标签:text 现在 www span lin array shm 需要 blog
这里有一些定义及代码取自CodeInfo的简书,链接:https://www.jianshu.com/p/b805e9d1eb5c,和heroacool的CSDN,链接:https://blog.csdn.net/heroacool/article/details/51014824,感谢两位大佬。
狄克斯特拉算法(Dijkstra )用于计算出不存在非负权重的情况下,起点到各个节点的最短距离(单源最短路问题),如果要得到整个图各个顶点之间的最短距离,则需要对整个图的每个顶点都遍历一遍狄克斯特拉算法,显然不合适,所以这里要注意使用场合。
其思路为:
(1) 找出节点集合U里面“最便宜”的节点,即可在最短时间内到达的节点,并将它加入集合S里面(问题二:为什么该节点可以加入S集合,也就是认为此时他与源节点距离最小),并把该节点从集合U里面取出。
(2) 更新该节点对应的邻居节点的开销(问题一:其含义将稍后介绍)。
(3) 重复这个过程,直到对图中的每个节点都这样做了。
(4) 计算最终路径。
为了防止重复遍历节点,引进两个集合S和U。S的作用是记录已求出最短路径的节点(以及相应的最短路径长度),而U则是记录还未求出最短路径的节点(以及该节点到起点s的距离)。
由上可知,代码实现的时候要注意第一点即遍历U集合里面的最短路径和第二点更新开销。
问题一的见解:因为权重的赋予不同,所以并不会出现两点之间直线最短。如下图(自己画的,有点丑),
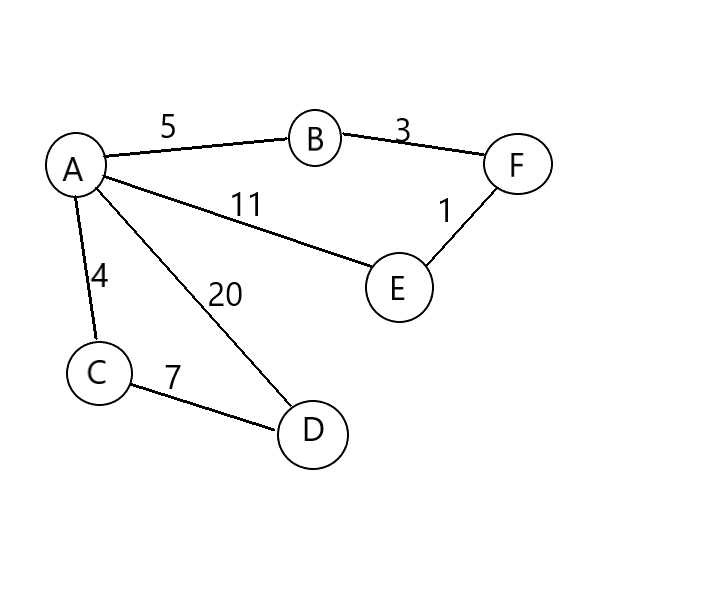
起点A->节点D的距离>起点A->节点C->节点D的距离,所以需要对不同节点到起点的开销进行更新。但是问题又来了,如果每个点都把可以到达起点的所有路径开销进行更新,又会多出许多不必要的更新,我们要找的是最短路径,如果比该节点到起点已知的开销还要大的话,根本没有比较的意义,而且作为最短路径,那么它前面的节点也就不会出现更短的情况,可以避免重复更新,减少不必要的重复,所以每次得到最短路径的时候再进行更新就很有必要(问题的解的必要性)。那么这样子更新能否满足问题的解的充分性呢?我们不妨这样想,现在假设要通过节点C(这里的节点C是上帝视角即整个完整图里面到达节点D最短路径的前一个节点)到达节点D的距离会更短,要最短,那么也就是起点A->节点C的距离1+节点C->节点D的距离2最短,易得距离1要在起点A->节点C的所有可能路径中距离最短,所以每次找到最短路径的节点时进行更新是合适的,如果的确存在这样的路径,就一定会有前一个节点(完整性)。
问题二的见解:这里有点类似数学归纳法。
从第一个加入S集合的点说起,显然该点就是起点,他到自己的距离为零。更新开销后,各节点到起点距离不变。因为没有负权重,所以这个时候距离起点最短的点shortest一定没有其他路径能够提供更短距离到起点,即起点通过其他节点到达shortest的距离必然大于起点直接到达shortest,打个比方,起点A->shortest的距离为10,起点A->节点B的距离为12(该距离必然要大于起点A->shortest的距离,见蓝字前提),又没有负权重,所以起点A->shortest的距离<起点A->节点B->shortest的距离。所以将节点shortest加入集合S就没有任何问题了。
现在有一个多于两个节点的集合S,和集合U,提出这样一个假设:当更新某个节点的开销后,起点与集合U里面的某个节点距离最短时,就认为这个距离是起点到该点所有路径里面最短的并且比起点到集合U其他节点的距离还要短。
shortest依旧是起点到集合U里面各个节点最短距离的点。因为起点A->shortest的所有路径里面的最短距离的前一个节点必然开销比shortest更小,也即是该节点在集合S里面,所以这时候的起点A->shortest的距离是最短的。同时,对于集合U里面的其他节点而言,起点A->他们的距离不可能比shortest更短(1,假设最短路径的前一个节点在集合S里面,那么已经更新了;2,假设最短路径的前一个节点在集合U里面,无论这条路径是怎么走,必然会有一个节点C非起点,是集合S里面的,不然该路径上起点到其相邻结点,此节点应在集合U里面的距离将小于起点->shortest的距离)。
Java代码:
1 /** 2 * 狄克斯特拉算法 3 * @author Administrator 4 * 5 */ 6 public class Dijkstra { 7 public static void main(String[] args){ 8 HashMap<String,Integer> A = new HashMap<String,Integer>(){ 9 { 10 put("B",5); 11 put("C",1); 12 } 13 }; 14 15 HashMap<String,Integer> B = new HashMap<String,Integer>(){ 16 { 17 put("E",10); 18 } 19 }; 20 HashMap<String,Integer> C = new HashMap<String,Integer>(){ 21 { 22 put("D",5); 23 put("F",6); 24 } 25 }; 26 HashMap<String,Integer> D = new HashMap<String,Integer>(){ 27 { 28 put("E",3); 29 } 30 }; 31 HashMap<String,Integer> E = new HashMap<String,Integer>(){ 32 { 33 put("H",3); 34 } 35 }; 36 HashMap<String,Integer> F = new HashMap<String,Integer>(){ 37 { 38 put("G",2); 39 } 40 }; 41 HashMap<String,Integer> G = new HashMap<String,Integer>(){ 42 { 43 put("H",10); 44 } 45 }; 46 HashMap<String,HashMap<String,Integer>> allMap = new