineError)、类定义错误(NoClassDefFoundError)等。这些错误是不可查的,因为它们在应用程序的控制和处理能力之 外,而且绝大多数是程序运行时不允许出现的状况。对于设计合理的应用程序来说,即使确实发生了错误,本质上也不应该试图去处理它所引起的异常状况。在 Java中,错误通过Error的子类描述。
3.Exception,是另外一个非常重要的异常子类。它规定的异常是程序本身可以处理的异常。异常和错误的区别是,异常是可以被处理的,而错误是没法处理的。
4.Checked Exception
可检查的异常,这是编码时非常常用的,所有checked exception都是需要在代码中处理的。它们的发生是可以预测的,正常的一种情况,可以合理的处理。比如IOException,或者一些自定义的异常。除了RuntimeException及其子类以外,都是checked exception。
5.Unchecked Exception
RuntimeException及其子类都是unchecked exception。比如NPE空指针异常,除数为0的算数异常ArithmeticException等等,这种异常是运行时发生,无法预先捕捉处理的。Error也是unchecked exception,也是无法预先处理的。
在编写代码处理异常时,对于检查异常,有2种不同的处理方式:使用try…catch…finally语句块处理它。或者,在函数签名中使用throws 声明交给函数调用者caller去解决。
try...catch...finally
try{ //try块中放可能发生异常的代码。 //如果执行完try且不发生异常,则接着去执行finally块和finally后面的代码(如果有的话)。 //如果发生异常,则尝试去匹配catch块。 }catch(SQLException SQLexception){ //每一个catch块用于捕获并处理一个特定的异常,或者这异常类型的子类。Java7中可以将多个异常声明在一个catch中。 //catch后面的括号定义了异常类型和异常参数。如果异常与之匹配且是最先匹配到的,则虚拟机将使用这个catch块来处理异常。 //在catch块中可以使用这个块的异常参数来获取异常的相关信息。异常参数是这个catch块中的局部变量,其它块不能访问。 //如果当前try块中发生的异常在后续的所有catch中都没捕获到,则先去执行finally,然后到这个函数的外部caller中去匹配异常处理器。 //如果try中没有发生异常,则所有的catch块将被忽略。 }catch(Exception exception){ //... }finally{ //finally块通常是可选的。 //无论异常是否发生,异常是否匹配被处理,finally都会执行。 //一个try至少要有一个catch块,否则, 至少要有1个finally块。但是finally不是用来处理异常的,finally不会捕获异常。 //finally主要做一些清理工作,如流的关闭,数据库连接的关闭等。
需要注意的地方
1、try块中的局部变量和catch块中的局部变量(包括异常变量),以及finally中的局部变量,他们之间不可共享使用。
2、每一个catch块用于处理一个异常。异常匹配是按照catch块的顺序从上往下寻找的,只有第一个匹配的catch会得到执行。匹配时,不仅运行精确匹配,也支持父类匹配,因此,如果同一个try块下的多个catch异常类型有父子关系,应该将子类异常放在前面,父类异常放在后面,这样保证每个catch块都有存在的意义。
3、java中,异常处理的任务就是将执行控制流从异常发生的地方转移到能够处理这种异常的地方去。也就是说:当一个函数的某条语句发生异常时,这条语句的后面的语句不会再执行,它失去了焦点。执行流跳转到最近的匹配的异常处理catch代码块去执行,异常被处理完后,执行流会接着在“处理了这个异常的catch代码块”后面接着执行。
有的编程语言当异常被处理后,控制流会恢复到异常抛出点接着执行,这种策略叫做:resumption model of exception handling(恢复式异常处理模式 )
而Java则是让执行流恢复到处理了异常的catch块后接着执行,这种策略叫做:termination model of exception handling(终结式异常处理模式)
throws 抛出异常
throws声明:如果一个方法内部的代码会抛出检查异常(checked exception),而方法自己又没有完全处理掉,则javac保证你必须在方法的签名上使用throws关键字声明这些可能抛出的异常,否则编译不通过。
throws是另一种处理异常的方式,它不同于try…catch…finally,throws仅仅是将函数中可能出现的异常向调用者声明,而自己则不具体处理。
采取这种异常处理的原因可能是:方法本身不知道如何处理这样的异常,或者说让调用者处理更好,调用者需要为可能发生的异常负责。
public void foo() throws ExceptionType1 , ExceptionType2 ,ExceptionTypeN { //foo内部可以抛出 ExceptionType1 , ExceptionType2 ,ExceptionTypeN 类的异常,或者他们的子类的异常对象。 }
finally块不管异常是否发生,只要对应的try执行了,则它一定也执行。只有一种方法让finally块不执行:System.exit()。因此finally块通常用来做资源释放操作:关闭文件,关闭数据库连接等等。
良好的编程习惯是:在try块中打开资源,在finally块中清理释放这些资源。
需要注意的地方:
1、finally块没有处理异常的能力。处理异常的只能是catch块。
2、在同一try…catch…finally块中 ,如果try中抛出异常,且有匹配的catch块,则先执行catch块,再执行finally块。如果没有catch块匹配,则先执行finally,然后去外面的调用者中寻找合适的catch块。
