标签:ups uid star 使用 点数据 nfs服务器 bin ring out
hadoop架构
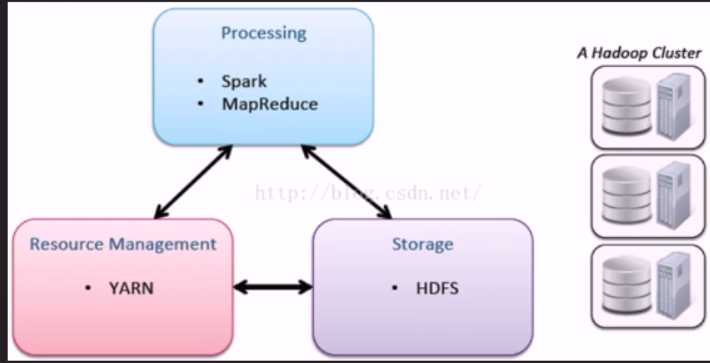
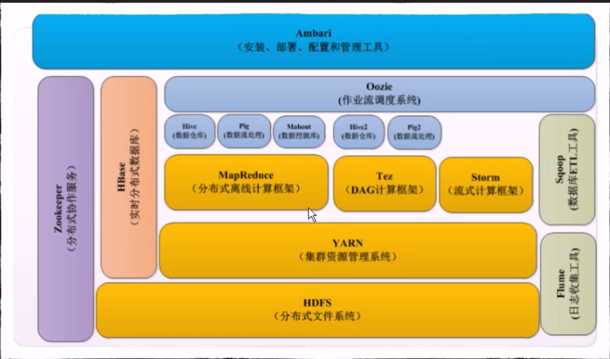
MapReduce:分布式计算架构
HDFS:分布式文件系统
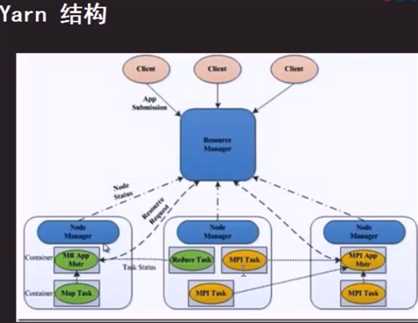
YARN:集群资源管理系统
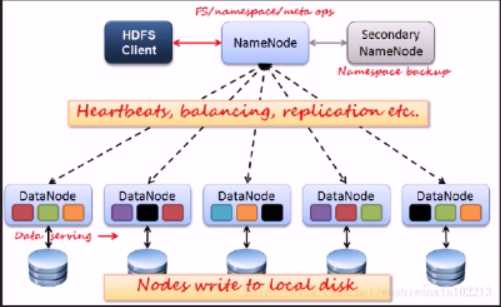
HDFS结构:


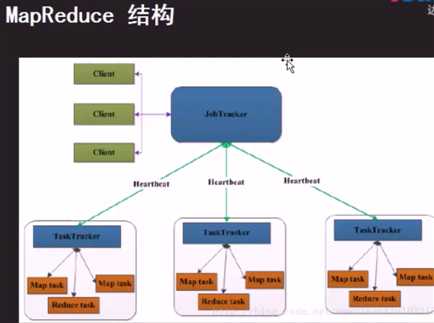





hadoop单机模式
搭建步骤:
搭建四台服务器,分别为:server、node1、node2、node3
1、关闭防火墙和selinux
2、保证server到每一个node节点可以免密码登陆,配置无密码登陆


[root@Server ~]# vim /etc/ssh/ssh_config

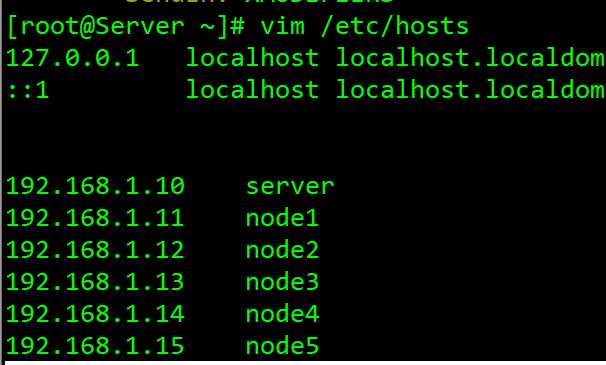
2、配置本地域名解析,每一台都需要配置
59 ssh root@node1 yum -y install rsync
60 ssh root@node2 yum -y install rsync
61 ssh root@node3 yum -y install rsync
62 ssh root@node4 yum -y install rsync
63 ssh root@node5 yum -y install rsync
把集群中的每一台设备的本地域名解析文件进行同步
[root@Server ~]# for i in {11..15} ; do rsync -a /etc/hosts root@192.168.1.${i}:/etc/hosts -e ‘ssh‘ & done
3、安装java
查询java安装包