HashMap<String,HashMap<String,Integer>>() { 47 { 48 put("A",A); 49 put("B",B); 50 put("C",C); 51 put("D",D); 52 put("E",E); 53 put("F",F); 54 put("G",G); 55 } 56 }; 57 58 59 Dijkstra dijkstra = new Dijkstra(); 60 dijkstra.handle("A","H",allMap); 61 } 62 63 private String getMiniCostKey(HashMap<String,Integer> costs,List<String> hasHandleList) { 64 int mini = Integer.MAX_VALUE; 65 String miniKey = null; 66 for(String key : costs.keySet()) { 67 if(!hasHandleList.contains(key)) { //找出未处理的点,即集合U里面的点最小开销 68 int cost = costs.get(key); 69 if(mini > cost) { 70 mini = cost; 71 miniKey = key; 72 } 73 } 74 } 75 return miniKey; 76 } 77 78 private void handle(String startKey,String target,HashMap<String,HashMap<String,Integer>> all) { 79 //存放到各个节点所需要消耗的时间 80 HashMap<String,Integer> costMap = new HashMap<String,Integer>(); 81 //到各个节点对应的父节点 82 HashMap<String,String> parentMap = new HashMap<String,String>(); 83 //存放已处理过的节点key,已处理过的不重复处理 84 List<String> hasHandleList = new ArrayList<String>(); 85 86 //首先获取开始节点相邻节点信息 87 HashMap<String,Integer> start = all.get(startKey); 88 89 //添加起点到各个相邻节点所需耗费的时间等信息 90 for(String key:start.keySet()) { 91 int cost = start.get(key); 92 costMap.put(key, cost); 93 parentMap.put(key,startKey); 94 } 95 96 97 //选择最"便宜"的节点,这边即耗费时间最低的 98 String minCostKey = getMiniCostKey(costMap,hasHandleList); 99 while( minCostKey!=null ) { 100 System.out.print("处理节点:"+minCostKey); 101 HashMap<String,Integer> nodeMap = all.get(minCostKey); 102 if (nodeMap!=null) { 103 //该节点没有子节点可以处理了,末端节点 104 handleNode(minCostKey,nodeMap,costMap,parentMap); 105 } 106 //添加该节点到已处理结束的列表中 107 hasHandleList.add(minCostKey); 108 //再次获取下一个最便宜的节点 109 minCostKey = getMiniCostKey(costMap,hasHandleList); 110 } 111 if(parentMap.containsKey(target)) { 112 System.out.print("到目标节点"+target+"最低耗费:"+costMap.get(target)); 113 List<String> pathList = new ArrayList<String>(); 114 String parentKey = parentMap.get(target); 115 while (parentKey!=null) { 116 pathList.add(0, parentKey); 117 parentKey = parentMap.get(parentKey); 118 } 119 pathList.add(target); 120 String path=""; 121 for(String key:pathList) { 122 path = path + key + " --> "; 123 } 124 System.out.print("路线为"+path); 125 } else { 126 System.out.print("不存在到达"+target+"的路径"); 127 } 128 } 129 130 private void handleNode(String startKey,HashMap<String,Integer> nodeMap,HashMap<String,Integer> costMap,HashMap<String,String> parentMap) { 131 132 for(String key : nodeMap.keySet()) { 133 //获取原本到父节点所需要花费的时间 134 int hasCost = costMap.get(startKey); 135 //获取父节点到子节点所需要花费的时间 136 int cost = nodeMap.get(key); 137 //计算从最初的起点到该节点所需花费的总时间 138 cost = hasCost + cost; 139 140 if (!costMap.containsKey(key)) { 141 //如果原本并没有计算过其它节点到该节点的花费 142 costMap.put(key,cost); 143 parentMap.put(key,startKey); 144 }else { 145 //获取原本耗费的时间 146 int oldCost = costMap.get(key); 147 if (cost < oldCost) { 148 //新方案到该节点耗费的时间更少 149 //更新到达该节点的父节点和消费时间对应的散列表 150 costMap.put(key,cost); 151 parentMap.put(key,startKey); 152 System.out.print("更新节点:"+key + ",cost:" +oldCost + " --> " + cost); 153 } 154 } 155 } 156 }