3、在同一try…catch…finally块中 ,try发生异常,且匹配的catch块中处理异常时也抛出异常,那么后面的finally也会执行:首先执行finally块,然后去外围调用者中寻找合适的catch块。
这是正常的情况,但是也有特例。关于finally有很多恶心,偏、怪、难的问题,详细看参考
throw exceptionObject
程序员也可以通过throw语句手动显式的抛出一个异常。throw语句的后面必须是一个异常对象。
throw 语句必须写在函数中,执行throw 语句的地方就是一个异常抛出点,它和由JRE自动形成的异常抛出点没有任何差别。
public void save(User user) { if(user == null) throw new IllegalArgumentException("User对象为空"); //...... }
在一些大型的,模块化的软件开发中,一旦一个地方发生异常,则如骨牌效应一样,将导致一连串的异常。假设B模块完成自己的逻辑需要调用A模块的方法,如果A模块发生异常,则B也将不能完成而发生异常,但是B在抛出异常时,会将A的异常信息掩盖掉,这将使得异常的根源信息丢失。异常的链化可以将多个模块的异常串联起来,使得异常信息不会丢失。
异常链化:以一个异常对象为参数构造新的异常对象。新的异对象将包含先前异常的信息。这项技术主要是异常类的一个带Throwable参数的函数来实现的。这个当做参数的异常,我们叫他根源异常(cause)。
查看Throwable类源码,可以发现里面有一个Throwable字段cause,就是它保存了构造时传递的根源异常参数。这种设计和链表的结点类设计如出一辙,因此形成链也是自然的了。
public class Throwable implements Serializable { private Throwable cause = this; public Throwable(String message, Throwable cause) { fillInStackTrace(); detailMessage = message; this.cause = cause; } public Throwable(Throwable cause) { fillInStackTrace(); detailMessage = (cause==null ? null : cause.toString()); this.cause = cause; } //........ }
下面是一个例子,演示了异常的链化:从命令行输入2个int,将他们相加,输出。输入的数不是int,则导致getInputNumbers异常,从而导致add函数异常,则可以在add函数中抛出
一个链化的异常。
public static void main(String[] args) { System.out.println("请输入2个加数"); int result; try { result = add(); System.out.println("结果:"+result); } catch (Exception e){ e.printStackTrace(); } } //获取输入的2个整数返回 private static List<Integer> getInputNumbers() { List<Integer> nums = new ArrayList<>(); Scanner scan = new Scanner(System.in); try { int num1 = scan.nextInt(); int num2 = scan.nextInt(); nums.add(new Integer(num1)); nums.add(new Integer(num2)); }catch(InputMismatchException immExp){ throw immExp; }finally { scan.close(); } return nums; } //执行加法计算 private static int add() throws Exception { int result; try { List<Integer> nums =getInputNumbers(); result = nums.get(0) + nums.get(1); }catch(InputMismatchException immExp){ throw new Exception("计算失败",immExp); /////////////////////////////链化:以一个异常对象为参数构造新的异常对象。 } return result; } /* 请输入2个加数 r 1 java.lang.Exception: 计算失败 at practise.ExceptionTest.add(ExceptionTest.java:53) at practise.ExceptionTest.main(ExceptionTest.java:18) Caused by: java.util.InputMismatchException at java.util.Scanner.throwFor(Scanner.java:864) at java.util.Scanner.next(Scanner.java:1485) at java.util.Scanner.nextInt(Scanner.java:2117) at java.util.Scanner.nextInt(Scanner.java:2076) at practise.ExceptionTest.getInputNumbers(ExceptionTest.java:30) at practise.ExceptionTest.add(ExceptionTest.java:48) ... 1 more */