[root@Server ~]# yum -y install java-1.8.0-openjdk-devel.x86_64
检测是否安装成功


4、下载:hadoop-2.7.7.tar.gz
https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
下载后上传到 /usr/local/hadoop目录下并解压
[root@Server hadoop]# tar -xf hadoop-2.7.7.tar.gz

5、修改环境变量
查找java路径
[root@Server ~]# find / -name java
/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.65-3.b17.el7.x86_64/jre
[root@Server]cd /usr/local/hadoop/hadoop-2.7.7/etc/hadoop
[root@Server hadoop]# vim hadoop-env.sh
需要修改一下部分

退到主文件下,进行测试,有以下显示,表示修改成功

修改hadoop配置文件路径

6、测试执行
[root@Server hadoop-2.7.7]# ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount input/ output
jar:表示应用的时jar计算模块
share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar--------计算模块文件(程序)
wordcount:使用的计算方式,此方法为统计input文件中每个单词出现的数量,并将统计结果输出到output文件中
计算搜首字母不是h的nfs的数量
[root@Server hadoop-2.7.7]# ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount grep input/ output ‘(?<=h)nfs‘
hadoop完全布式配置
按单机模式的配置好后,继续一下配置

----Xml文件配置方式
[root@Server ~]# cd /usr/local/hadoop/hadoop-2.7.7/etc/hadoop/
配置vim core-site.xml文件的参考文档
https://hadoop.apache.org/docs/r2.8.5/hadoop-project-dist/hadoop-common/core-default.xml
[root@Server hadoop]# vim core-site.xml---------在该文件下添加一下内容
<configuration>
<property>
<name>fs.defaultFS</name>------------------------------------------------------文件系统
<value>hdfs://server:9000</value>-----------------------------------------------9000表示端口号,用的是集群文件系统,"file:///"表示用本地文件系统
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/hadoop</value>-------------------------------------------------------数据存放的路径,该路径下Hadoop文件需要进群中的每一台上都要创建
</property>
<property>
<name>hadoop.proxyuser.nfsuser.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.nfsuser.hosts</name>
<value>*</value>
</property>
</configuration>
修改hdfs-site.xml文件,参考文档
https://hadoop.apache.org/docs/r2.8.5/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
[root@Server ~]# vim /usr/local/hadoop/hadoop-2.7.7/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.http-address</name>
<value>server:50070</value>----------------------------------------设置namenode地址(设置namenode的服务器是谁),端口号不能变
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>server:50090</value>-----------------------------------------设置namenode.secondary地址,端口号不能变
</property>
<property>
<name>dfs.replication</name>---------------------------------------设置文件备份数量
<value>2</value>
</property>
<property>
<name>nfs.exports.allowed.hosts</name>
<value>* rw</value>
</property>
<property>
<name>nfs.namenode.accesstime.precision</name>
<value>3600000</value>
</property>
<property>
<name>nfs.dump.dir</name>
<value>/var/hdfs-nfs</value>
</property>
<property>
<name>nfs.rtmax</name>
<value>4194304</value>
</property>
<property>
<name>nfs.wtmax</name>
<value>1048576</value>
</property>
<property>
<name>nfs.port.monitoring.disabled</name>
<value>true</value>
</property>
</configuration>
如果在/usr/local/hadoop/hadoop-2.7.7/etc/hadoop/该目录下没有slaves这个文件,需要出创建这个文件--mkdir slaves
[root@Server ~]# cd /usr/local/hadoop/hadoop-2.7.7/etc/hadoop/
[root@Server hadoop]# vim slaves-----添加下面内容
node1
node2
node3
将配置好的hadoop文件整个文件夹分发发到每一个节点上
for i in node{1..3}; do rsync -a --delete /usr/local/hadoop ${i}:/usr/local/ -e ‘ssh‘ & done
启动相应服务:(只在master主服务器上执行)
[root@Server ~]#cd /usr/local/hadoop/hadoop-2.7.7
[root@Server hadoop-2.7.7]# ./bin/hdfs namenode -format-------------------------格式化