第63行的getMiniCostKey函数是用来计算起点A到集合U里面距离最小节点。
第103行注释指的是当nodeMap==null时,该节点没有子节点可以处理了,末端节点,也就不用更新下一个结点的开销了
第104行是handleNode(minCostKey,nodeMap,costMap,parentMap);函数用来更新开销
第143行的parentMap使用一个key-value对来记录路径的最后节点及其父节点,这样的话,通过递推回去就能得到完整路径
C语言代码:
1 // 邻接矩阵 2 typedef struct _graph 3 { 4 char vexs[MAX]; // 顶点集合 5 int vexnum; // 顶点数 6 int edgnum; // 边数 7 int matrix[MAX][MAX]; // 邻接矩阵 8 }Graph, *PGraph; 9 10 // 边的结构体 11 typedef struct _EdgeData 12 { 13 char start; // 边的起点 14 char end; // 边的终点 15 int weight; // 边的权重 16 }EData; 17 ———————————————— 18 版权声明:本文为CSDN博主「heroacool」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。 19 原文链接:https://blog.csdn.net/heroacool/article/details/51014824
1 /* 2 * Dijkstra最短路径。 3 * 即,统计图(G)中"顶点vs"到其它各个顶点的最短路径。 4 * 5 * 参数说明: 6 * G -- 图 7 * vs -- 起始顶点(start vertex)。即计算"顶点vs"到其它顶点的最短路径。 8 * prev -- 前驱顶点数组。即,prev[i]的值是"顶点vs"到"顶点i"的最短路径所经历的全部顶点中,位于"顶点i"之前的那个顶点。 9 * dist -- 长度数组。即,dist[i]是"顶点vs"到"顶点i"的最短路径的长度。 10 */ 11 void dijkstra(Graph G, int vs, int prev[], int dist[]) 12 { 13 int i,j,k; 14 int min; 15 int tmp; 16 int flag[MAX]; // flag[i]=1表示"顶点vs"到"顶点i"的最短路径已成功获取。 17 18 // 初始化 19 for (i = 0; i < G.vexnum; i++) 20 { 21 flag[i] = 0; // 顶点i的最短路径还没获取到。 22 prev[i] = 0; // 顶点i的前驱顶点为0。 23 dist[i] = G.matrix[vs][i];// 顶点i的最短路径为"顶点vs"到"顶点i"的权。 24 } 25 26 // 对"顶点vs"自身进行初始化 27 flag[vs] = 1; 28 dist[vs] = 0; 29 30 // 遍历G.vexnum-1次;每次找出一个顶点的最短路径。 31 for (i = 1; i < G.vexnum; i++) 32 { 33 // 寻找当前最小的路径; 34 // 即,在未获取最短路径的顶点中,找到离vs最近的顶点(k)。 35 min = INF; 36 for (j = 0; j < G.vexnum; j++) 37 { 38 if (flag[j]==0 && dist[j]<min) 39 { 40 min = dist[j]; 41 k = j; 42 } 43 } 44 // 标记"顶点k"为已经获取到最短路径 45 flag[k] = 1; 46 47 // 修正当前最短路径和前驱顶点 48 // 即,当已经"顶点k的最短路径"之后,更新"未获取最短路径的顶点的最短路径和前驱顶点"。 49 for (j = 0; j < G.vexnum; j++) 50 { 51 tmp = (G.matrix[k][j]==INF ? INF : (min + G.matrix[k][j])); // 防止溢出 52 if (flag[j] == 0 && (tmp < dist[j]) ) 53 { 54 dist[j] = tmp; 55 prev[j] = k; 56 } 57 } 58 } 59 60 // 打印dijkstra最短路径的结果 61 printf("dijkstra(%c): \n", G.vexs[vs]); 62 for (i = 0; i < G.vexnum; i++) 63 printf(" shortest(%c, %c)=%d\n", G.vexs[vs], G.vexs[i], dist[i]); 64 ———————————————— 65 版权声明:本文为CSDN博主「heroacool」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。 66 原文链接:https://blog.csdn.net/heroacool/article/details/51014824
可以看到狄克斯特拉算法就是三件事,一,找到最短的点,二,把该点标记已处理,三,更新该点对其他点的影响。
标签:text 现在 www span lin array shm 需要 blog
原文地址:https://www.cnblogs.com/chenruibin0614/p/11723546.html