如果要自定义异常类,则扩展Exception类即可,因此这样的自定义异常都属于检查异常(checked exception)。如果要自定义非检查异常,则扩展自RuntimeException。
按照国际惯例,自定义的异常应该总是包含如下的构造函数:
下面是IOException类的完整源代码,可以借鉴。
public class IOException extends Exception { static final long serialVersionUID = 7818375828146090155L; public IOException() { super(); } public IOException(String message) { super(message); } public IOException(String message, Throwable cause) { super(message, cause); } public IOException(Throwable cause) { super(cause); } }
1、当子类重写父类的带有 throws声明的函数时,其throws声明的异常必须在父类异常的可控范围内——用于处理父类的throws方法的异常处理器,必须也适用于子类的这个带throws方法 。这是为了支持多态。
例如,父类方法throws 的是2个异常,子类就不能throws 3个及以上的异常。父类throws IOException,子类就必须throws IOException或者IOException的子类。
至于为什么?我想,也许下面的例子可以说明。
class Father { public void start() throws IOException { throw new IOException(); } } class Son extends Father { public void start() throws Exception { throw new SQLException(); } } /**********************假设上面的代码是允许的(实质是错误的)***********************/ class Test { public static void main(String[] args) { Father[] objs = new Father[2]; objs[0] = new Father(); objs[1] = new Son(); for(Father obj:objs) { //因为Son类抛出的实质是SQLException,而IOException无法处理它。 //那么这里的try。。catch就不能处理Son中的异常。 //多态就不能实现了。 try { obj.start(); }catch(IOException) { //处理IOException } } } }
2、Java程序可以是多线程的。每一个线程都是一个独立的执行流,独立的函数调用栈。如果程序只有一个线程,那么没有被任何代码处理的异常 会导致程序终止。如果是多线程的,那么没有被任何代码处理的异常仅仅会导致异常所在的线程结束。
也就是说,Java中的异常是线程独立的,线程的问题应该由线程自己来解决,而不要委托到外部,也不会直接影响到其它线程的执行。
在函数中对可能出现的异常的代码进行try catch处理后, 程序会执行catch里的代码. 而且不会中断整个程序, 继续执行try catch后面的代码.
try{ 可能出异常的若干行代码; } catch(ExceptionName1 e){ 产生ExceptionName 1的处理代码; } catch(ExceptionName2 e){ 产生ExceptionName 2的处理代码; } ... finally{ 无论如何, 最终肯定会执行的代码 }
try{ f(); ff(); } catch(ArithmeticException e){ g(); } catch(IOException e){ gg(); } catch(AuthorizedException e){ ggg(); } finally{ h(); } k();
当f()抛出了异常, 那么ff()就不会执行了. 程序会尝试捕捉异常.
首先捕捉ArithmeticException, 捕捉失败.
接下来捕捉IOException, 捕捉成功, 执行gg();
一旦捕捉到一个异常, 不会再尝试捕捉其他异常, 直接执行finally里的h();
执行后面的函数k().
也就是说路线是:
f() -> gg() -> h() -> k()
有2点要注意的.
1. f()函数极有可能未完整执行, 因为它抛出了异常, 抛出异常的语句执行失败, 之后的语句放弃执行.
2. try{} 里面, f()之后的语句, 例如ff()放弃执行.
这种情况很简单, 就是try{}里面的代码被完整执行, 因为没有抛出任何异常, 就不会尝试执行catch里的部分, 直接到finally部分了.
路线是:
f() -> ff() -> h() -> k()
也许有人会问, 我们怎么知道到底会抛出什么异常?
下面有3个解决方案.
1.看代码凭经验, 例如看到1段除法的代码, 则有可能抛出算术异常.
2.在catch的括号里写上Exception e, 毕竟Exception 是所有其他异常的超类, 这里涉及多态的知识, 至于什么是多态可以看看本人的另一篇文章.
3. 观察被调用函数的函数定义, 如果有throws后缀, 则可以尝试捕捉throws 后缀抛出的异常
包括我在内很多人会觉得finally语句简直多勾余, 既然是否捕捉到异常都会执行, 上面那个例子里的h()为什么不跟下面的k() 写在一起呢.
上面的例子的确看不出区别.
但下面两种情况下就体现了finally独特的重要性.
