大数据部落 -中国专业的第三方数据服务提供商,提供定制化的一站式数据挖掘和统计分析咨询服务
统计分析和数据挖掘咨询服务:y0.cn/teradat(咨询服务请联系官网客服)
![]() ?
?QQ:3025393450
![]() ?QQ交流群:186388004
?QQ交流群:186388004 
【服务场景】
科研项目; 公司项目外包;线上线下一对一培训;数据爬虫采集;学术研究;报告撰写;市场调查。
【大数据部落】提供定制化的一站式数据挖掘和统计分析咨询

欢迎选修我们的R语言数据分析挖掘必知必会课程!

标签:根据 了解 -o site img 联系 href contain 开发
如前所述,Apriori算法用于关联规则挖掘。现在,什么是关联规则挖掘?关联规则挖掘是一种用于识别一组项目之间的频繁模式和关联的技术。
例如,了解客户的购买习惯。通过查找顾客放置在其“购物篮”中的不同商品之间的关联和关联,可以得出重复的模式.
识别产品/商品之间的关联的过程称为关联规则挖掘。为了实现关联规则挖掘,已经开发了许多算法。Apriori算法是其中最受欢迎的算法,而且可以说是最有效的算法。让我们讨论什么是Apriori算法。
什么是先验算法?
Apriori算法假定频繁项集的任何子集都必须是频繁的。
假设包含{葡萄酒,薯条,面包}的交易也包含{葡萄酒,面包}。因此,根据Apriori原理,如果{酒,薯条,面包}很频繁,那么{酒,面包}也必须很频繁。
Apriori算法中的关键概念是,它假定一个频繁项集的所有子集都是频繁的。同样,对于任何不频繁的项目集,其所有超集也必须不频繁。
让我们在一个非常著名的业务场景市场篮分析的帮助下,尝试并理解Apriori算法的工作原理。
这是一个小时内包含六个事务的数据集。每个事务都是0和1的组合,其中0表示不存在某项,而1表示其存在。
| 交易编号 | 葡萄酒 | 薯片 | 面包 | 牛奶 |
| 1 | 1个 | 1个 | 1个 | 1个 |
| 2 | 1个 | 0 | 1个 | 1个 |
| 3 | 0 | 0 | 1个 | 1个 |
| 4 | 0 | 1个 | 0 | 0 |
| 5 | 1个 | 1个 | 1个 | 1个 |
| 6 | 1个 | 1个 | 0 | 1个 |
我们可以从这种情况下找到多个规则。例如,在葡萄酒,薯条和面包的交易中,如果购买了葡萄酒和薯条,那么客户也会购买面包。
{葡萄酒,薯条} => {面包}
现在我们知道了找出有趣规则的方法,让我们回到示例中。在开始之前,让我们将支持阈值固定为50%。
步骤1:创建所有交易中出现的所有项目的频率表
| 项目 | 频率 |
| 葡萄酒 | 4 |
| 薯片 | 4 |
| 面包 | 4 |
| 牛奶 | 5 |
步骤2:根据支持阈值查找重要项目
支持阈值= 3
| 项目 | 频率 |
| 葡萄酒 | 4 |
| 薯片 | 4 |
| 面包 | 4 |
| 牛奶 | 5 |
| 项目 | 频率 |
| 葡萄酒,薯条 | 3 |
| 葡萄酒,面包 | 3 |
| 葡萄酒,牛奶 | 4 |
| 薯条,面包 | 2 |
| 薯片,牛奶 | 3 |
| 面包,牛奶 | 4 |
| 项目 | 频率 |
| 葡萄酒,牛奶 | 4 |
| 面包,牛奶 | 4 |
| 项目 | 频率 |
| 葡萄酒,面包,牛奶 | 3 |
{酒,面包,牛奶}是从给定数据中获得的唯一重要项目集。但是在实际场景中,我们将有数十个项目可用来构建规则。然后,我们可能必须制作四对/五对项集。
一家零售商店的经理正在尝试找出六个商品之间的关联规则,以找出哪些商品更经常一起购买,以便他可以将这些商品放在一起以增加销量。
以下是第一天的交易数据。此数据集包含6个项目和22个交易记录。
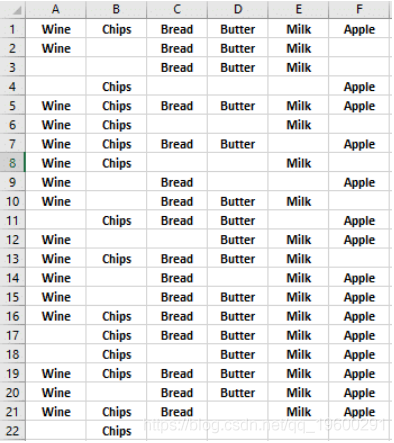
![]() ?
?
我们将实现Apriori算法,以帮助经理进行市场分析。

![]() ?
?
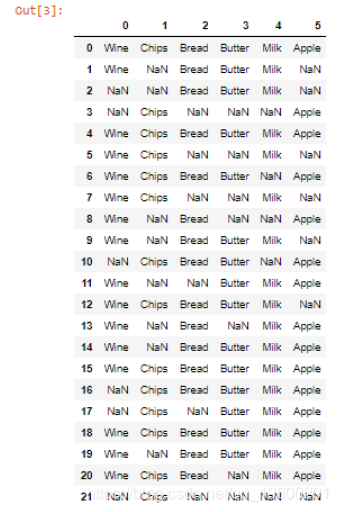
![]() ?
?

![]() ?
?

![]() ?
?

![]() ?
?
第一条规则的支持值为0.5。该数字是通过将包含“牛奶”,“面包”和“黄油”的交易数量除以交易总数而得出的。
该规则的置信度为0.846,这表明在同时包含“牛奶”和“面包”的所有交易中,也有84.6%的交易包含“黄油”。
提升1.241告诉我们,同时购买“牛奶”和“黄油”的顾客购买“黄油”的可能性是“黄油”的默认可能性的1.241倍。
大数据部落 -中国专业的第三方数据服务提供商,提供定制化的一站式数据挖掘和统计分析咨询服务
统计分析和数据挖掘咨询服务:y0.cn/teradat(咨询服务请联系官网客服)
![]() ?
?QQ:3025393450
![]() ?QQ交流群:186388004
?QQ交流群:186388004
【服务场景】
科研项目; 公司项目外包;线上线下一对一培训;数据爬虫采集;学术研究;报告撰写;市场调查。
【大数据部落】提供定制化的一站式数据挖掘和统计分析咨询
欢迎选修我们的R语言数据分析挖掘必知必会课程!
标签:根据 了解 -o site img 联系 href contain 开发
原文地址:https://www.cnblogs.com/tecdat/p/11713808.html