标签:全局 改变 end 方法 图片 nta 变量 fence contain
python 中的垃圾回收机制主要采用引用计数的方式来跟踪和回收垃圾;
from sys import getrefcount
a = [1, 2, 3]
b = a
c = [4, a]
?
del b
# 相当于给a的引用计数-1
c.remove(a)
# del a
# 只是让a的引用计数为0,并没有删除[1, 2, 3]这块内存空间(内存的删除是由底层c语言实现的)
?
# print(getrefcount(a)) # 这里a当作参数,也是一次引用
# 引用计数增加的情况
# 赋值
# 引用
# 当成函数参数传递给函数
?
# 引用被显性或者隐性的删除
# 函数结束的时候里面参数的引用计数会减一
?
# 当这个对象的引用计数为0的时候 我们就认为它是垃圾可以被回收
优点:1. 简单 2. 实时性 缺点:1. 维护引用计数消耗资源 2. 循环引用
光使用引用技术解决不了容器对象可能产生的循环引用问题. 例如:
a = [1,2,3,4]
b = [5,6,7]
a.append(b)
b.append(a) # a, b循环引用
?
print(getrefcount(a))
print(getrefcount(b))
所以,python 在引用计数的基础上,使用标记清除来解决循环引用的问题:
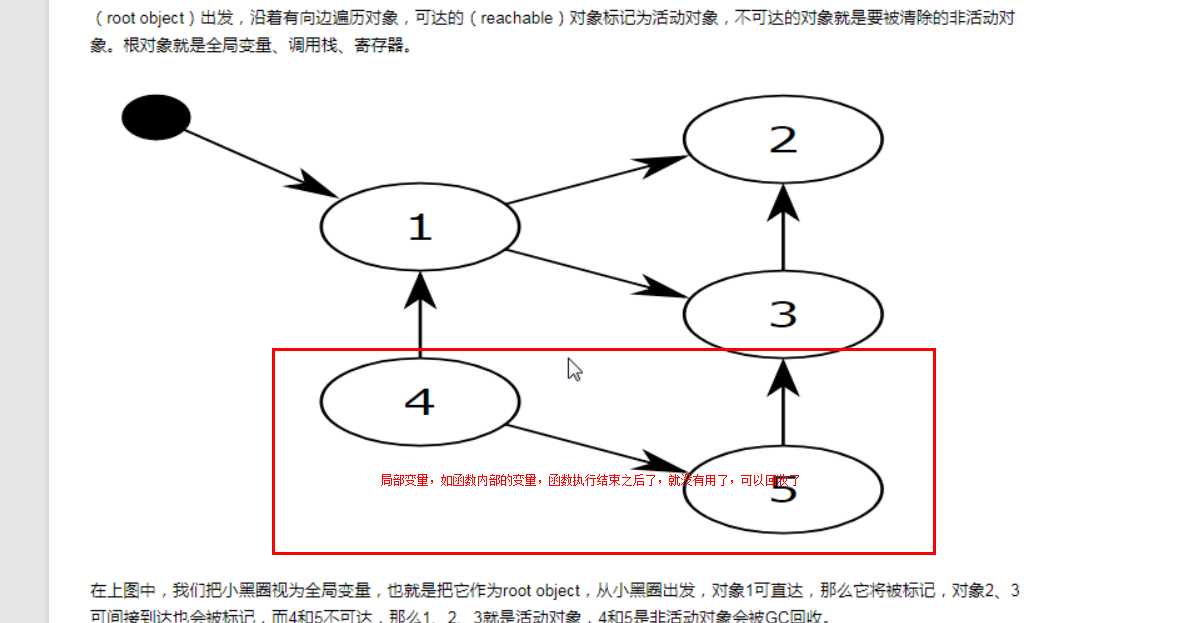
以全局变量出发, 可以找到所有可达对象,所有不可达对象就是垃圾,只要是可达对象,就不会被回收;
局部变量,如在函数内部,只有在函数执行过程中才会创建内存,函数执行完之后就可以回收了;
缺点:效率问题,每次都要遍历所有的对象,效率很慢
‘分代回收‘以空间换时间的方法提高垃圾回收效率。 在内存中存活时间越长 越不可能是垃圾;
一共有 3 代:
0 代 最年轻的一代 当 0 代对象达到一个标准的时候我们就去触发垃圾回收,从而触发引用计数,在去做标记清除; 然后把存活的 0 代放入 1 代,当我们 0 代触发 10 次的时候 就触发 1 代的回收; 1 代经过被回收之后,存活的对象放入 2 代,当 1 代触发 10 次 触发 2 代回收 (本次就要遍历剩下所有的 2 代,标记清除了);
这个标准就是:
import gc
print(gc.get_threshold()) # (700, 10, 10)
这个 (700, 10, 10) 代表这个标准,都是可以改变的,其中 700 代表 调用 c 接口开辟内存跟销毁内存的次数差值,10 分别代表 0 代触发 10 次回收 1 代和 1 代触发 10 次回收 2 代。
补充:
python 中对于操作内存分为 2 大块:
python 自己维护内存池 (小数据池就是在这个空间中)
调用 c 的接口 去开辟内存空间
总结:
引用计数
Python 为每个对象维护一个引用计数
当引用计数为 0 的 代表这个对象为垃圾
标记清除
解决孤立的循环引用
标记根节点和可达对象
不可达视为垃圾
分代回收
解决标记清除的效率问题
0 代 1 代 2 代
阈值 (700,10,10)
当调用 c 的接口开辟内存和销毁内存的差值为 700 的时候出发 0 代回收
0 代触发 10 次 触发 1 代回收
1 代触发 10 次 触发 2 代回收
每次回收结束 没有被回收的对象放入下一代
标签:全局 改变 end 方法 图片 nta 变量 fence contain
原文地址:https://www.cnblogs.com/kali404/p/11745133.html