例如try里面抛出了1个A异常, 但是只有后面只有捕捉B异常, 和C异常的子句.
这种情况下, 程序直接执行finally{}里的子句, 然后中断当前函数, 把异常抛给上一级函数, 所以当前函数finally后面的语句不会被执行.
这种情况是编程的低级错误, 在项目中是不允许出现.
避免方法也十分简单, 在catch子句集的最后增加1个catch(Exception e)就ok, 因为Exception是所有异常的超类, 只要有异常抛出, 则肯定会捕捉到.
下面例子:
try{ f(); ff(); } catch(ArithException e){ g(); return j(); } catch(IOException e){ gg(); return j(); } catch(AuthorizedException e){ ggg(); return j(); } finally{ h(); } k();
假如在f()函数抛出了IOExcepion 异常被捕捉到.
那么执行路线就是
f() -> gg() -> j() -> h() -> 上一级function
也就说, 这种情况下finally里的子句会在return回上一级function前执行. 而后面的k()就被放弃了.
可以看出, finally里的语句, 无论如何都会被执行.
至有两种情况除外, 一是断电, 二是exit函数.
在项目中, 我们一般在finally编写一些释放资源的动作, 例如初始化公共变量. 关闭connections, 关闭文件等.
这个上面提到过了, 一旦捕捉到1个异常, 就不会尝试捕捉其他异常.
如果try里面的一段代码可能抛出3种异常A B C,
首先看它先抛出哪个异常, 如果先抛出A, 如果捕捉到A, 那么就执行catch(A)里的代码. 然后finally.. B和C就没有机会再抛出了.
如果捕捉不到A, 就执行finally{}里的语句后中断当前函数, 抛给上一级函数...(应该避免)
两种情况, 1就是没有异常抛出, 另一种就是抛出了异常但是没有捕捉不到(应该避免)
加入try 里面尝试捕捉两个异常, 1个是A, 1个是B, 但是A是B的父类.
这种情况下, 应该把catch(B)写在catch(A)前面.
原因也很简单, 加入把catch(A)写在前面, 因为多态的存在, 即使抛出了B异常, 也会被catch(A)捕捉, 后面的catch(B)就没有意义了.
也就是说如果捕捉Exception这个异常基类, 应该放在最后的catch里, 项目中也强烈建议这么做, 可以避免上述4.3.1的情况出现.
这个没什么好说的. 语法规则
每1个异常对象只能由catch它的catch子句里访问.
跟if类似, 不多说了.
这个也不难理解..
下面开始详讲异常另一种处理方法throw 和 throws了.
注意的是, 这两种用法都没有真正的处理异常, 真正处理的异常方法只有try catch, 这两种方法只是交给上一级方法处理.
就如一个组织里 , 有1个大佬, 1个党主, 1个小弟.
大佬叫党主干活, 堂主叫小弟干活, 然后小弟碰上麻烦了, 但是小弟不会处理这个麻烦, 只能中断工作抛给党主处理, 然后堂主发现这个麻烦只有大佬能处理, 然后抛给大佬处理..
道理是相通的..
throw的语法很简单.
语法:
throw new XException();
其中xException必须是Exception的派生类.
这里注意throw 出的是1个异常对象, 所以new不能省略
作用就是手动令程序抛出1个异常对象.
public int f(int a, int b){ if (0 == b){ throw new ArithmeticException("Shit !!! / by zero!"); } return a/b; }
当这个函数的if 判断了b=0时, 就利用throws手动抛出了1个异常. 这个异常会中断这个函数. 也就是说f()执行不完整, 是没有返回值的.
public void g(){ int i; h(); i = f(); //recevie excepton k(); }
例如上没的g()函数, 在调用f() 会收到1个异常.
这时g()函数有三种选择.
1. 不做任何处理
这时, g()收到f()里抛出的异常就会打断g()执行, 也就是说g()里面的k(); 被放弃了, 然后程序会继续把这个函数抛给调用g()函数.
然后一级一级寻求处理, 如果都不处理, 则抛给jvm处理. jvm会中断程序, 输出异常信息. 这个上没提到过了.
2. 使用try catch处理
如果catch成功, 则g()函数能完整执行, 而且这个异常不会继续向上抛.
如果catch失败(尽量避免), 则跟情况1相同.
public int f(int a, int b){ if (0 == b){ throw new IOException("Shit !!! / by zero!"); } return a/b; }
前面说到throw的异常必须是Exception的派生类.
