标签:block == alt 核心 incr lock 位长 区间 其它
Twitter 早期用 MySQL 存储数据,随着用户的增长,单一的 MySQL 实例没法承受海量的数据,后来团队就研究如何产生完美的自增ID,以满足两个基本的要求:
每秒能生成几十万条 ID 用于标识不同的 记录;
这些 ID 应该可以有个大致的顺序,也就是说发布时间相近的两条记录,它们的 ID也应当相近,这样才能方便各种客户端对记录 进行排序。
Twitter-Snowflake算法就是在这样的背景下产生的。
Twitter 解决这两个问题的方案非常简单高效:每一个 ID 都是 64 位数字,由时间戳、工作机器节点和序列号组成, ID是由当前所在的机器节点生成的。如图:
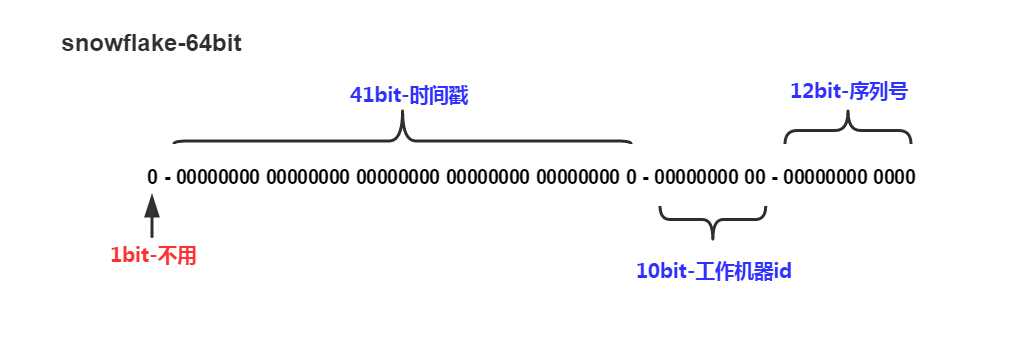
下面先说明一下各个区间的作用。
符号位:用于区分正负数。1为负数,0为整数。一般不需要负数,所以值固定为0。
时间戳:一共预留41bit保存毫秒级时间戳。因为毫秒级时间戳长度是13位:41位二进制最大值(T)是:$2^{41}-1 = 2199023255551 $ , 刚好13位。可以表示的年份 = T / (3600 * 24 * 365 * 1000) = 69.7年。换算成Unix时间也就是可以表示到:2039-09-07 23:47:35:

大家会觉得这个时间不够用啊,没关系,后面会讲如何优化。
工作机器:预留了10bit保存机器ID。只要机器ID不一样,每毫秒生成的ID是不一样的。一共可以支持多少台机器同时生成ID呢? 答案是 1023 台(\(2^{10}-1\))。
如果工作机器比较少,可以使用配置文件来设置这个id,或者使用随机数。如果机器过多就得单独实现一共工作机器ID分配器了,比如使用redis自增,或者利用Mysql auto_increment机制也可以达到效果。
序列号:序列号一共是12bit,为了处理在同一机器同一毫秒内需要给多条消息分配id的情况,一共可以产生4095个序列号(0~4095, \(2^{12}-1\))。
综上:同一台机器1毫秒内可产生4095个ID,全部机器1毫秒内可产生 4095 * 1023 个ID。由于全是在各个机器本地生成,效率非常高。
下面是一个简单实现:仅有时间戳,机器位为0,序列号为0:
#include <stdio.h>
int main()
{
long long id;
id = 1572057648000 << 22; //相当于 id = 1572057648000 << 22 | 0 << 12 | 0;
printf("id=%lld\n", id);
return 0;
}输出:
id=6593687681236992000代码实现主要用到了左移和或位运算(或运算),各个语言类似。上面的实现输出的结果是一个19位长度的整数。
1、时间戳优化
如果时间戳取当前毫秒级时间戳,那么只能表示到2039年,远远不够。我们发现,1970到当前时间这个区间其实是永远都不会用了,那么,为何不使用偏移量呢?也就是时间戳部分不直接取当前毫秒级时间戳,而是在此基础上减去一个过去时间:
id = (1572057648000 - 1569859200000) << 22; 输出:
id=9220959240192000上面代码中,第一个时间戳是当前毫秒级时间戳,第二个则是一个过去时间戳(1569859200000表示2019-10-01 00:00:00)。这样我们可以表示的年大概是 当前年份(例如2019) + 69 = 2088 年,很长一段时间内都够用。
2、序列号
序列号默认取0,如果已经使用了则自增。若自增到4096,也就是同一毫秒内的序列号用完了,怎么办呢?需要等待至下一毫秒。部分代码示例:
//同一毫秒并发调用
if (ts == (iw.last_time_stamp)) {
//序列号自增
iw.sequence = (iw.sequence+1) & MASK_SEQUENCE;
//序列号自增到最大值4096,4095 & 4096 = 0
if (iw.sequence == 0) {
//等待至下一毫秒
ts = time_re_gen(ts);
}
} else { //同一毫秒没有重复的
iw.last_time_stamp = ts;
}1、53bits版本:因为js只支持53位bit的数值
* 0 32 51 53
+-----------+------+------+
|0|time(32) |workid(8) |seq(12) |
+-----------+------+------+2、其它版本
我们也可以根据自己的业务需求,将不同区间的bit位进行调整。机器位和序列号ID并不是必须的,可以合并。或者拆分出更多的区间表示更多的意义。例如订单号:
* 0 41 47 59 64
+-----------+------+------+------+------+
|0|time(41) |workid(6) |seq(12) | uid(4)
+-----------+------+------+------+------+我们对订单分16个(2^4)表,每次将 uid & 0xF(也就是 uid & 15)的结果放到后四位,这样以后根据uid查订单的时候,uid mod 16 就能得到数据在哪个分表;同时根据订单ID本身也能找到对应的分表。示例:
php > echo 1572070381000 << 22 | 1 << 16 | 0 << 4 | (1820 & 15);
6593741087309889548
php > echo 1572070381000 << 22 | 1 << 16 | 0 << 4 | (5177331 & 15);
6593741087309889539验证测试:
php > echo 1572070381000 << 22 | 1 << 16 | 0 << 4 | (5177331 & 15);
6593741087309889539
php > echo 6593741087309889548 % 16;
12
php > echo 1820 % 16;
12
php > echo 6593741087309889539 % 16;
3
php > echo 5177331 % 16;
3从上面的结果可以看出来,uid、订单号都能定位到相同的分表。
对一个2的n次幂的数num取模(2^n),本质就是num对应二进制的末尾n个bit的和取模。
参考网上其它语言的版本,自己写了C和PHP版本的:
github上其它版本:
go语言版本:已用于生产环境,稳定
https://github.com/bwmarrin/snowflake
php c扩展版:未使用过
fgy58963/php_snowflake: 推特分布式主键生成算法的php扩展
https://github.com/fgy58963/php_snowflake
1、Twitter-Snowflake,64位自增ID算法详解 - 漫漫路
https://www.lanindex.com/twitter-snowflake%EF%BC%8C64%E4%BD%8D%E8%87%AA%E5%A2%9Eid%E7%AE%97%E6%B3%95%E8%AF%A6%E8%A7%A3/
2、多key业务,数据库水平切分架构一次搞定
https://mp.weixin.qq.com/s/PCzRAZa9n4aJwHOX-kAhtA
标签:block == alt 核心 incr lock 位长 区间 其它
原文地址:https://www.cnblogs.com/52fhy/p/11743413.html