出现上面的显示,表示格式化成功
[root@Server hadoop-2.7.7]# ./sbin/start-dfs.sh
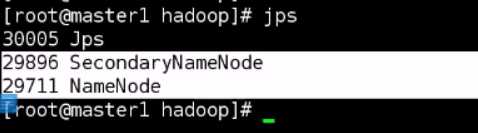
在节点上可以看到
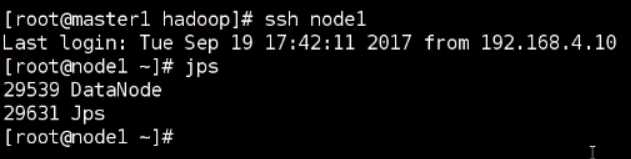
[root@Server hadoop-2.7.7]# ./bin/hdfs dfsadmin -report-------可以看到三个节点的信息
至此hadoop集群配置成功
测试:
HDFS基本使用
[root@Server hadoop-2.7.7]# ./bin/hadoop fs -ls /
[root@Server hadoop-2.7.7]# ./bin/hadoop fs -mkdir /abc
[root@Server hadoop-2.7.7]# ./bin/hadoop fs -put *.txt /abc/-------------------上传文件
[root@Server hadoop-2.7.7]# ./bin/hadoop fs -get /abc/--------------------------下载文件
配置mapred-site.xml文件,参考文档
https://hadoop.apache.org/docs/r2.8.5/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml

[root@Server ~]# vim /usr/local/hadoop/hadoop-2.7.7/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>-------------------------------------------------------------使用yarn管理进群系统
</property>
<property>
<name>mapreduce.jobtracker.http.address</name>
<value>server:50030</value>------------------------------------------------- 设置 jobtracker地址
</property>
</configuration>
配置yarn-site.xml文件,参考手册
https://hadoop.apache.org/docs/r2.8.5/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
[root@Server ~]# vim /usr/local/hadoop/hadoop-2.7.7/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>server</value>----------------------------------------------配置yarn的主机
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
配置好后测试:
进行数据分析



查看分析结果

NFS网关





1、新建一台虚机,命名为nfsgw,将hadoop文件拷贝得到/usr/local/hadoop/
查询这两个软件有没有安装,如果安装了,需要卸载掉
[root@nfsgw hadoop-2.7.7]# rpm -qa | grep nfs
[root@nfsgw hadoop-2.7.7]# rpm -qa | grep rpcbind
2、保证nfsgw网关服务器到每一个节点和主服务器都可以免密登陆
3、配置




3、添加用户
[root@node4 hadoop]# useradd -g 10 nfsuser

4、配置文件
[root@nfsgw hadoop]# vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://server:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/hadoop</value>
</property>
<property>
<name>hadoop.proxyuser.nfsuser.groups</name>----------------用户名:nfsuser,新建的用户是什么就用什么
<value>*</value>---------------------------允许那些用户访问,*表示允许所用用户访问
</property>
<property>
<name>hadoop.proxyuser.nfsuser.hosts</name>----------主机用户名:nfsuser,新建的用户是什么就用什么
<value>*</value>---------------允许那些主机挂载,*表示允许所有主机挂载
</property>
</configuration>
[root@nfsgw hadoop]# vim hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.http-address</name>
<value>server:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>server:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>nfs.exports.allowed.hosts</name>-----------设置那些主机的读写权限
<value>* rw</value> --------------“*” “rw” 表是给所有主机读写权限
</property>
<property>
<name>nfs.namenode.accesstime.precision</name>-------设置访问更新时间
<value>3600000</value>-----1小时
</property>
<property>
<name>nfs.dump.dir</name>----------------设置转储目录
<value>/var/hdfs-nfs</value>
</property>
<property>
<name>nfs.rtmax</name>-----------------设置读取文件的大小
<value>4194304</value>
</property>
<property>
<name>nfs.wtmax</name>-----------------设置写文件的大小
<value>1048576</value>
</property>
<property>
<name>nfs.port.monitoring.disabled</name>-------设置允许没有权限的客户端挂在
<value>true</value>------true是允许。false表示不允许
</property>
</configuration>
[root@nfsgw hadoop]mkdir /var/hdfs-nfs
[root@nfsgw hadoop]# chown nfsuser.10 /var/hdfs-nfs/
[root@nfsgw hadoop]# chmod 755 /var/hdfs-nfs/

5、在主服务器上配置

[root@Server ]#cd /usr/local/hadoop/hadoop-2.7.7/etc/hadoop
[root@Server hadoop]# mkdir nfs.map
[root@Server hadoop]# vim nfs.map
uid 1000 0 # Map the remote UID 1000 to the local UID 0
[root@nfsgw hadoop-2.7.7]# id nfsuser
uid=1000(nfsuser) gid=10(wheel) 组=10(wheel)
[root@Server hadoop-2.7.7]# ./sbin/stop-all.sh
[root@Server hadoop-2.7.7]# ./sbin/start-dfs.sh
[root@Server hadoop-2.7.7]# ./bin/hdfs dfsadmin -report-------------检测节点是否链接成功
[root@Server ~]# adduser -g 10 -u 1000 nfsuser
在nfs服务器上
[root@nfwgw hadoop-2.7.7]# ./sbin/hadoop-daemon.sh --script ./bin/hdfs start portmap-------启动服务
[root@nfsgw hadoop-2.7.7]# netstat -ltunp------------查看111端口是否被监听
启动nfs服务必须切换到nfsuser用户下启动,也就是在core-site.xml配置文件中定义的用户来启动
[root@nfsgw hadoop-2.7.7]# su -l nfsuser
[nfsuser@nfsgw~]$ cd /usr/local/hadoop/hadoop-2.7.7
[nfsuser@nfsgw hadoop-2.7.7]$ ./sbin/hadoop-daemon.sh --script ./bin/hdfs start nfs3

