标签:分布式存储 strong 服务 das 有用 row 设置 数据 高级
6.2 二进制数据格式
实现数据的高效二进制格式存储最简单的办法之一,是使用Python内置的pickle序列化。
pandas对象都有一个用于将数据以pickle格式保存到磁盘上的to_pickle方法:
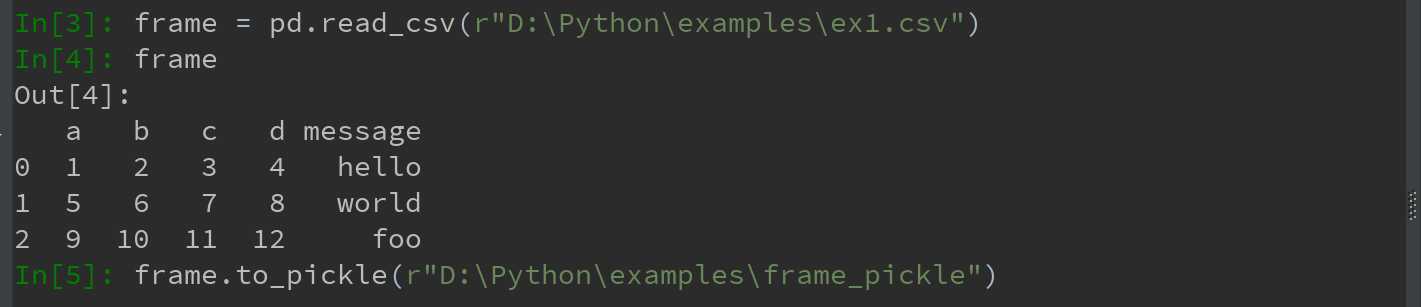
通过pickle直接读取被pickle化的数据,或使用更为方便的pandas.read_pickle:

Ps:pickle仅建议用于短期存储格式。因其很难保证该格式是永远稳定的。
pandas内置支持两个二进制数据格式:HDF5和MessagePack。pandas或Numpy数据的其他存储格式有:
6.2.1 使用HDF5格式
HDF5是一种存储大规模科学数组数据的非常好的文件格式。它可被作为C标准库,带有许多语言的接口,如Java、Python和Matlab等。
HDF5中的HDF指的是层次型数据格式。每个HDF5文件都含有一个文件系统式的节点结构,使得能够存储多个数据集并支持元数据。