如果,我不想抛出ArithmeticException, 我想抛出IOExcetpion.
注意 这里, IOException虽然逻辑上是错误的(完全不是IO的问题嘛), 但是在程序中完全可行, 因为程序猿可以根据需要控制程序指定抛出任何1个异常.
但是这段代码编译失败, 因为IOException 不是 RuntimeException的派生类.
java规定:
public int f(int a, int b) throws IOException{ if (0 == b){ throw new IOException("Shit !!! / by zero!"); } return a/b; }
也就是上面这样,在方法定义里加上了throws子句. 告诉调用它的函数我可能抛出这个异常.
比如g()调用f()
public void g(){ int i; h(); i = f(); //recevie excepton k() }
但是编译失败.
因为f()利用throws 声明了会抛出1个非runtimeExcetpion. 这时g()必须做出处理.
处理方法有两种:
1. try catch自己处理,
需要注意的是, catch里面要么写上throws对应的异常(这里是 IOException), 要么写上这个异常的超类, 否则还是编译失败.
public void g(){ int i = 0; h(); try{ i = f(); //recevie excepton } catch(IOException e){ } k(); }
2.g()利用throws 往上一级方法抛
public void g() throws IOException{ int i = 0; h(); i = f(); //recevie excepton k(); }
这时候调用g()的函数也要考虑上面的这两种处理方法了...
但是最终上级的方法(main 方法)还是不处理的话, 就编译失败, 上面说过了, 非runtimeException无法抛给jvm处理.
虽然这两种处理方法都能通过编译, 但是运行效果是完全不同的.
第一种, g()能完整执行.
第二种, g()被中断, 也就是g()里面的k(); 执行失败.
throws稍微比throw难理解点:
语法是:
public void f() throws Exception1, Exception2...{
}
也就是讲, thorws可以加上多个异常, 注意这里抛出的不是对象, 不能加上new.
而且不是告诉别人这个函数有可能抛出这么多个异常. 而是告诉别人, 有可能抛出这些异常的其中一种.
如果为f()函数加上throws后续, 则告诉调用f()的方法, f()函数有可能抛出这些异常的一种.
如果f()throws 了1个或若干个非RuntimeException, 则调用f()的函数必须处理这些非RuntimeException, 如上面的g()函数一样.
如果f() throws的都是RuntimeException, 则调用f()的函数可以不处理, 也能通过编译, 但是实际上还是强烈建议处理它们.
实际上, 如果1个方法f() throws A,B
那么它有可能不抛出任何异常.(程序运行状态良好)
也有能抛出C异常(应该避免, 最好在throws上加上C)
1 一个函数体里面手动throw了1个RumtimeException, 则这个函数的定义必须加上throws子句
这个是强制, 告诉别人这个函数内有炸弹.
2 一个函数内有可能由系统抛出异常.
这个是非强制的, 但是如果你知道一个函数内的代码有可能抛出异常, 最好还是写上throws 后缀
无论这个异常是否runtimeExcepion.
个人建议, 如果你调用1个函数throws A, B, C
那么你就在当前函数写上
try
catch(A)
catch(B)
catch(C)
catch(Exception)
这样能处理能保证你的函数能完整执行, 不会被收到的异常中断.
当然如果你允许你的函数可以被中断, 那么就可以在当前函数定义加上throws A, B 继续抛给上一级的函数.
例如你在一个派生类重写一个方法f(), 在超类里的f() throws A, B 你重写方法时就不throws出 A,,B,C 或者throws A和B的超类.
原因也是由于多态的存在.
因为1个超类的引用可以指向1个派生类的对象并调用不同的方法. 如果派生类throws的范围加大
那么利用多态写的代码的try catch就不再适用.
面试问得多,单独拉出来写了:
应付面试官.
所以throw后面的一般加上new 和exception名字().
而throws后面不能加上new的
因为一旦一个函数throw出1个异常, 这个函数就会被中断执行, 后面的代码被放弃, 如果你尝试在函数内写两个throw, 编译失败.
而throws 是告诉别人这个函数有可能抛出这几种异常的一种. 但是最多只会抛出一种.
原因上面讲过了.
参考:https://www.cnblogs.com/williamjie/p/9103658.html
标签:version 转移 owa 模式 trace 利用 sage 允许 异常抛出
原文地址:https://www.cnblogs.com/ccoonngg/p/11706621.html