标签:平衡 访问速度 text 存储 访问 数据引擎 链表 big 保持数据
BF高教的表征数据集合,时间和空间效率极高。使用长度为m的位数组A来存储集合信息,使用k个相互独立的哈希函数将数据映射到为数组空间。对于集合中的成员a,将其进行k次哈希,哈希结果为x,则将位数组的第x位设置为1,最多有w<=k位会被设置为1. 如果需要判断某个成员是否在S中出现,只需要看hash国有w位中有没有出现0即可。
BF会发生误判,不在集合中的数据被判定成了在集合中,因为a1和a2设置的位可能刚好覆盖了a3的所有哈希位。但不会发生错判。
最优的哈希函数个数为m/n * ln(2).
改进BF: 计数BF.
应用:如恶意url判断,爬虫对url时候爬过的判断,BigTable中用BF来查询key cache ,如果出现误判,在实际存储中查不到,顶多再实际访问一次硬盘,极大提高了访问效率。
可替代平衡树的数据结构,依靠随机生成数以一定概率来保持数据的平痕分布。插入,删除,查找的福再度都是o(log(n)).
传统的有序链表查找需要遍历。对每个节点都增加一个指针,指向后续节点之后的节点,这样查询的时候就可以加快访问速度。
Search:
Insert & Delete
当增加到3个或更多指针时,查询效率进一步提高。skiplist依赖随机数来保持平衡,插入即电视,随机决定该节点有多个指向后续节点的指针。
Log-Structured Merge Tree,将大量随机写变成批量的顺序写,非常适合写操作要求高的场景。
BigTable中的单机数据引擎本质上就是LSM树。Cassandra也用了LSM树。
LSM树原理把一棵大树拆分成N棵小树,它首先写入内存中,随着小树越来越大,内存中的小树会flush到磁盘中,磁盘中的树定期可以做merge操作,合并成一棵大树,以优化读性能。写入内存是同时写入log到硬盘上,防止系统崩溃时数据丢失。内存表中通常使用SkipList,保持数据有序,当内存够大时,写入到磁盘。
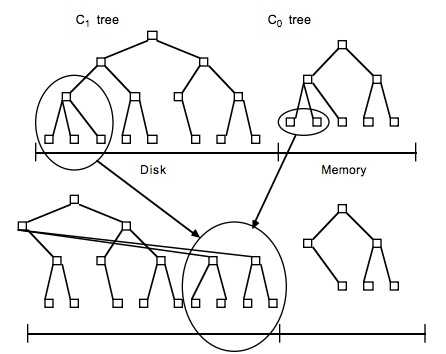
Level DB, classic LSM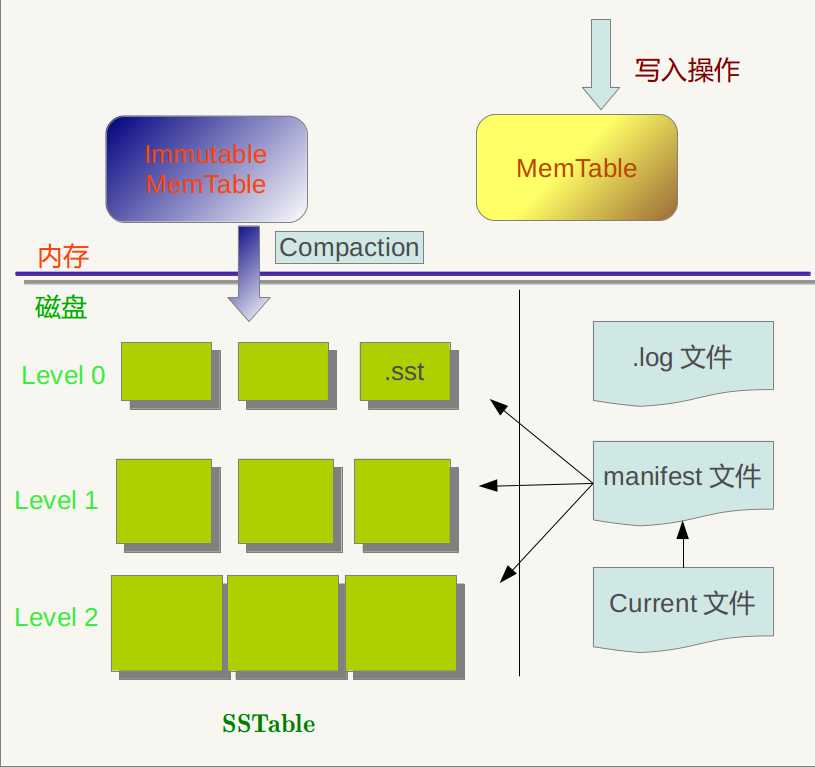
Reference: http://www.cnblogs.com/haippy/archive/2011/12/04/2276064.html
标签:平衡 访问速度 text 存储 访问 数据引擎 链表 big 保持数据
原文地址:https://www.cnblogs.com/dajunjun/p/11710998.html