相较其他简单格式,HDF5支持多种压缩器的即时压缩,还能更高效地存储重复模式数据。对于非常大地无法直接放入内存的数据,HDF5可以高效地分块读写。
pandas提供地高级接口HDFStore类,可以像字典一样处理低级的细节,可以简化存储Series和DataFrame对象。(此外,也可用PyTables或h5py库直接访问HDF5文件,不如HDFStore高级简便):
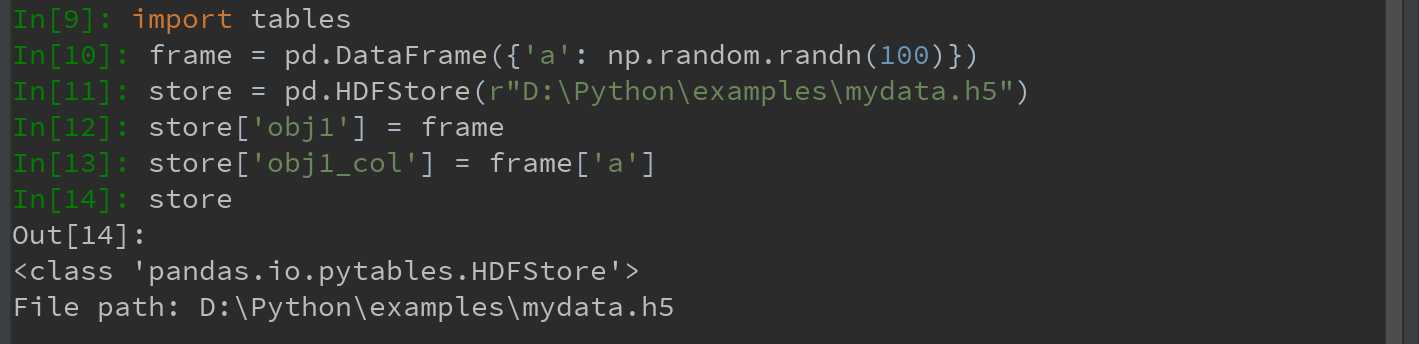
Ps:此处需要先安装tables库
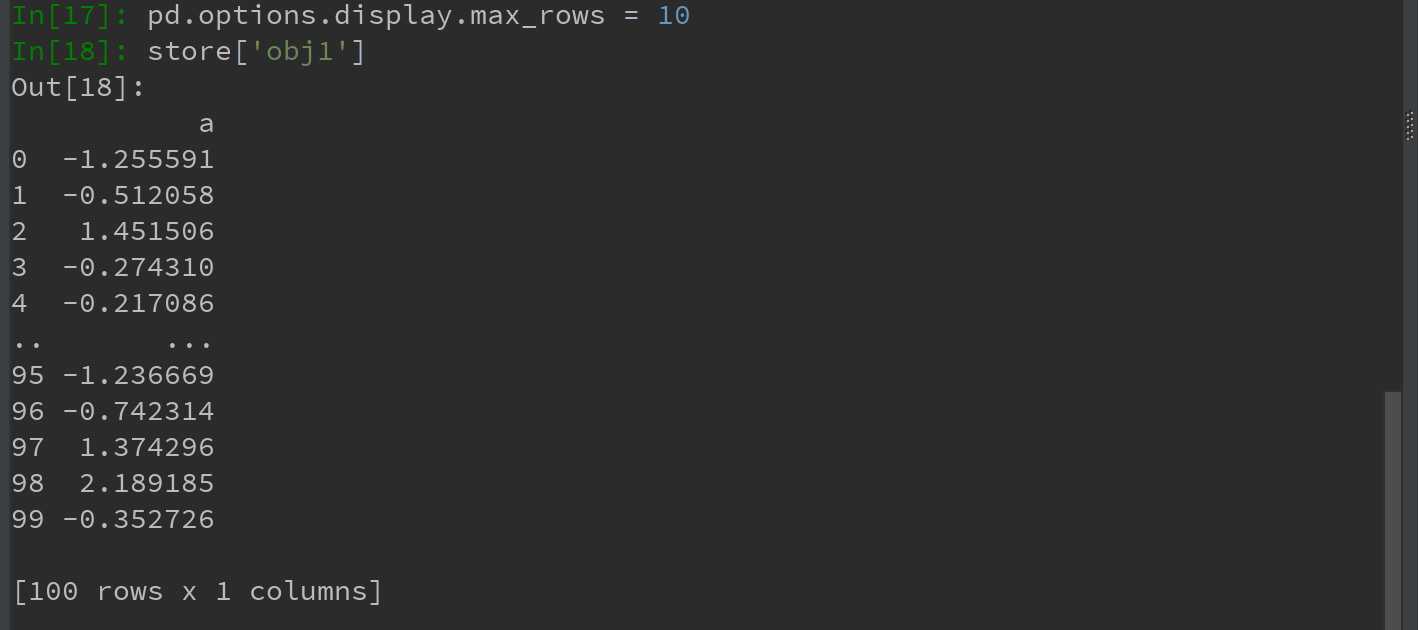
HDF5文件中的对象可以通过与字典一样的API进行获取:
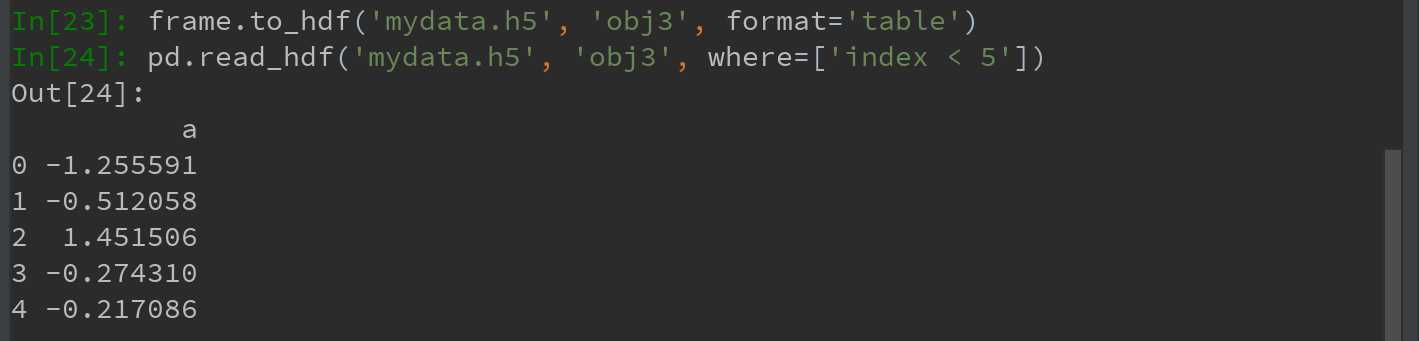
HDFStore支持两种存储模式,‘fixed’和‘table’。后者通常会更慢,但是支持使用特殊语法进行查询操作,如下:
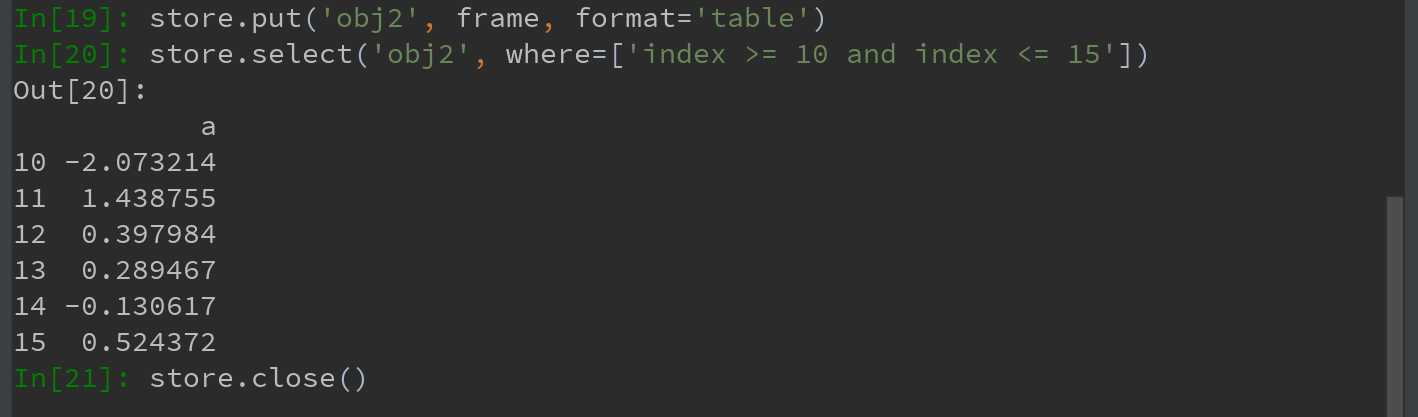
Ps:put是store[‘obj2‘] = frame方法的显示版本,允许设置其他选项,如格式。
pandas.read_hdf函数可以快捷使用这些工具:
注意:如果需要处理的数据位于远程服务器,比如Amazon S3或HDFS,使用专门为分布式存储(比如Apache Parquet)的二进制格式也许更加合适。
如需要本地处理海量数据,需好好研究PyTables和h5py。由于许多数据分析问题都是IO密集型(非CPU密集型),利用HDF5这类工具能显著提升应用程序的效率。(HDF5不是数据库,是最适合用作“一次写多次读”的数据集)
6.2.2 读取Microsoft Excel文件
6.3 Web APIs交互
6.4 数据库交互
6.5 总结
访问数据通常是数据分析的第一步。本章已经介绍学习了一些有用的工具,接下来的章节中,将深入研究数据规整、数据可视化、时间序列分析和其他主题。
利用Python进行数据分析 第6章 数据加载、存储与文件格式(2)
标签:分布式存储 strong 服务 das 有用 row 设置 数据 高级
原文地址:https://www.cnblogs.com/ElonJiang/p/11730159.html