标签:获取 import tps print 效果 class 需要 code 调用
学习爬虫之路,必经的一个小项目就是爬取豆瓣的TOP250了,首先我们进入TOP250的界面看看。
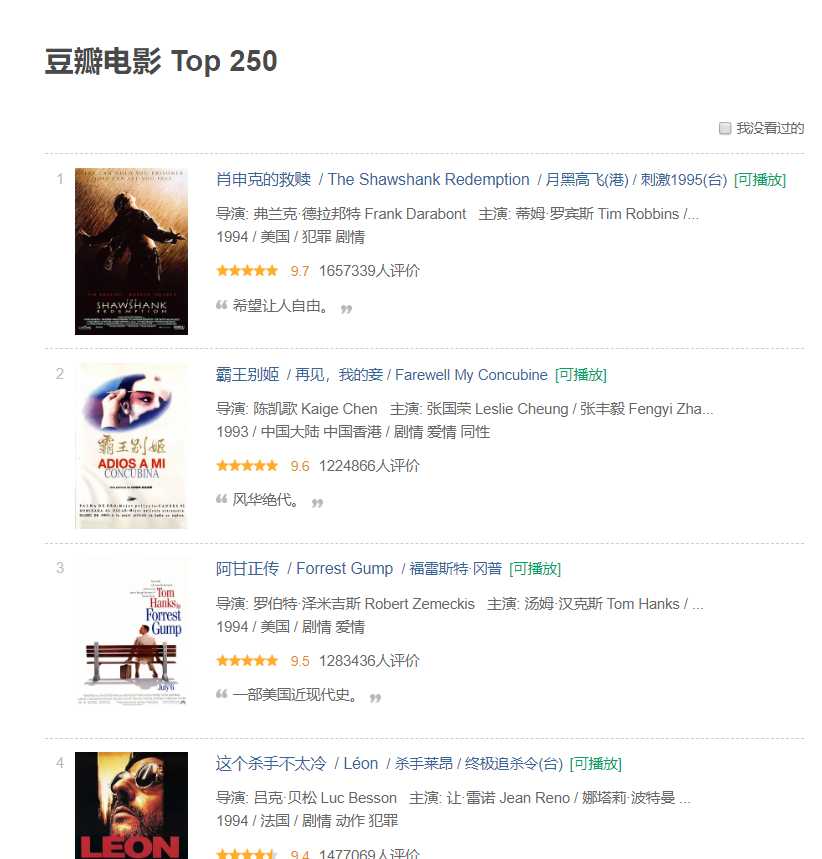
可以看到每部电影都有比较全面的简介。其中包括电影名、导演、评分等。
接下来,我们就爬取这些数据,并将这些数据制成EXCEL表格方便查看。
首先,我们用requests库请求一下该网页,并返回他的text格式。
请求并返回成功!
接下来,我们提取我们所需要的网页元素。
点击“肖申克救赎”的检查元素。
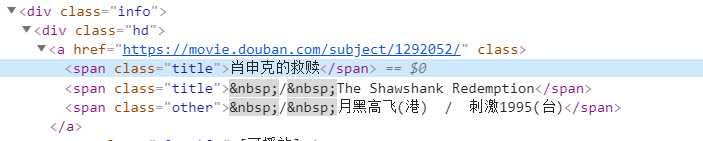
发现它在div class = "hd" -> span class = "title"里,所以我们import beautifulsoup,来定位该元素。
同时,用相同的方法定位电影的评价人数和评分以及短评。
代码如下:
soup = BeautifulSoup(res.text, ‘html.parser‘) names = [] scores = [] comments = [] result = [] #获取电影的所有名字 res_name = soup.find_all(‘div‘,class_="hd") for i in res_name: a=i.a.span.text names.append(a) #获取电影的评分 res_scores = soup.find_all(‘span‘,class_=‘rating_num‘) for i in res_scores: a=i.get_text() scores.append(a) #获取电影的短评 ol = soup.find(‘ol‘, class_=‘grid_view‘) for i in ol.find_all(‘li‘): info = i.find(‘span‘, attrs={‘class‘: ‘inq‘}) # 短评 if info: comments.append(info.get_text()) else: comments.append("无") return names,scores,comments
Ok,现在,我们所需要的数据都存在三个列表里面,names,scores,comments。
我们将这三个列表存入EXCEL文件里,方便查看。
调用WorkBook方法
wb = Workbook() filename = ‘top250.xlsx‘ ws1 = wb.active ws1.title = ‘TOP250‘ for (i, m, o) in zip(names,scores,comments): col_A = ‘A%s‘ % (names.index(i) + 1) col_B = ‘B%s‘ % (names.index(i) + 1) col_C = ‘C%s‘ % (names.index(i) + 1) ws1[col_A] = i ws1[col_B] = m ws1[col_C] = o wb.save(filename=filename)
运行结束后,会生成一个.xlsx的文件,我们来看看效果:
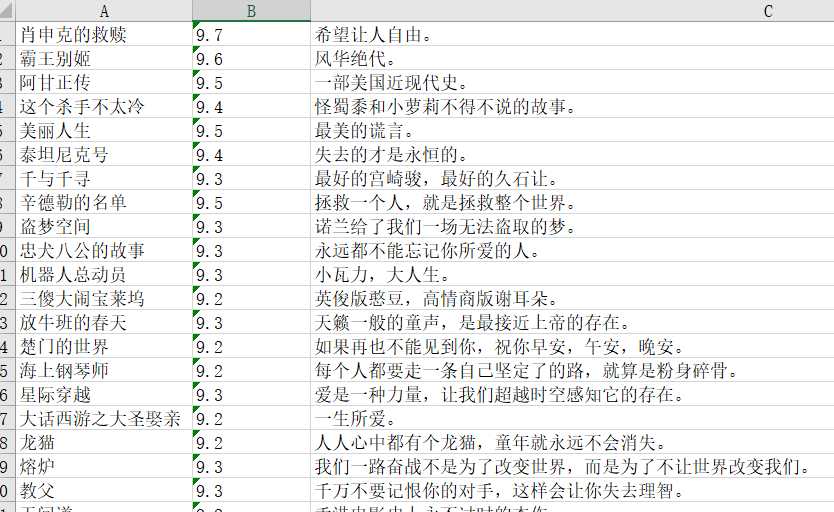
Very Beatuful! 以后想学习之余想放松一下看看好的电影,就可以在上面直接查找啦。
以下是我的源代码:
import requests from bs4 import BeautifulSoup from openpyxl import Workbook def open_url(url): res = requests.get(url) return res def get_movie(res): soup = BeautifulSoup(res.text, ‘html.parser‘) names = [] scores = [] comments = [] result = [] #获取电影的所有名字 res_name = soup.find_all(‘div‘,class_="hd") for i in res_name: a=i.a.span.text names.append(a) #获取电影的评分 res_scores = soup.find_all(‘span‘,class_=‘rating_num‘) for i in res_scores: a=i.get_text() scores.append(a) #获取电影的短评 ol = soup.find(‘ol‘, class_=‘grid_view‘) for i in ol.find_all(‘li‘): info = i.find(‘span‘, attrs={‘class‘: ‘inq‘}) # 短评 if info: comments.append(info.get_text()) else: comments.append("无") return names,scores,comments def get_page(res): soup = BeautifulSoup(res.text,‘html.parser‘) #获取页数 page_num = soup.find(‘span‘,class_ =‘next‘).previous_sibling.previous_sibling.text return int(page_num) def main(): host = ‘https://movie.douban.com/top250‘ res = open_url(host) pages = get_page(res) #print(pages) names =[] scores = [] comments = [] for i in range(pages): url = host + ‘?start=‘+ str(25*i)+‘&filter=‘ #print(url) result = open_url(url) #print(result) a,b,c = get_movie(result) #print(a,b,c) names.extend(a) scores.extend(b) comments.extend(c) # print(names) # print(scores) # print(comments) wb = Workbook() filename = ‘top250.xlsx‘ ws1 = wb.active ws1.title = ‘TOP250‘ for (i, m, o) in zip(names,scores,comments): col_A = ‘A%s‘ % (names.index(i) + 1) col_B = ‘B%s‘ % (names.index(i) + 1) col_C = ‘C%s‘ % (names.index(i) + 1) ws1[col_A] = i ws1[col_B] = m ws1[col_C] = o wb.save(filename=filename) if __name__ == ‘__main__‘: main()
生成EXCEL文件还有很多种方法,下次分享Pandas生成EXCEL文件的方法~
标签:获取 import tps print 效果 class 需要 code 调用
原文地址:https://www.cnblogs.com/lesliechan/p/11739897.html