5、到测试机进行挂载
[root@node5 ~]# mount /dev/cdrom /mnt/iso/
[root@node5 ~]# mount -v -t nfs -o vers=3,proto=tcp,nolock,noatime,noacl,sync 192.168.1.14:/ /mnt/test/-------地址为nfs网关服务器地址
6、停止服务
[nfsuser@nfsgw~]$ cd /usr/local/hadoop/hadoop-2.7.7
[nfsuser@nfsgw hadoop-2.7.7]$ ./sbin/hadoop-daemon.sh --script ./bin/hdfs stop nfs3
[root@nfwgw hadoop-2.7.7]# ./sbin/hadoop-daemon.sh --script ./bin/hdfs stop portmap
增加节点node

1、在主节点server上变更配置
[root@Server ~]# vim /usr/local/hadoop/hadoop-2.7.7/etc/hadoop/slaves------添加新增节点名字node5
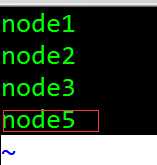
[root@Server ~]# vim /etc/hosts-----------------添加新增节点的主机名
2、到需要新增节点的主机上配置
从主节点上拷贝hadoop(含已配置的文件)文件
[root@node5]# scp -r server:/usr/local/hadoop/ /usr/local/hadoop/
启动服务
[root@node5 hadoop-2.7.7]# ./sbin/hadoop-daemon.sh start datanode
3、到主服务器上配置

[root@Server hadoop-2.7.7]# ./bin/hdfs dfsadmin -report------------------查看新增节点
[root@Server hadoop-2.7.7]# ./bin/hdfs dfsadmin -setBalancerBandwidth 67108864----设置同步带宽为64M
[root@Server hadoop-2.7.7]# ./sbin/start-balancer.sh -threshold 5-----启动5个线程同步数据
删除节点node

在主服务器配置
[root@Server hadoop]# vim hdfs-site.xml-------在该文件中增加一个配置
<property>
<name>dfs.hosts.exclude</name>
<value>/usr/local/hadoop/etc/hadoop/exclude</value>exclude
</property>
保存
[root@Server hadoop]# touch exclude----该文件名exclude需要和<value>/usr/local/hadoop/etc/hadoop/exclude</value>exclude里面的名字一致
[root@Server hadoop]# vim exclude------------添加要删除的节点主机名
node5
[root@Server hadoop-2.7.7]# ./bin/hdfs dfsadmin -refreshNodes---------更新节点数据
[root@Server hadoop-2.7.7]# ./bin/hdfs dfsadmin -report
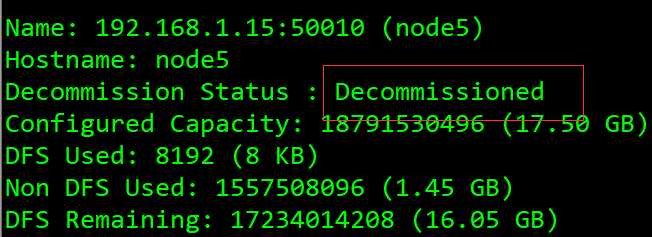
显示红框内容,表示数据已迁移结束,完整的从集群中删除
[root@Server hadoop-2.7.7]# vim etc/hadoop/slaves-------在该文件中删除节点node5
删除exclude文件
[root@Server hadoop]# vim hdfs-site.xml-------删除配置文件中的该内容
<property>
<name>dfs.hosts.exclude</name>
<value>/usr/local/hadoop/etc/hadoop/exclude</value>exclude
</property>
重启namenode服务
[root@Server hadoop-2.7.7]# ./sbin/hadoop-daemon.sh stop namenode
[root@Server hadoop-2.7.7]# ./sbin/hadoop-daemon.sh start namenode
到删除的节点上停止服务
[root@node5 hadoop-2.7.7]# ./sbin/hadoop-daemon.sh stop datanode
修复节点


标签:ups uid star 使用 点数据 nfs服务器 bin ring out
原文地址:https://www.cnblogs.com/scorpios/p/11675044.html